В рамках обучения дата-инженеров сегодня рассмотрим пример отправки данных в платформу сбора и анализа системных логов Splunk с помощью Apache NiFi. Как работает процессор PutSplunkHTTP, когда вместо него стоит выбрать InvokeHTTP, что такое HEC-токен и какие HTTP-методы REST API обеспечивают интеграцию Splunk с Apache NiFi.
Что такое Splunk и как он работает
Напомним, Splunk является популярной платформой сбора и анализа системных логов из любых источников. Благодаря встроенному языку запросов SPL (Search Processing Language) Splunk может быстро найти в данных нужную информацию и представить ее в наглядной форме (отчеты, графики). Поддержка множества источников данных позволяет пользователю объединить события из разных систем и обнаружить в них закономерности. Задав пороговые значения по определенному параметру, можно генерировать оповещения об инцидентах или автоматически реагировать на них запуском скриптов согласно правилам. Это пригодится в управлении ИТ-инфраструктурой, аналитике работы программных продуктов, обеспечения информационной безопасности, мониторинга клиентского опыта и других вопросах анализа продуктовых метрик в различных бизнес-приложениях и системах интернета вещей.
Надежный и безопасный сбор данных из удаленных источников и их пересылку в Splunk для индексации и консолидации обеспечивают универсальные сервера (Universal Forwarders, UF). Они могут масштабироваться до десятков тысяч удаленных систем, собирая терабайты данных. Возможна установка тысяч таких UF-серверов на различных вычислительных платформах и архитектурах без потери производительность сети и хостов.
Самым эффективным и быстрым способом отправить данные в Splunk из любого приложения считается сборщик событий HTTP – HEC (HTTP Event Collector), который позволяет отправлять данные по HTTP или HTTPS. Чтобы использовать HEC, разработчику приложения нужно добавить всего несколько строк кода для отправки данных. HEC основан на токенах, поэтому разработчику не нужно жестко кодировать свои учетные данные Splunk Enterprise или Splunk Cloud Platform в своем приложении или вспомогательных файлах. Токен HEC представляет собой глобальный уникальный идентификатор (GUID), который Splunk использует для аутентификации. При использовании HTTP-запроса можно добавить токен HEC в заголовок авторизации следующим образом: Authorization: Splunk <hec_token>.
В Splunk данные события могут быть назначены ключу события (event) в JSON-объекте HTTP-запроса или могут быть необработанным текстом. Ключ события находится на том же уровне в JSON-пакете событий, что и ключи метаданных. Данные события в виде ключ-значение, представленные в фигурных скобках, могут быть в любом формате: строка, число, другой объект JSON и пр. Можно объединить несколько событий в один пакет с помощью запроса. Группировка событий указывает, что любые метаданные событий в запросе должны применяться ко всем событиям, содержащимся в запросе. Такое пакетирование может значительно повысить производительность, когда нужно проиндексировать большие объемы данных. Однако, далее мы рассмотрим, как использовать Apache NiFi для форматирования потоковых данных и отправки их с HEC-токеном на целевой URL-адрес Splunk.
Настройка Apache NiFi
Все манипуляции с данными (потоковыми файлами, Flow File) в Apache NiFi обеспечивают специальные обработки, которые называют процессоры. В частности, для отправки данных в Splunk есть процессор PutSplunkHTTP, который отправляет содержимое потокового файла на указанный сервер Splunk по HTTP или HTTPS с поддержкой подтверждения индекса HEC. Этот процессор является аналогом процессора PutSplunk, но в отличие от него, вместо протоколов транспортного уровня TCP и UDP, PutSplunkHTTP использует протоколы более высокого уровня по сетевой модели OSI, отправляя данные в Splunk через HTTP или HTTPS. Таким образом, этот процессор имеет сходство с процессором GetSplunk, а свойства, относящиеся к соединению с сервером Splunk, идентичны. Но PutSplunkHTTP позволяет пользователю указать некоторые метаданные о событии, отправляемом в Splunk: Character Set и Content Type для содержимого потокового файла с использованием соответствующих свойств. Когда входящий Flow File имеет атрибут mime.type, процессор будет использовать его, если только не установлено свойство Content Type, которое переопределяет атрибут потокового файла.
Сборщик событий HTTP (HEC) в Splunk предоставляет возможность подтверждения индекса, которое можно использовать для отслеживания статуса индексации отдельных событий. PutSplunkHTTP поддерживает эту функцию, обогащая исходящий потоковый файл необходимой информацией, позволяя следующему по конвейеру процессору опрашивать статус Flow File. Необходимая информация для этого хранится в атрибутах потокового файла splunk.acknowledgement.id и splunk.responded.at.
Для более точной обработки потоковые файлы по возможности обогащаются дополнительной информацией, хранимой в атрибуте потокового файла splunk.status.code или splunk.response.code, в зависимости от успешности обработки. Атрибут splunk.status.code всегда заполняется при выполнении вызова Splunk API и содержит код состояния HTTP-ответа. Если Flow File обработан неудачно, т.е. переведен в отношение failure, атрибут splunk.response.code также может быть заполнен на основе кода ответа Splunk.
Однако, процессор PutSplunkHTTP отправляет только одно событие в Splunk за раз, иначе Splunk не может анализировать данные. Поэтому для обеспечения большего контроля целесообразно использовать процессор InvokeHTTP – он позволяет отправлять несколько событий в сообщении, которое Splunk может корректно индексировать. Кроме того, это повышает эффективность использования ресурсов на обоих концах конвейера данных.
Дата-инженеры знают, что в NiFi у каждого процессора есть настройка распараллеливания задач, связанная с числом потоков, которые будет использовать процессор. При изначальной настройке NiFi хосту назначается количество потоков по умолчанию: максимальное количество потоков, управляемых таймером, и максимальное количество потоков, управляемых событиями. Эти параметры устанавливается в настройках контроллера и задают максимальное количество потоков, которые может использовать NiFi на всех процессорах. Предположим, для конкретного процессора установлено количество одновременных задач, например, 5. Когда этот процессор будет выполняться, он будет потреблять 5 потоков от общего количества, выделенного для NiFi. Все процессоры будут кумулятивно потреблять потоки при выполнении. При этом независимо от того, сколько одновременных задач настроено для всех процессоров, общее количество одновременных задач не может превышать общее количество назначенных потоков. Увеличивая количество потоков, можно значительно увеличить пропускную способность NiFi. Но у NiFi есть пул потоков, который использует заданное количество потоков на узел. Поэтому увеличение количества одновременных задач для конкретного процессора сверх этого предела негативно влияет на другие процессоры, работающие в кластере Apache NiFi.
Таким образом, нужно отправлять несколько событий за раз, в одном сообщении, чтобы сократить число HTTP-запросов и избегать потребления всех ресурсов кластера. Для этого следует выполнить набор шагов:
- отправить данные в кластер NiFi, используя подходящий процессор с учетом поддерживаемых им методов и протоколов;
- преобразовать данные в нужный формат, а также фильтровать, сжимать или форматировать их перед их отправкой в Splunk, представив их в виде фрагмента событий в формате JSON, как этого требует Splunk. Например, следующим образом:
{“event”: {“message”: “Something happened”,“severity”: “INFO”}}
{“event”: { “message”: “Something crashed”, “severity”: “ERROR”}}
{“event”: { “message”: “Something is about to crash”, “severity”: “WARNING”}}
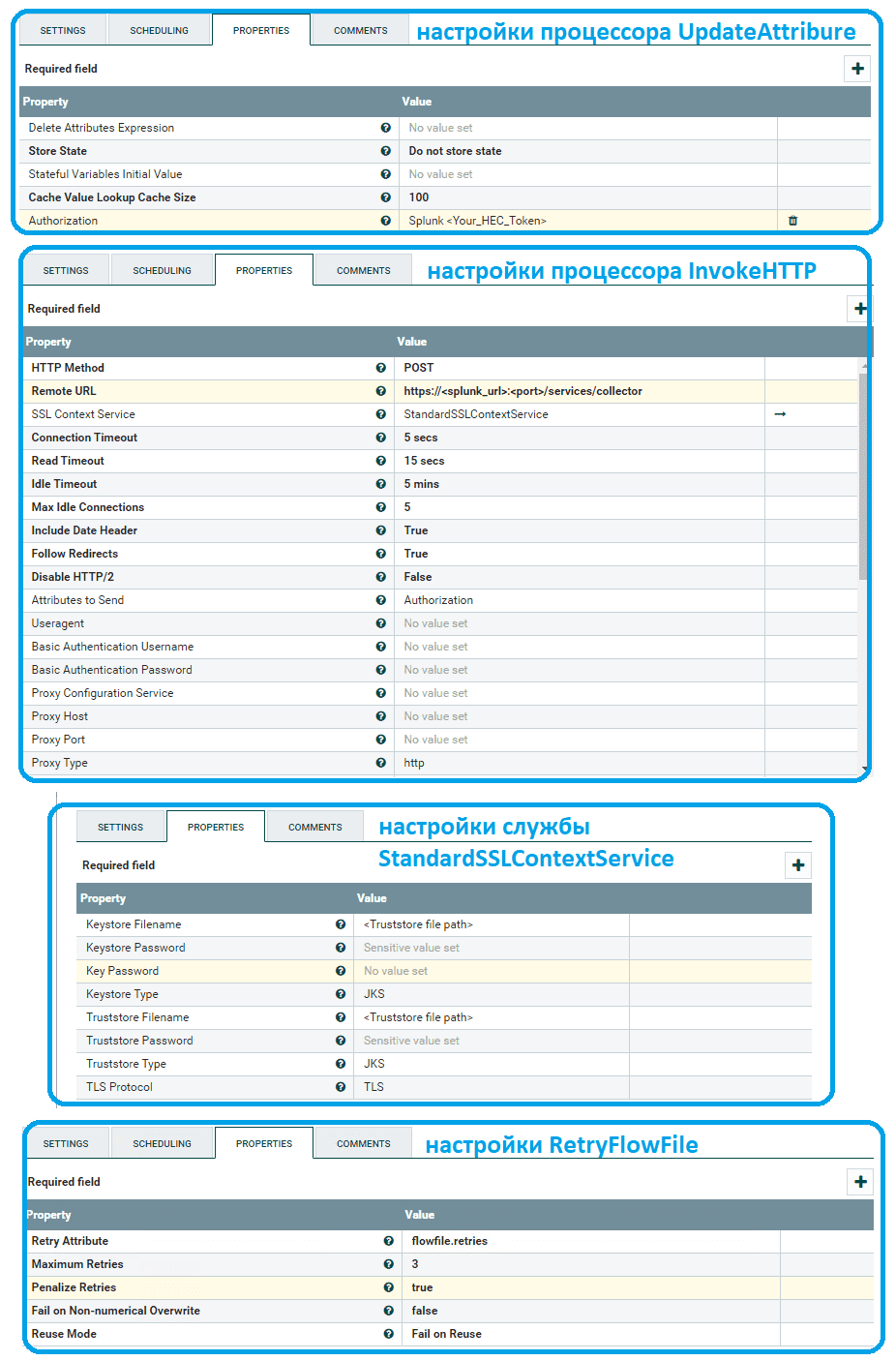
- отправить события в Splunk. Здесь можно использовать процессор UpdateAttribure, чтобы добавить атрибут авторизации в потоковый файл, который содержит токен Splunk HEC. Этот атрибут применяется в качестве заголовка в HTTP-запросе.
Чтобы процессор InvokeHTTP мог использовать атрибута авторизации в качестве заголовка, нужно использовать контекстную службу SSL, обновив следующие атрибуты:
- метод HTTP изменить на POST;
- вместо удаленного URL-адреса вставить URL-адрес Splunk;
- в SSL Context Service создать StandardSSLContextService;
- в атрибуты для отправки добавить Авторизацию (Authorization).
При использовании конечной точки HTTPS для HEC необходимо создать службу контроллера контекста SSL NiFI, которая указывает на хранилище ключей/доверенных сертификатов Java, содержащее корневые сертификаты Splunk. Иначе NiFi не будет доверять соединению и отклонит его. Чтобы создать файл хранилища доверенных сертификатов, необходимо загрузить сертификат Splunk и использовать следующую команду для создания файла truststore.jks:
keytool -import -v -trustcacerts -alias splunkcer -file <Path to Splunk certificate> -storetype JKS -keystore <Path to save the truststore> -storepass <Password>
Атрибут Key Password станет паролем, установленным в команде. А для решения проблем с подключением и тайм-аутов сокетов в процессоре InvokeHTTP можно добавить процессор RetryFlowFile, который будет повторно отправлять неудавшиеся потоковые файлы до трех раз. Таким образом, можно управлять данными из всех источников в одной точке доступа.
Узнайте больше про тонкости администрирования и эксплуатации Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/@maozcyber12/sending-data-to-splunk-using-apache-nifi-58c3e01f5d4a
- https://dev.splunk.com/enterprise/docs/devtools/httpeventcollector/
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-splunk-nar/1.16.1/org.apache.nifi.processors.splunk.PutSplunkHTTP/additionalDetails.html