Сегодня рассмотрим важную для обучения администраторов кластера Apache NiFi тему по установке и настройке этого потокового ETL-фреймворка с использованием встроенного сервиса координации и синхронизации метаданных в распределенных системах Zookeeper. А также рассмотрим, как процесс выбора лидера в кластере Zookeeper позволяет серверам избежать аномальных всплесков трафика от клиентов и роста нагрузки.
Настройка Apache NiFi
Apache Nifi включает настройку сервиса синхронизации метаданных Zookeeper по умолчанию для создания и управления кластером экземпляров, работающих в распределенных системах. Хотя уведомления в Zookeeper асинхронные, его можно использовать для создания примитивов синхронной согласованности, таких как очереди и блокировки. Это возможно благодаря тому, что Zookeeper устанавливает общий порядок обновлений и имеет механизмы для раскрытия этого порядка, избегая опросов, таймеров и прочих триггеров, которые вызывают всплески трафика и ограничивают масштабируемость.
Возвращаясь к администрированию кластера Apache NiFi, отметим, что практически все файлы его конфигурации находятся в каталоге ./conf. Для настройки Zookeeper нужно отредактировать 3 файла: nifi.properties, Zookeeper.properties и state-management.xml. Но перед этим стоит вспомнить, что Zookeeper рекомендует нечетное количество узлов в кластере, т.е. экземпляров NiFi, не менее 3. Это связано с тем, что Zookeeper работает на основе так называемого алгоритма консенсуса для поддержания состояния/связности между узлами. Нечетное количество узлов обеспечивает возможность выбора между 2-мя альтернативами.
Итак, если в кластере Apache NiFi 3 узла, надо указать их IP-адреса в файле nifi.properties:
nifi.state.management.embedded.Zookeeper.start=true nifi.Zookeeper.connect.string=ip1:2181,ip2:2181,ip3:2181 nifi.Zookeeper.auth.type=default nifi.remote.input.host=ip1 // current node ip nifi.remote.input.secure=false nifi.remote.input.socket.port=9998 nifi.remote.input.http.enabled=true // set true if you want http nifi.cluster.is.node=true nifi.cluster.node.address=ip1 // current node ip nifi.cluster.node.protocol.port=7474 nifi.web.http.host=ip1 // current node ip. use either https or http nifi.web.http.port=8443 nifi.cluster.load.balance.port=6342
Здесь же указаны порты, которые Zookeeper использует внутри для связи между экземплярами. При необходимости их можно изменить. В качестве веб-протокола прикладного уровня следует выбрать между HTTP и HTTPS, указав это для nifi.web.http или nifi.web.https соответственно. Если в конфигурации nifi.remote.input.secure установлено значение true, то запросы отправляются как HTTPS на nifi.web.https.port. Если в конфигурации nifi.remote.input.secure установлено значение false, HTTP-запросы отправляются на nifi.web.http.port.
Далее нужно внести данные об IP-адресах серверов в файл Zookeeper.properties. Этот файл содержит дополнительную информацию, которую будет использовать Zookeeper для получения сведений о серверах.
server.1=ip1:2888:3888 server.2=ip2:2888:3888 server.3=ip3:2888:3888 clientPort=2181
Наконец, чтобы поддерживать состояние NiFi во всех экземплярах, нужно внести данные о провайдерах состояния в файле state-management.xml. Новый провайдер состояния будет указывать на Zookeeper.
<cluster-provider> <id>zk-provider</id> <class>org.apache.nifi.controller.state.providers.Zookeeper.ZookeeperStateProvider</class> <property name="Connect String">ip1:2181,ip2:2181,ip3:2181</property> <property name="Root Node">/nifi</property> <property name="Session Timeout">10 seconds</property> <property name="Access Control">Open</property> </cluster-provider>
Чтобы обеспечить безопасный вход в систему, следует настроить свойство Access Control, указав списки доступа или другой способ аутентификации вместо небезопасного Open (вход без имени пользователя и пароля).
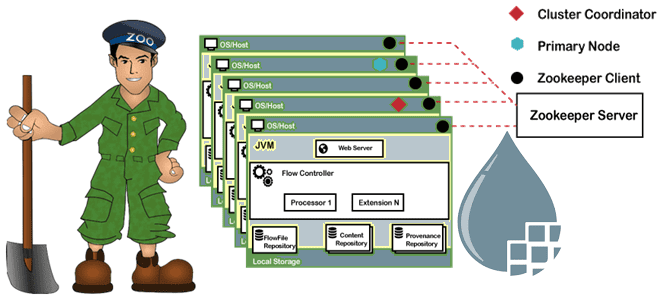
Настроив все 3 файла на всех 3 серверах кластера Apache NiFi, нужно указать Zookeeper, какой сервер главный. Для этого нужно создать файл с именем myid в папке ./states/Zookeeper. Этот файл будет использовать Zookeeper для определения статуса экземпляра. Значение внутри этого файла должно быть 1 для первого экземпляра, 2 для второго и т.д. После этого можно запустить все экземпляры NiFi и увидеть в командной сроке сообщение о начале процесса выбора лидера. Когда этот процесс завершится, можно открыть интерфейс NiFi на любом из серверов. Процесс выбора лидера в кластере Zookeeper мы подробнее рассмотрим далее.
Выбор лидера в Apache Zookeeper
Напомним, что Apache Zookeeper представляет собой распределенное хранилище ключ-значение (key-value), где пространство ключей образует древовидную иерархию как в файловой системе, а значения могут содержаться в любом узле иерархии (только в листьях). Клиентом в кластере Zookeeper являются узел с компонентами распределенного приложения, который периодически, в течение всей сессии подключения к серверу, посылает ему сигнальное сообщение (heartbeat). Сервер Zookeeper предоставляет все службы клиенту и посылает ему подтверждение при подключении. Если от сервера нет ответа, клиент автоматически перенаправляет сообщение другому серверу. Ведущий сервер или лидер (leader) выполняет все операции записи и запускает автоматическое восстановление при отказе любого из подключенных узлов. Лидеры выбираются при запуске служб. А их подписчики (follower) следуют инструкциям лидера и реплицирует себе его данные. Благодаря множеству подписчиков, операции чтения выполняются быстрее, т.к. считывать данные можно с любого узла.
Таким образом Zookeeper имитирует виртуальную древовидную файловую систему из взаимосвязанных узлов, которые представляют собой совмещенное понятие файла и директории. Каждый узел этой иерархии (znode) может одновременно хранить данные и иметь подчиненные узлы (потомки). Постоянные узлы (persistent) сохраняют данные на диск и никогда не пропадают, а эфемерные узлы недолговечны – они создаются в рамках конкретной сессии подключения клиента к серверу и существуют только во время ее действия. Такие узлы не имеют потомков, а представляют собой объект, в котором можно временно сохранить какие-то данные.
Простым способом выбора лидера с помощью Zookeeper является использование флагов SEQUENCE|EPHEMERAL при создании узлов, представляющих предложения клиентов. Идея состоит в том, чтобы иметь z-узел “/election”, чтобы каждый z-узел создавал дочерний z-узел “/election/guid-n_” с обоими флагами SEQUENCE|EPHEMERAL. С помощью флага последовательности Zookeeper автоматически добавляет порядковый номер, который больше любого ранее добавленного к дочернему элементу “/election”. Процесс, создавший z-узел с наименьшим добавленным порядковым номером, является лидером.
При этом важно следить за неудачами лидера, чтобы новый клиент возник как новый лидер в случае неудачи текущего. Тривиальное решение состоит в том, чтобы все прикладные процессы следили за текущим наименьшим z-узлом и проверяли, являются ли они новым лидером, когда наименьший z-узел уходит. В случае эфемерных узлов наименьший z-узел уйдет, если лидер выйдет из строя, потому что эфемерный узел существует только на время клиентской сессии.
Из-за этого при сбое текущего лидера все остальные процессы получают уведомление и стремятся получить текущий список потомков узла “/election”, вызывая команду getChildren. Если количество клиентов велико, большое число вызовов этой команду увеличивает нагрузку на сервера Zookeeper. Чтобы избежать этого, достаточно следить за следующим z-узлом в последовательности. Если клиент получает уведомление о том, что наблюдаемый им znode пропал, то он становится новым лидером в случае отсутствия меньшего z-узла. Это позволяет избежать эффекта всплеска, поскольку все клиенты смотрят разные z-узлы.
Однако, z-узел, не имеющий предшествующего в списке дочерних элементов, не означает, что создатель этого узла знает, что он является текущим лидером. Приложения могут рассмотреть возможность создания отдельного znode для подтверждения того, что лидер выбран по результатам соответствующей процедуры.
Узнайте больше про тонкости администрирования и эксплуатации Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники