
Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода.
Дорогой Apache Spark на AWS EMR
Duolingo – это популярная бесплатная платформа для изучения языка и краудсорсинговых переводов. Сервис разработан так, что по мере прохождения уроков пользователи параллельно помогают переводить веб-сайты, статьи и другие документы. Компания обслуживает более 40 миллионов активных пользователей в месяц, ежедневно обрабатывая терабайты данных в облаке, что приводит к значительным затратам. Поэтому эффективное использование облака напрямую влияет на итоговую прибыль компании. Duolingo имеет ряд повторяющихся производственных заданий Apache Spark, выполняемых на AWS EMR. Перед дата-инженерами компании была поставлена цель снизить затраты на облачный кластер, даже за счет увеличения времени выполнения вычислений.
Определение параметров облачной инфраструктуры для оптимизации стоимости и скорости выполнения Spark-заданий нецелесообразно и невозможно для разработчиков распределенных приложений и дата-инженеров. Даже при оптимальных настройках для одного приложения задания Spark различаются по базе кода, размерам данных и спотовым ценам на облако, что приводит к большим различиям в соотношении затрат и производительности. Большинство пользователей облачных сервисов полагаются на простые эмпирические правила или рекомендации коллег в отношении того, какие настройки следует выбирать. Оптимизация этих вариантов требует тщательного изучения типов инстансов, облачных настроек и Spark-конфигураций, что требует много времени и сил. Самостоятельное определение наилучшей конфигурации потребует обширного ручного тестирования и длительной проверки множества параметров, что выливается в большие трудовые, временные и денежные затраты, о чем мы писали здесь.
Поэтому инженеры Duolingo решили воспользоваться сервисом Spark Cluster Autotuner от компании Sync, который избавляет от необходимости выбирать правильное оборудование кластера AWS и конфигурации Spark для работы приложений. Используя только журнал событий Spark и связанную с ним информацию о кластере, Cluster Autotuner возвращает оптимальные конфигурации кластера и приложения для следующего запуска. Как это работает, рассмотрим далее.
Что такое Cluster Autotuner от Sync и как он работает
Cluster Autotuner работает путем математического моделирования деталей журнала событий Spark на уровне задач и расчета того, как эти детали будут меняться на различных конфигурациях оборудования, оценивая время выполнения на каждом наборе оборудования. Оценки времени выполнения сопоставляются с прайсами AWS, чтобы получить оценки производительности (время выполнения и стоимость) для каждой конфигурации. Расчет оптимизации выполняется для поиска по всем конфигурациям, чтобы выбрать наилучшие варианты для пользователя.
К примеру, для одного из ETL-конвейеров Duolingo была выполнена оценка производительности заданий на 3-х разных типах оборудования. В этом примере небольшое количество рабочих процессов приводило к длительным, но недорогим заданиям. По мере увеличения числа worker’ов приложение будет работать быстрее, но дороже. Начальная входная конфигурация находилась глубоко на плато убывающей отдачи от кластерного масштабирования. Поэтому было рекомендовано сократить количество worker’ов, чтобы уйти от плато времени выполнения. В случае с Duolingo стоимость была единственным релевантным параметром. С другой стороны, если бы время выполнения было критическим параметром, можно было бы выбрать другую точку на этой кривой, которая выполняется почти так же быстро, как исходное задание, но при этом обеспечивает значительную экономию средств. Такая гибкость выбора является основным преимуществом Spark Cluster Autotuner: оптимальность настроек зависит от того, что необходимо изменить каждой конкретной компании: стоимость или время выполнения.
Когда Duolingo запустила предложенную конфигурацию в своем производственном кластере AWS EMR, планируемая экономия средств была реализована почти сразу же за счет уменьшения размера кластера (с 1664 до 384 виртуальных ЦП). Хотя размер кластера был уменьшен в 4 раза, время выполнения увеличилось лишь незначительно с 17 до 22 минут, а стоимость снизилась на 55%.
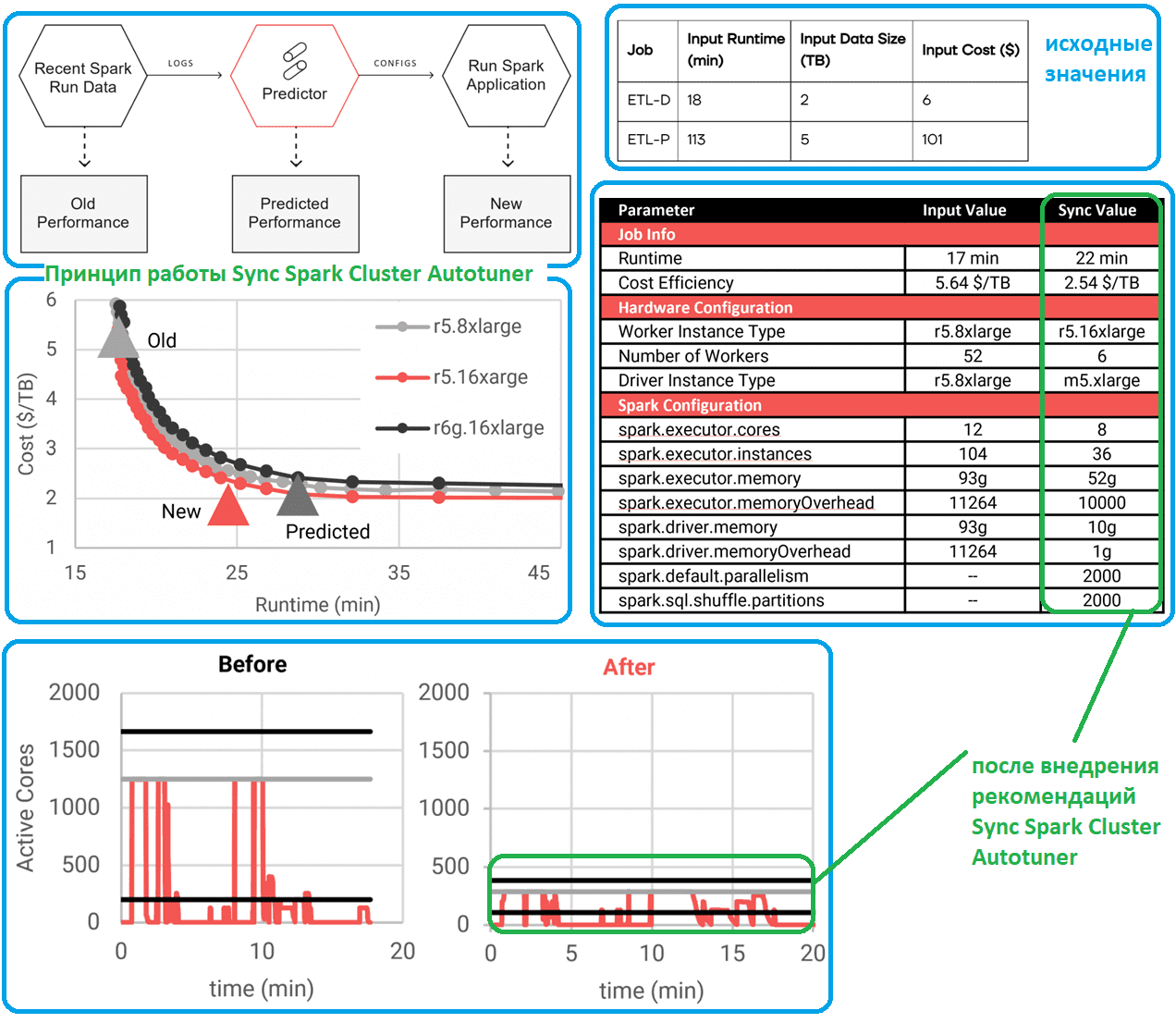
В журнале входных данных среднее количество активных ядер составляет лишь около 1/6 ядер, доступных для Spark. Это указывает на то, что большая часть работы распределяется неравномерно, и большая часть времени кластера тратится на бездействие. Оптимизированный результат уменьшил размер кластера, приблизив среднюю активность к доступной мощности, сделав работу более эффективной и, следовательно, менее дорогой. Конечно, те этапы, которые были хорошо распределены, теперь занимают больше времени, что приводит к немного большему времени выполнения. На первый взгляд кажется, что уменьшение размера кластера поможет сократить затраты еще больше. Однако, это не совсем верно, поскольку увеличение времени выполнения также увеличивает затраты на драйверы и EBS. Cluster Autotuner учитывает все эти факторы, чтобы оценить общую стоимость выполнения задания в различных размерах кластера.
Стоит также отметить изменения размера драйвера в Spark задании, поскольку экземпляр драйвера по требованию в AWS EMR может стоить столько же, сколько несколько эквивалентных спотовых экземпляров. Проанализировав входной журнал, Cluster Autotuner определил, что m5.xlarge имеет достаточно памяти для выполнения этой задачи, что снизило стоимость драйвера почти в 10 раз. Наконец, изменения в конфигурациях Spark в основном должны соответствовать новой конфигурации оборудования, хотя эти настройки необходимы для эффективной работы приложения на оборудовании. Изменения в аппаратном обеспечении и настройках Spark могут влиять на время выполнения задания, что требует глубокого математического моделирования и оптимизации. Cluster Autotuner учитывает эти зависимости, предлагая наиболее оптимальный вариант конфигурации оборудования и самого Spark-задания.
Освойте администрирование и использование Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

