 715
715 
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями.
5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow
Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях, планировщиках и других своих компонентах во встроенном или внешнем хранилище – базе данных метаданных. По умолчанию AirFlow поставляется с легковесной встраиваемой реляционной СУБД SQLLite. Для SQLite не требуется сервер базы данных, а сама БД хранится в локальном файле. Это вполне подходит для изучения фреймворка и личных пет-проектов, но крайне не рекомендуется для производственного использования из-за большого количества ограничений SQLite. В частности, SQLite работает только с последовательным исполнителем (SequentialExecutor), что означает невозможность параллельной обработки информации: задачи выполняются последовательно, одна за другой. Поэтому для работы с большим объемом данных и высокими нагрузками обычно используются Celery, Dask или Kubernetes, о чем мы писали здесь.
Что касается бэкенда, для производственного развертывания AirFlow лучше выбирать PostgreSQL (версия 12, 13, 14, 15 или 16) или MySQL 8.0. В официальной документации фреймворка подчеркивается, что, несмотря на сходство MySQL и MariaDB, последняя не подходит для использования в качестве серверной части AirFlow из-за разных подходов к индексации и других неочевидных отличий.
Чтобы запустить миграцию базы данных метаданных с SQLite на PostgreSQL, надо запустить команду airflow db migrate, предварительно остановив все работающие компоненты AirFlow. Но перед этим следует создать базу данных PostgreSQL, а также пользователя с ролью администратор, который будет обладать всеми необходимыми правами:
CREATE DATABASE airflow_db; CREATE USER airflow_user WITH PASSWORD 'airflow_pass'; GRANT ALL PRIVILEGES ON DATABASE airflow_db TO airflow_user;
При использовании 15-ой версии PostgreSQL нужны дополнительные привелегии:
USE airflow_db; GRANT ALL ON SCHEMA public TO airflow_user;
При этом экземпляр PostgreSQL должен поддерживать кодировку UTF-8. Кроме того, следует включить пользователя airflow_user в список управления доступом к этой базе данных, отразив это в конфигурационном файле pg_hba.conf. Также надо изменить созданного пользователя, установив схему данных по умолчанию:
ALTER USER airflow_user SET search_path = public;
Параметр search_path определяет схемы, которые база данных будет искать по умолчанию при выполнении запросов. Если схема не указана явно в запросе, база данных сначала будет искать объекты (таблицы, функции и т. д.) в схемах, перечисленных в параметре search_path. В PostgreSQL именно схема public используется по умолчанию и должна быть доступна всем пользователям. Кроме того, ORM-библиотека SqlAlchemy, обеспечивающая взаимодействие Python-объектов с базой данных метаданных, не позволяет указать конкретную схему в URI подключения. Поэтому нужно убедиться, что схема public находится в search_path пользователя PostgreSQL.
После настройки базы данных ее следует инициализировать с помощью команды
airflow db migrate
Затем необходимо настроить подключение к базе данных PostgreSQL. Для этого надо установить переменную среды строки подключения:
export AIRFLOW__DATABASE__SQL_ALCHEMY_CONN="postgresql+psycopg2://airflow_user:airflow_pass@host:5432/airflow_db"
При использовании SQLAlchemy версии 1.4.0+, необходимо использовать протокол postgresql:// и драйвер psycopg2, который указывается в строке подключения SqlAlchemy.
После этого надо создать соединение через пользовательский интерфейс фреймворка, указав идентификатор и тип подключения, хост, схема, логин и пароль созданного пользователя, а также порт 5432.
После выполнения всех указанных действий в конфигурационном файле airflow.cfg отобразится актуальная информация об исполнителе и базе данных метаданных, допустимая для производственного использования.
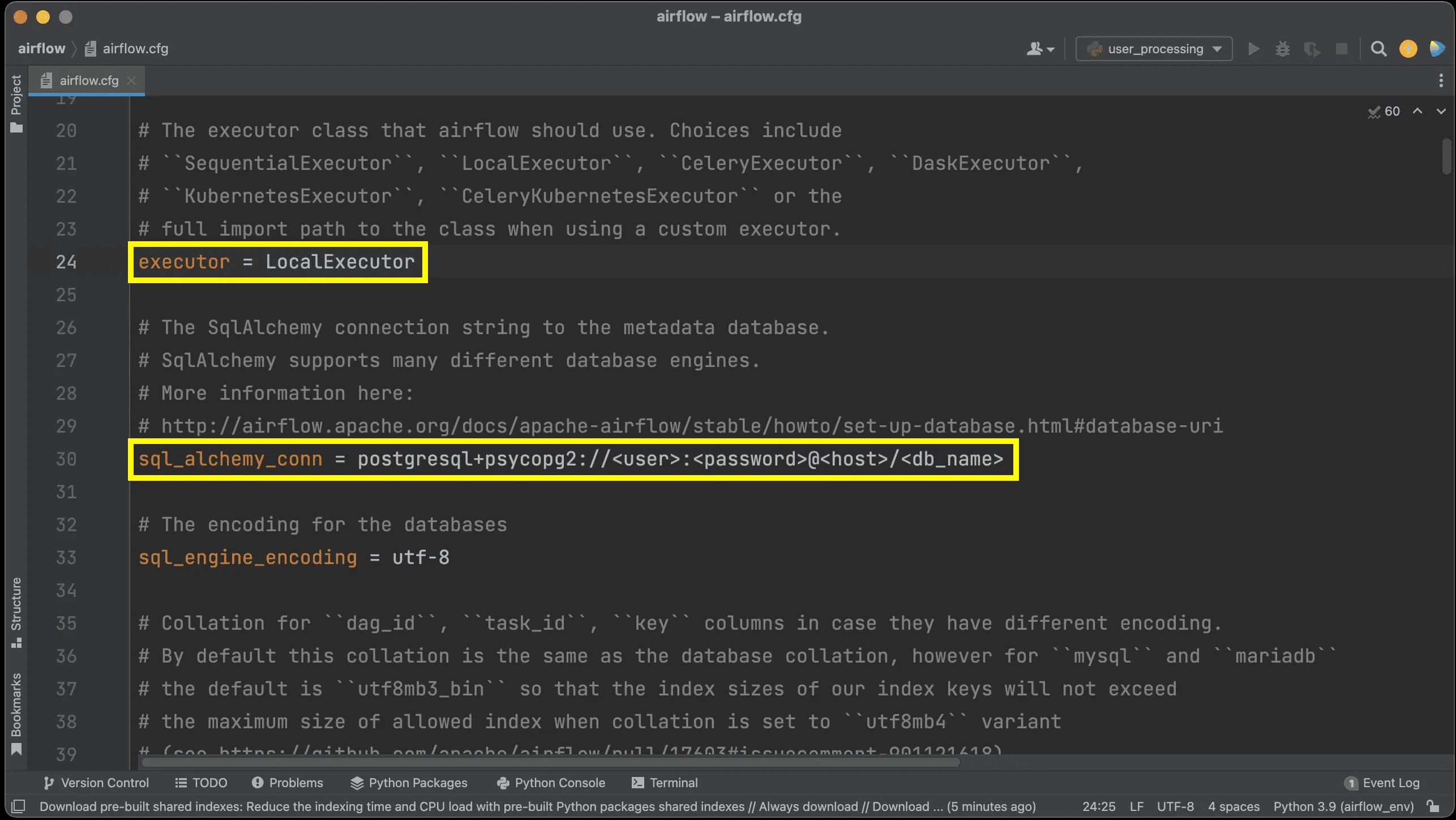
В заключение отметим, что при смене SQLite на PostgreSQL надо учитывать особенности этой СУБД. В частности, помнить о том, что в PostgreSQL каждое соединение создает новый процесс, потребляя много ресурсов. А AirFlow открывает множество подключений к базе данных метаданных. Поэтому рекомендуется использовать PGBouncer в качестве прокси-сервера базы данных для всех производственных установок PostgreSQL. Балансировщик PGBouncer может обрабатывать пул соединений из нескольких компонентов и сделает подключение к БД более устойчивым к временным сетевым проблемам.
Закрытие подключения к базе данных метаданных на работающем экземпляре AirFlow приводит к ошибке. Это особенно важно при использовании внешней СУБД в качестве бэкенда. Для облачных сервисов PostgreSQL, следует настроить конфигурацию keepalives_idle в параметрах соединения и установить значение меньше времени простоя, чтобы службы не закрывали простаивающие соединения после некоторого времени бездействия (около 5 минут). Для этого в конфигурационном файле airflow_local_settings.py надо настроить значения keepalive-аргументов, например, так:
keepalive_kwargs = {
"keepalives": 1,
"keepalives_idle": 30,
"keepalives_interval": 5,
"keepalives_count": 5,
}
Освоить на практике лучшие приемы использования Apache AirFlow в задачах дата-инженерии вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

