
Как снизить затраты на AWS EMR, сохранив эффективность Spark-конвейеров обработки данных на спотовых инстансах и других типах узлов облачного кластера. Также рассмотрим, что такое прерываемые виртуальные машины в Яндекс.Облаке и каким образом настроить такую облачную инфраструктуру, чтобы сократить затраты на выполнение Spark-приложений, одновременно повысив их отказоустойчивость.
Блеск и нищета спотовых инстансов в облачной инфраструктуре для Apache Spark
При использовании Apache Spark в облачной инфраструктуре для конвейеров обработки данных важно контролировать и оптимизировать настройку кластеров, чтобы избежать увеличения затрат по мере роста бизнеса. Здесь пригодятся так называемые спотовые инстансы – экземпляры, которые в настоящее время не используются другими клиентами, поэтому они предлагаются по более низкой цене. Такой прием характерен не только для AWS: например, подобное решение есть и в Яндекс.Облаке – прерываемые виртуальные машины, на которые не распространяется соглашение об уровне обслуживания (SLA). Они могут быть принудительно остановлены в любой момент, хотя вероятность такой остановки невелика, может меняться со временем и различаться в разных зонах доступности облачной платформы. Тем не менее, прерываемые виртуальные машины – отличный вариант сэкономить на Kubernetes-проектах, Hadoop-приложениях и пакетных ETL-операций. Все это также справедливо для AWS, о чем мы уже рассказывали здесь.
Согласно документации AWS, спотовые инстансы имеют скидку до 90 % по сравнению с инстансами по требованию. Но эта сниженная цена имеет несколько ограничений:
- спотовые инстансы могут быть отозваны AWS в любое время с уведомлением за 2 минуты. AWS обычно возвращает эти экземпляры, когда нужно предоставить ресурсы по запросу другим клиентам;
- отсутствие полного представления о настройке производительности заданий, поскольку типы экземпляров различаются между каждым запуском, становится сложнее сравнивать только продолжительность заданий;
- существуют дополнительные затраты на разработку и обслуживание, которые трудно измерить при использовании спотовых инстансов.
При использовании AWS EMR ценообразование состоит из двух компонентов:
- агент EMR, стоимость которого не зависит от количества исполнителей на машину;
- базовая инфраструктура EC2.
Не рекомендуется ставить все свои рабочие процессы на один тип экземпляра, потому что он может исчерпать свою емкость и перезапуститься. Чтобы смягчить эту проблему, AWS позволяет разнообразить типы инстансов, что позволяет вернуться к другим типам экземпляров в случае отказа. В работе с Apache Spark диверсификация не так сложна: при проектировании задания из-за парадигмы выполнения нужно только указать количество исполнителей и ресурсы для каждого исполнителя, включая память и виртуальный ЦП. Далее следует выбрать экземпляры для кластера. Чтобы повысить эффективность использования ресурсов, ищутся только экземпляры с одинаковым соотношением памяти на виртуальный ЦП.
Распространенной ошибкой может быть использование типов экземпляров из одного семейства, поскольку виртуальные ЦП, память и стоимость обычно растут линейно с размером машины. Однако, стратегия диверсификации также должна включать несколько семейств экземпляров. Если возникает проблема с оборудованием, это может повлиять на все экземпляры из одного семейства. Например, если проблема с оборудованием возникает на инстансах r5, это может повлиять на все инстансы r5.8x, r5.4x и т. д.
Таким образом, выбор экземпляров зависит от различных факторов:
- аппаратное обеспечение экземпляра,
- скорость восстановления,
- стоимость.
Проще всего начать с выбора на основе спецификаций подходящего оборудования. Например, в AWS для этого есть специальный инструмент командной строки под названием Amazon EC2 Instance Selector.
Итак, Spark-приложения запускаются в облачных кластерах, содержащих несколько типичных компонентов:
- служба диспетчера кластера, например, YARN, отвечает за получение ресурсов в кластере;
- на узле драйвера выполняется функция main() задания Spark и создается контекст приложения;
- рабочие узлы могут запускать код приложения и они отвечают за выполнение задач Spark.
Основным недостатком спотовых инстансов является отказ, который может произойти в любое время на этих инстансах. При том, кластер в целом отказоустойчив, он не может выдержать отказ узла драйвера или работающего узла диспетчера кластера. Как справиться с этой проблемой, мы рассмотрим далее.
Как настроить облачный кластер, повысив отказоустойчивость и снизив затраты
При запуске кластера EMR выделяются 3 основные категории узлов:
- главный экземпляр – имеет только 1 узел, где установлен менеджер кластера, работает мастер приложений YARN (Application Manager) и планировщик;
- основные экземпляры (Core);
- экземпляры задач (Task).
На инстансах Core и Task работает Spark-приложение. По умолчанию в AWS EMR 6.X узлы Spark Driver и Executor могут работать либо в узле Core, либо в узле Task. Это приводит к проблеме, если драйвер Spark работает на восстановленном узле: это еще одна точка отказа для выполнения задания. Кроме того, если исполнитель выполняется на восстановленном узле, Spark достаточно отказоустойчив, чтобы повторно обрабатывать только подмножество работы, потерянной из-за сбоя, без остановки задания.
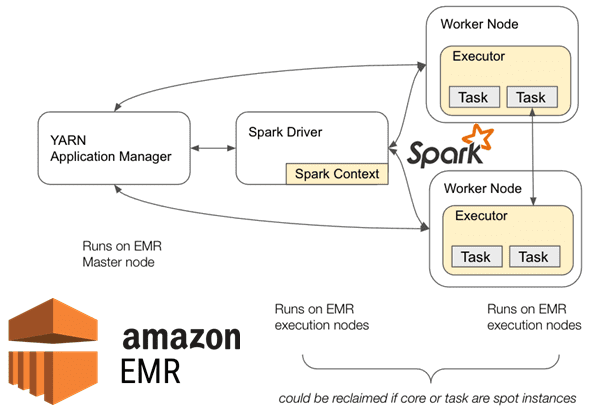
Поэтому EMR предлагает использовать функцию маркировки узлов YARN, чтобы предотвратить сбои заданий из-за точечных отказов и заставить драйвер Spark работать только на узлах Core, чтобы эти спотовые инстансы вели себя аналогично как экземплярам «по требованию». Таким образом, конфигурация облачного кластера будет следующей:
- главный узел – по требованию (On Demand) или зарезервированный (Reserved) с небольшим экземпляром;
- основные узлы – по требованию или зарезервированы для запуска драйверов Spark. Остальные ресурсы затем используются для выполнения задач исполнителей.
- узлы задач – спотовые экземпляры, которые будут запускать только задачи исполнителей Spark.
В результате количество экземпляров On Demand или Reserved ограничивается только критическими компонентами, такими как YARN Master и Spark Driver, выполняя отказоустойчивые компоненты на спотовые инстансы. Примечательно, что сам фреймворк, начиная с версии 3.1.X, доступной в EMR 6.3, стал более отказоустойчивым и включает несколько функций для уменьшения потери исполнителей, которые можно настроить после установки параметра конфигурации spark.decommission.enabled. Это относится к функции вывода узла из эксплуатации, которая позволяет включать блоки и выполнять миграцию данных в случайном порядке до того, как спотовый узел исчезнет.
Если для параметра spark.decommission.enabled установлено значение True, вычислительный движок сделает все возможное, чтобы корректно завершить работу исполнителя и перенести находящиеся на нем данные. Spark попытается перенести все кэшированные блоки RDD, управляемые параметром spark.storage.decommission.rddBlocks.enabled и перетасовать блоки, управляемые параметром spark.storage.decommission.shuffleBlocks.enabled. Если у других исполнителей недостаточно памяти для переноса блоков, можно использовать резервное хранилище.
Когда исполнители начинают вывод из эксплуатации, его shuffle-данные переносятся на одноранговые исполнители вместо повторного пересчета блоков. Если отправка блоков в случайном порядке исполнителю не удалась, значение параметра spark.storage.decommission.maxReplicationFailuresPerBlock предоставит количество повторных попыток миграции. В stderr-логе драйвера будут отображаться строки, обновляющие выходные данные карты для <shuffle_id> до BlockManagerId(<executor_id>, <ip_address>, <port>, <topology_info>), обозначающие подробности о переносе shuffle-блоков.
Также Spark поддерживает резервную конфигурацию хранилища (spark.storage.decommission.fallbackStorage.path), и ее можно использовать в случае сбоя переноса shuffle-блоков на одноранговые исполнители. Однако в Spark есть проблема, из-за которой эти блоки не могут быть правильно прочитаны из резервного пути, и задание завершается с ошибкой с исключением java.io.IOException, связанной с повреждением потока и некорректным декодированием смещения <offset_id> входного буфера: java.io.IOException: Stream is corrupted, net.jpountz.lz4.LZ4Exception: Error decoding offset <offset_id> of input buffer
Поэтому пригодится спекулятивное перепланирование задач, настраиваемое через параметр spark.executor.decommission.killInterval, значение которому можно задать равное известному времени жизни спотового инстанса.
Узнайте больше про использование Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://medium.com/teads-engineering/running-spark-pipelines-on-emr-using-spots-instances-28fc561bdc97
- https://cloud.yandex.ru/blog/posts/2019/06/preemptible-vm
- https://www.waitingforcode.com/apache-spark/what-new-apache-spark-3.1-nodes-decommissioning/read
- https://aws.github.io/aws-emr-containers-best-practices/spot-instances-resiliency/docs/copying-shuffle-data/

