
В рамках обучения дата-инженеров сегодня рассмотрим пример отправки данных в платформу сбора и анализа системных логов Splunk с помощью Apache NiFi. Как работает процессор PutSplunkHTTP, когда вместо него стоит выбрать InvokeHTTP, что такое HEC-токен и какие HTTP-методы REST API обеспечивают интеграцию Splunk с Apache NiFi. Что такое Splunk и как...
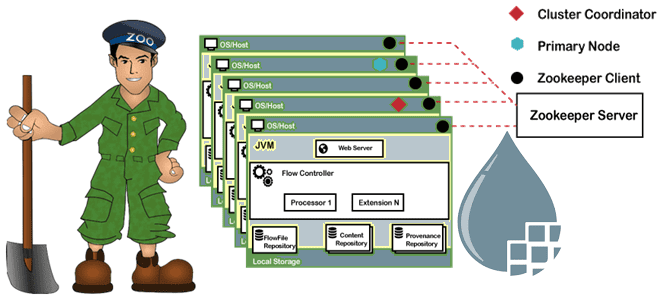
Сегодня рассмотрим важную для обучения администраторов кластера Apache NiFi тему по установке и настройке этого потокового ETL-фреймворка с использованием встроенного сервиса координации и синхронизации метаданных в распределенных системах Zookeeper. А также рассмотрим, как процесс выбора лидера в кластере Zookeeper позволяет серверам избежать аномальных всплесков трафика от клиентов и роста нагрузки....

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...
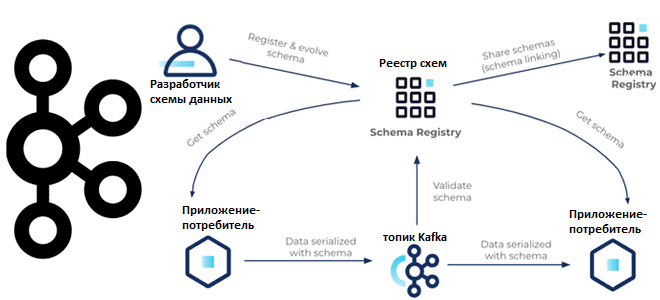
С какими проблемами качества данных сталкивается дата-инженер при работе с Apache Kafka и как реестр схем поможет их решить. Чем формат сериализации Apache AVRO отличается от JSON и Protobuf, как использовать Schema Registry и обеспечить совместимость данных: краткое пошаговое руководство для дата-инженера. Качество данных и реестр схем Apache Kafka Низкое...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...
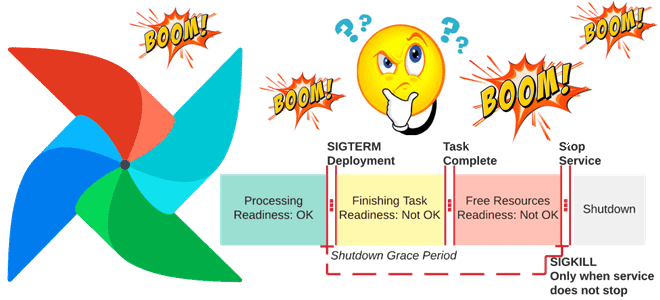
Каждый дата-инженер, который работает с Apache Airflow, сталкивался с сигналом SIGTERM, который отправляется задачам и приводит к сбою DAG. Сегодня рассмотрим, почему случается исключение airflow.exceptions.AirflowException, которое генерирует этот сигнал, и как его избежать. Тайм-аут выполнения DAG Одна из причин, по которой задача получает сигнал SIGTERM, связана с небольшим значением параметра...
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...