 699
699 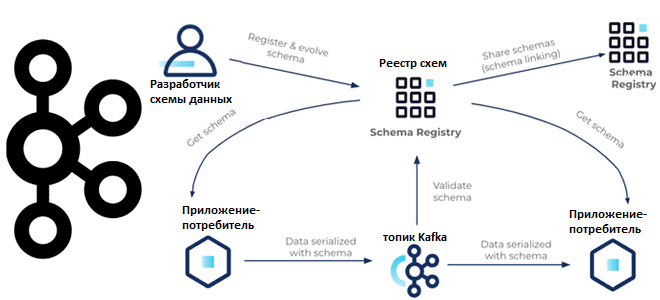
Содержание
С какими проблемами качества данных сталкивается дата-инженер при работе с Apache Kafka и как реестр схем поможет их решить. Чем формат сериализации Apache AVRO отличается от JSON и Protobuf, как использовать Schema Registry и обеспечить совместимость данных: краткое пошаговое руководство для дата-инженера.
Качество данных и реестр схем Apache Kafka
Низкое качество данных становится особенно заметным в потоковой обработке, т.к. неверные или неполные сведения здесь распространяются быстрее и в большее количество мест. В частности, в управляемых событиями системах, которые немедленно реагируют на данные в реальном времени, неверные данные могут привести к сбою всей экосистемы или неоптимальной работе с информацией. В шаблонах асинхронного обмена сообщениями самостоятельные сервисы разрабатываются, обслуживаются и развертываются разными командами, которые должны иметь возможность обмениваться данными по согласованным контрактам.
В случае использования Apache Kafka как основной распределенной платформы потоковой передачи событий самым простым способом определения и совместного использования контрактов данных без операционных сложностей является реестр схем (Schema Registry). Этот компонент от Confluent Platform позволяет приложениям-продюсерам и потребителям общаться по четко определенному контракту данных в форме схемы, а также контролирует эволюцию схемы с помощью четких правил совместимости и оптимизирует полезную нагрузку по сети, передавая идентификатор схемы вместо ее полного определения.
По своей сути Schema Registry состоит из двух основных частей:
- REST-сервис для проверки, хранения и извлечения схем AVRO, JSON Schema и Protobuf;
- сериализаторы и десериализаторы, которые подключаются к клиентам Apache Kafka для управления хранением схемы и извлечением сообщений в этих 3-х форматах. Про другие форматы данных и инструменты работы с ними в Apache Kafka читайте в нашей новой статье.
Рассмотрим, как можно использовать реестр схем для надежного создания и эффективного использования качественных данных в Apache Kafka в виде последовательности шагов:
- выбор формата сериализации данных;
- регистрация схемы в реестре схем;
- создание сообщений и их публикация в Kafka;
- потребление сообщений из топика Kafka;
- использование и развитие схемы данных.
Каждый из этих шагов разберем далее более подробно.
5 шагов обеспечения качества потоковых данных с реестром схем
Прежде всего нужно выбрать, какой формат сериализации данных использовать с Kafka. Напомним, сериализация данных — это процесс преобразования объекта в поток байтов для отправки по сети и сохранения в топик Kafka. Обратный процесс восстановления объекта из потока байтов, хранящихся в топике Kafka, называется десериализацией. Рекомендуется использовать формат сериализации с поддержкой схемы данных. Схема действует как своего рода API в потоковой передаче данных, выступая в качестве средства обеспечения взаимодействия автономных сервисов и приложения. Чтобы выбрать наиболее подходящий в том или ином случае формат сообщений, сравним их по некоторым критериям в следующей таблице.
|
Критерий оценки формата данных |
AVRO |
Protocol Buffer |
JSON |
|
Тип данных |
бинарный |
бинарный |
текстовый |
|
Поддержка схемы |
Да |
Да |
Да |
|
Чтение схемы |
Да |
Нет |
Нет |
|
Язык схемы |
JSON |
Protobuf IDL |
JSON |
|
Сжатие данных |
Высокое сжатие |
Высокое сжатие |
Без сжатия |
|
Скорость |
Высокая |
Высокая |
Умеренная |
|
Простота использования |
Высокая |
Нормальная |
Высокая |
|
Поддержка языками программирования |
Хорошая |
Отличная |
Хорошая |
Выбрав формат сообщений, следует зарегистрировать схему данных в Schema Registry, который должен быть запущен. Чтобы использовать реестр схем, достаточно добавить свойство с URL-адресом подключения к нему и назначить в качестве сериализатора и десериализатора классы KafkaAvroSerializer и KafkaAvroDeserializer соответственно. Начать регистрацию схемы данных можно через пользовательский интерфейс, API, CLI или плагин Maven. Реестр будет назначать монотонно увеличивающийся, но не всегда последовательный уникальный идентификатор в пределах этого реестра каждой зарегистрированной схеме. Для исследовательских целей приложение-продюсер может напрямую зарегистрировать схему в реестре, если свойство конфигурации auto.register.schemas установлено в значение true.
Далее можно отправлять данные в Kafka. При этом продюсер извлекает идентификатор схемы из реестра схем с учетом формата (AVRO, Protobuf или JSON) со ссылкой на схему, которая его описывает. Затем идентификатор схемы добавляется к полезной нагрузке записи (идентификатор схемы + запись) и отправляется в топик Kafka. Вся эта оркестровка выполняется автоматически сериализаторами AVRO, Protobuf и JSON на клиентах Kafka.
На стороне потребителя, после получения полезной нагрузки, сперва извлекается идентификатор схемы (байты полезной нагрузки с 1 по 5), который используется для поиска/выборки схемы записи в Реестр, если он недоступен в КЭШе. Обычно клиенты кэшируют идентификатор схемы для отображения схемы при первом обращении к реестру и используют его для последующих поисков. Имея схему записи и текущую схему чтения, потребитель может десериализовать полезную нагрузку. Аналогично предыдущему шагу, вся эта оркестровка выполняется автоматически десериализаторами AVRO, Protobuf и JSON на клиентах Kafka.
Поскольку приложения-продюсеры и потребители существуют независимо друг от друга, они могут обновлять свои схемы данных по отдельности в соответствии с согласованным типом совместимости. После определения исходной схемы приложениям может потребоваться ее дальнейшее развитие. Когда это происходит, для нижестоящих потребителей критически важно беспрепятственно обрабатывать данные, закодированные как по старой, так и по новой схеме. С этой проблемой несовместимости схем данных дата-инженеры часто сталкиваются на практике, если вопросы управления данными и эволюции схемы не были продуманы на старте.
C обратной совместимостью проще работать, поскольку она не требует заранее продумывать будущие изменения, нужно лишь учитывать прошлые версии схемы данных и вносить изменения по мере появления новых требований. При этом сперва обновляются потребители, чтобы они соответствовали изменению схемы, а затем продюсеры. Вообще в реестре схем есть несколько стратегий совместимости схем, по умолчанию используется тип BACKWARD, который разрешает удалять поля из модели данных и добавлять optional-поля, значения которых могут быть null. Сравнение схемы идет только с последней версией, а при обновлении модели в первую очередь обновляются потребители, чтобы не получить ошибку десериализации. Последняя может случиться при удалении поля и обновлении продюсера, пославшего сообщение без этого поля, но потребитель об этом не знает и ожидает сообщения в предыдущем виде. Подробнее об этом читайте в нашей новой статье.
Наконец, по мере роста использования Apache Kafka для поддержки большего количества критически важных рабочих нагрузок и команд, потребность в создании и применении глобальных средств контроля качества данных все более возрастает. Связывание схем обеспечивает простой способ их совместного использования и установления согласованных средств контроля качества в любой инфраструктуре: облачный или локальный кластер, гибридная среда и пр. Реестр схем Apache Kafka позволяет обеспечить глобальную совместимость данных благодаря простоте эксплуатации за счет использования общих схем, которые синхронизируются в режиме реального времени, включая экономичный обмен данными, зеркалирование данных в нескольких регионах для аварийного восстановления, миграцию кластера и прочие полезные возможности.
Узнайте больше деталей по администрированию и эксплуатации Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

