651
651 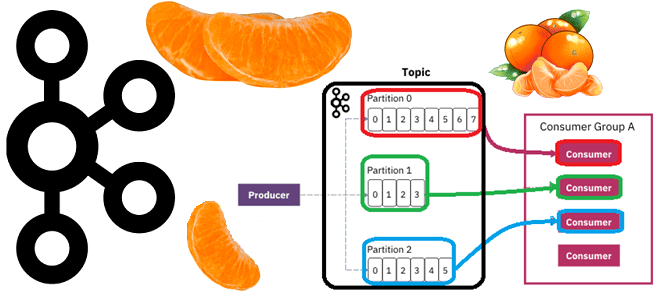
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера.
Что учитывать при разделении топика Apache Kafka
Хотя проектирование эффективной архитектуры данных можно назвать искусством, построение конвейера потоковой обработки считается инженерной задачей, которая решается с помощью типовых паттернов. Одним из них является вопрос разделения топика Apache Kafka на разделы – единицы параллелизма. Именно количество разделов определяет максимальное количество параллельных потребителей в одной группе, т.е. с одинаковым значением конфигурации group.id, поскольку только один потребитель из группы является активным, т.е. может считывать данные из раздела. Такое распараллеливание позволяет выровнять нагрузку на брокеры, поскольку в кластере Kafka лидеры и подписчики раздела обычно располагаются на разных узлах.
Физически раздел топика представляет собой каталог лог-файлов с опубликованными событиями, который должен целиком помещаться на одной машине. Поэтому, если в топике только один раздел, скорость публикации и время хранения данных ограничено возможностями этого узла. Однако, если разделов несколько, потенциально можно использовать несколько машин. Но больше разделов означает больше файлов и, что может снизить общий объем записи, если недостаточно памяти для буферизации сообщений. Это особенно актуально при использовании сервиса синхронизации метаданных Zookeeper вместо самоуправляемого кворума с протоколом KRaft, поскольку каждый раздел топика Kafka соответствует нескольким узлам в кластере ZooKeeper, который хранит все в памяти.
Кроме того, больше разделов означает более длительное время восстановления при сбое лидера. Хотя обработка любого раздела выполняется довольно быстро (в пределах нескольких миллисекунд), если этих разделов много (порядка пары тысяч), перевыборы лидера займут много времени.
Также, стоит помнить о том, что Kafka гарантирует упорядоченность сообщений только в рамках раздела. Поэтому если для приложений-потребителей важна хронология обработки сообщений, добиться ее при большом количестве разделов намного сложнее, чем в случае топика с единственным разделом. При проверке позиции потребителя, сохраняется одно смещение для каждого раздела, поэтому, чем больше разделов, тем дороже обходится контрольная точка позиции. Поскольку каждый раздел используется не более чем одним потребителем в группе потребителей, можно организовать однопоточный режим упорядоченного потребления. При этом один и тот же потребитель может потреблять данные из нескольких разделов. Поэтому количество разделов является ограничением максимального параллелизма потребителей.
Разумеется, при разделении топика нужно выбрать подходящую стратегию партиционирования: круговой перебор, ключ или явное указание раздела. Если стратегия разделения основана на каком-либо семантическом принципе, например, по значению бизнес-ключа, то расширение семантики становится сложнее. Например, раньше топик со входящими заявками делился на 2 раздела: юрлица и физлица. Однако, было бизнес принял решение также работать с другими участниками налоговых режимов: ИП и самозанятые. Хотя можно изменить конфигурацию существующего топика Apache Kafka, увеличив количество разделов при наличии свободного места, обработки ранее опубликованных сообщений по-новому будет не очень проста. Для этого придется повторно потреблять сообщения с определенного момента и усложнить логику потребления или опубликовать прежние сообщения в новый топик с корректно настроенным разделением.
Поэтому принимая решение о разделении топика на разделы, проектировщик потокового конвейера сокращает возможности дальнейшего масштабирования, т.к. разделить топик в будущем можно, а раздел – нет.
Теоретически максимальное число разделов может быть любым, но на практике это количество ограничено размером сохраняемых сообщений, которые могут поместиться на одном узле кластера Kafka. Поэтому, если в топике данных больше, чем может вместить один брокер, надо увеличить количество разделов. Кластер Kafka способен поддерживать до 10 тысяч разделов.
Таким образом, при решении вопроса о том, стоит ли делить топик на разделы, надо учитывать следующие факторы:
- количество потребителей и вариативность их поведения, включая надежность и скорость обработки сообщений;
- разницу в пропускной способности публикации и потребления сообщений, чтобы увеличить скорость потребления в случае высокопроизводительного продюсера, масштабировав количество потребителей, т.е. увеличив число разделов;
- семантику партиционирования на основе какого-либо бизнес-признака, а не только с целью балансировки нагрузки;
- толерантность к упорядоченности сообщений, которая гарантируется только в рамках раздела, а не является сквозной по всему топику;
- ресурсные возможности узла, на котором развернут экземпляр Kafka, т.е. объем свободного места на диске для сохранения сообщений и памяти для буферизации.
Разумеется, этот список не является исчерпывающим, и может быть расширен другими соображениями при проектировании отдельно взятого потокового конвейера. Однако, он содержит ключевые моменты, которые следует учесть при определении EDA-архитектуры данных на основе Apache Kafka.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники