 1068
1068 
Содержание
Сегодня заглянем под капот Tanzu Greenplum Text: архитектура и принципы работы этого средства поиска и анализа текстов, интегрированного с популярной MPP-СУБД. Как движок наподобие Elasticsearch связывает кластер Apache Solr с базой данных Greenplum и зачем здесь нужен Zookeeper.
Что такое Tanzu Greenplum Text
Мы уже рассказывали про основные функциональные возможности Tanzu Greenplum Text (TGT) – движок полнотекстового поиска, который объединяет сервер MPP-СУД Greenplum с корпоративным поиском Apache SolrCloud. Tanzu Greenplum Text поддерживает работу со множеством источников, позволяя индексировать документы в Greenplum или полученные из внешних хранилищ, таких как HTTP- или FTP-серверы, Amazon S3 и другие совместимые с ним хранилища, а также Hadoop HDFS.
Сегменты базы данных Greenplum и узлы TGT могут быть развернуты на одних и тех же или на разных хостах с сетевым подключением. Служба Apache ZooKeeper управляет кластером SolrCloud, причем узлы ZooKeeper могут быть развернуты не на всех хостах. Пользователи базы данных Greenplum получают доступ к службам SolrCloud через определяемые пользователем функции TGT, установленные в MPP-СУБД, и утилиты командной строки.
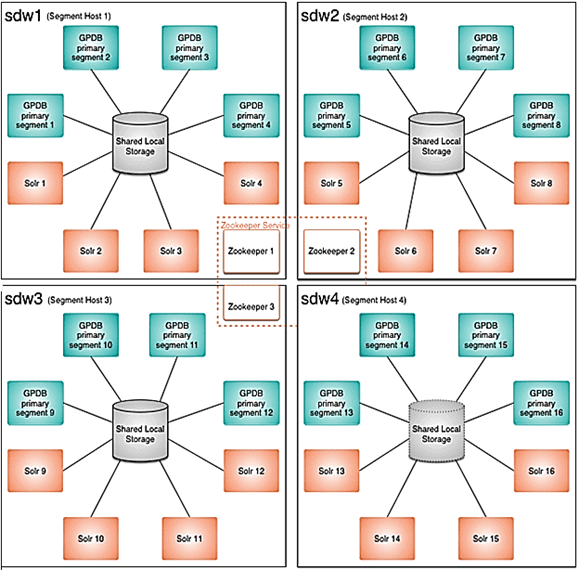
Сегменты Greenplum, экземпляры Solr и узлы ZooKeeper могут быть развернуты на отдельных хостах в одной сети в зависимости от требований к приложениям и производительности. Далее рассмотрим, каким образом TGT связывает SolrCloud с Greenplum, а также как два кластера работают вместе, чтобы обеспечить возможности параллельного текстового поиска в MPP-СУБД и поддерживать высокую доступность.
Apache Solr для Greenplum: принципы работы
Напомним, кластер базы Greenplum состоит из следующих компонентов:
- экземпляр основной базы данных, работающий на выделенном хосте (mdw);
- вторичный главный экземпляр на хосте (smdw) в качестве горячего резерва для главного экземпляра;
- массив экземпляров основного сегмента базы данных и зеркал, развернутых на узлах сегмента, по соглашению от sdw1 до sdwn;
- экземпляр сегмента — это независимый сервер базы данных PostgreSQL, управляющий частью распределенных данных. У каждого сегмента есть зеркало на другом хосте в кластере для обеспечения бесперебойного обслуживания в случае отказа сегмента или хоста сегмента. Количество первичных сегментов на хост определяется конфигурацией оборудования — количеством и типом процессорных ядер, объемом физической оперативной памяти, емкостью локального хранилища и пропускной способностью сети, а также требованиями к доступности и производительности.
- Мастер-экземпляр базы данных Greenplum, в котором не хранятся пользовательские данные, координирует работу экземпляров сегментов. Пользователи базы данных входят в главный экземпляр и отправляют запросы SQL. Главный экземпляр создает план выполнения запроса, распределяет работу по сегментам, собирает и возвращает результаты пользователю.
Apache Solr обеспечивает доступ к полнотекстовым индексам open-source библиотеки Lucene. Apache SolrCloud — это высокодоступный, отказоустойчивый кластер серверов Solr. Кластер SolrCloud состоит из следующих компонентов:
- Кластер Apache ZooKeeper для управления кластером SolrCloud, включая управление конфигурациями серверов и индексов, а также координацию действий кластера. Для TGT может развернуть собственный кластер ZooKeeper или использовать существующий. Кластер ZooKeeper можно развернуть на хостах кластера Greenplum или на отдельных хостах, доступных для MPP-СУБД. Второй вариант дает более высокую производительность.
- Несколько экземпляров сервера SolrCloud, развернутых на узлах сегмента Greenplum или на других узлах в той же сети. Каждый экземпляр представляет собой процесс JVM, на котором работает сервер Solr. Экземпляры SolrCloud используют локальное хранилище, которое может быть тем же локальным хранилищем, в котором хранятся данные Greenplum. Количество экземпляров SolrCloud на хост может совпадать с количеством первичных сегментов Greenplum на хост. Количество экземпляров для выполнения на хосте указывается во время установки Tanzu Greenplum Text.
TGT предоставляет возможности индексирования документов и поиска для базы данных Greenplum с помощью определяемых пользователем функций (UDF), которые получают доступ к Solr API из SQL-запросов. Пользовательские функции Tanzu Greenplum Text позволяют создавать и управлять текстовыми индексами, предоставляют информацию об их состоянии и вставляют документы в индексы из таблиц базы данных или внешних документов вне MPP-СУБД. Еще есть пользовательские функции TGT и утилиты командной строки для настройки, мониторинга и управления кластером SolrCloud, а также для управления репликами — механизмом высокой доступности SolrCloud.
SolrCloud распределяет индексы документов по фрагментам, называемым шардами (shard). Каждый шард управляется экземпляром SolrCloud, а ZooKeeper обеспечивает равномерное распределение шардов между экземплярами SolrCloud. Экземпляры SolrCloud и сегменты Greenplum не обязательно должны находиться на одних и тех же хостах.
В TGT количество шардов для индекса по умолчанию равно количеству сегментов базы данных Greenplum, поэтому каждый сегмент работает с равной частью индекса. При необходимости можно указать меньшее количество сегментов при создании текстового индекса Tanzu Greenplum, что позволяет масштабировать рабочие нагрузки индексирования согласно требованиям к производительности и использованию ресурсов.
SolrCloud обеспечивает высокую доступность, поддерживая реплики шардов и обеспечивая автоматический переход на другой ресурс в случае сбоя шарда или его недоступности. Одна реплика каждого шарда сегмента является ведущей, и любые изменения в ней применяются к другим репликам. Коэффициент репликации, который определяет количество поддерживаемых реплик для каждого шарда, задается при создании индекса. Реплики также могут быть добавлены или удалены позже с помощью пользовательских функций TGT или утилит командной строки.
ZooKeeper определяет расположение реплик сегментов среди узлов и хостов Solr. При добавлении реплики с помощью Tanzu Greenplum Text функции UDF или утилиты командной строки новый сегмент может быть явно размещен в экземпляре SolrCloud.
Поскольку TGT работает с базой данных Greenplum и Apache SolrCloud для хранения и индексирования больших данных в целях поиска информации через SQL-запросы, его рабочие процессы включают загрузку и индексирование данных. Как это реализуется, рассмотрим далее.
Процесс загрузки и индексирования данных
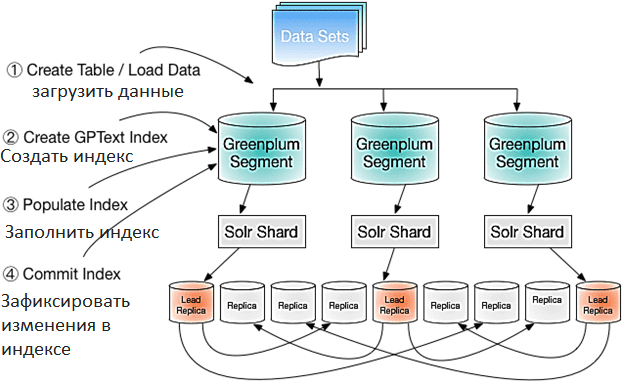
Все взаимодействие клиента с системой осуществляется через главный экземпляр Greenplum и может быть представлено последовательностью шагов:
- загрузить данные в СУБД Greenplum, создав таблицу в базе данных. MPP-СУБД предоставляет утилиты и протоколы для параллельной загрузки данных, которые помогают преобразовывать и загружать внешние данные в различных форматах и из различных источников. Также можно создать внешний индекс для документов, извлекаемых с веб- или FTP-сервера, Amazon S3 или другого хранилища, совместимого с S3, или Hadoop.
- Создать и настроить пустой индекс TGT, используя UDF-функцию create_index(), чтобы создать пустой текстовый индекс для таблицы базы данных. TGText хранит файлы конфигурации для индекса в ZooKeeper.
- Настроить индекс, отредактировав файлы конфигурации индекса с помощью утилиты командной строки gptext-config. Можно настроить способ разметки, фильтрации и преобразования текста документа перед сохранением в индексе, а также способ подготовки текста запроса для поиска в индексе.
- Заполнить индекс данными из таблицы базы данных или внешнего источника данных, используя UDF-функцию index() или gptext.index_external() для добавления данных в индекс. Эти пользовательские функции работают, отправляя SQL-запросы для выполнения в каждом сегменте Greenplum. Сегменты выполняют запросы и добавляют результаты в индекс с помощью API Solr.
- Зафиксировать изменения в индексе с помощью UDF-функции commit_index(). Пока изменения не будут зафиксированы, запросы, выполняемые в индексе, не могут получить доступ к каким-либо данным, добавленным в индекс с помощью gptext.index(). При необходимости незафиксированные изменения можно отменить. SolrCloud реплицирует изменения, зафиксированные в ведущей реплике, на неведущие реплики сегментов.
Процесс запроса данных
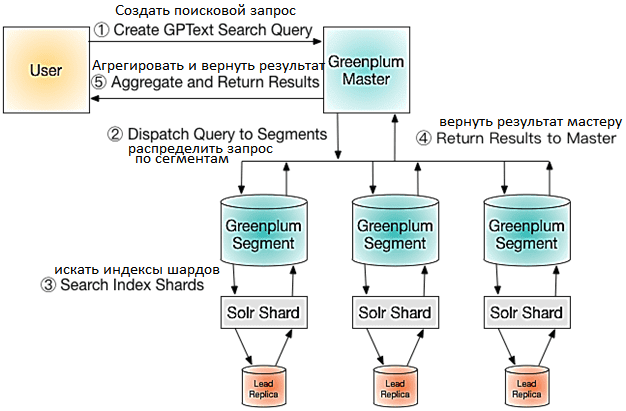
Запросы к Tanzu Greenplum Text выполняются следующим образом:
- Пользователь для поиска проиндексированных данных в TGT отправляет SQL-запрос как команду выборки SELECT в UDF-функции Tanzu Greenplum Text, которая содержит выражения полнотекстового поиска.
- Мастер Greenplum отправляет запрос в сегменты базы данных.
- Каждый сегмент выполняет запрос, используя Solr API для поиска в индексе шарда. Solr анализирует и выполняет поисковый запрос на ведущей реплике для шарда.
- Сегменты базы данных Greenplum возвращают результаты поискового запроса мастеру базы данных .
- Мастер базы данных Greenplum объединяет результаты всех сегментов и возвращает их клиенту.
Освойте администрирование и эксплуатацию Greenplum и Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Greenplum для инженеров данных
- Greenplum для инженеров данных
- Администрирование Greenplum / Arenadata DB
- Интеграция Hadoop и NoSQL
Источники

