 625
625 
Содержание
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch.
ETL-конвейер Flink CDC в YAML-файле
Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink CDC – инструмент интеграции потоковых данных, который позволяет пользователям описывать логику ETL-конвейера в YAML-файле, автоматически генерировать настраиваемые операторы фреймворка и отправлять задания на исполнение. Кроме того, Flink CDC поддерживает эволюцию схемы, преобразование данных, синхронизацию с хранилищами данных и семантику exact-once.
Чтобы показать, как определяется ETL-конвейер Flink CDC в YAML-файл, рассмотрим пример передачи изменений данных из PostgreSQL в Elasticsearch.
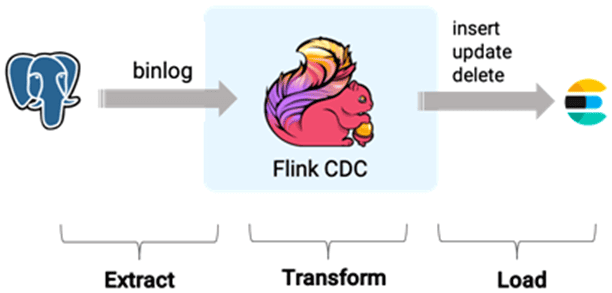
YAML-файл для Flink CDC выглядит так:
source:
type: postgres
name: postgresql-source #optional,description information
host: localhost
port: 5432
username: postgres_user
password: password
tables: mydb.public.orders
sink:
type: elasticsearch
name: Elasticsearch Sink
hosts: http://127.0.0.1:9092,http://127.0.0.1:9093
route:
- source-table: mydb.public.orders
sink-table: default_index
description: sync orders table to default_index
pipeline:
name: Sync PostgreSQL Database to Elasticsearch
parallelism: 2
checkpointing:
interval: 30000
mode: exactly_once
timeout: 60000
restart-strategy:
type: fixed-delay
attempts: 3
delay: 10000
В этом примере источником данных является PostgreSQL. Источник данных (source) используется для доступа к метаданным и чтения измененных данных из внешних систем.
Источник данных может читать данные из нескольких таблиц одновременно.
При подключении к внешним системам необходимо установить отношение сопоставления с ее объектами хранения. На это ссылается Table Id, который включает пространство имен namespace, схему данных schemaName и таблицу tableName. В этом примере из источника данных PostgreSQL отслеживаются изменения таблицы orders схемы public.
Приемник данных (sink) используется для применения изменений схемы и записи данных изменений во внешние системы. Он может записывать данные в несколько таблиц одновременно. Как и источник данных, приемник данных – обязательный раздел в конфигурационном YAML-файле. Поскольку в нашем примере приемником данных является Elasticsearch, который хранит данные в индексах, в необязательном разделе route указано название индекса default_index. Вообще route определяет правило сопоставления списка исходных таблиц и сопоставления с таблицей приемника. Чаще всего здесь задается слияние баз данных и таблиц, маршрутизация нескольких таблиц источника в одну и ту же таблицу приемника.
Помимо обязательных разделов с параметрами источника и приемника данных, в YAML-конфигурации обязателен раздел с описанием самого конвейера (pipeline):
- parallelism — уровень параллелизма;
- interval — интервал между контрольными точками для обеспечения отказоустойчивости;
- mode — режим гарантии обработки данных, например exactly_once;
- timeout — тайм-аут контрольной точки;
- restart-strategy — тип стратегии перезапуска, количество попыток и задержка между ними в миллисекундах.
Конвейер настроен с двумя параллельными задачами, обеспечивает точную доставку данных с регулярными контрольными точками и имеет стратегию перезапуска на случай сбоев с определенными интервалами и количеством попыток.
Конвейер может поддерживать эволюцию схемы данных, если в параметрах pipeline задано значение для schema.change.behavior: exception, evolve, try_evolve, lenient или ignore. Это позволяет синхронизировать изменения схемы данных источника с приемником, включая выполнение DDL-запросов, таких как создание новой таблицы, добавление новых столбцов, их переименование или изменение типов, а также удаление. Поведение определяется режимом, заданным для schema.change.behavior:
- exception — изменения схемы данных запрещены. Это полезно, когда нижестоящий приемник не должен обрабатывать какие-либо изменения схемы.
- evolve — оператор схемы CDC-конвейера применит все события изменения схемы источника к нижестоящему приемнику данных. Если попытка не удалась, из SchemaRegistry будет выдано исключение и запущен глобальный отказ.
- try_evolve — оператор схемы попытается применить события изменения схемы источника данных к нижестоящему приемнику. Но, если какие-то события изменения схемы не поддерживаются приемником, возникнет сбой, и SchemaOperator попытается преобразовать все последующие записи данных в случае несоответствия схемы. Из-за такого преобразования могут возникнуть потери в некоторых полях с несовместимыми типами данных.
- lenient (по умолчанию) — оператор схемы преобразует все события изменения источника данных к нижестоящему приемнику после их преобразования, чтобы гарантировать отсутствие потерь. Например, событие AlterColumnTypeEvent будет преобразовано в два отдельных события изменения схемы, включая RenameColumnEvent и AddColumnEvent: предыдущий столбец (с неизмененным типом) будет сохранен, а новый столбец (с новым типом) будет добавлен.
- Ignore — все события изменения схемы будут молча поглощаться SchemaOperator без попыток применения к нижестоящему приемнику. Это полезно, когда нижестоящий приемник не готов к изменениям схемы, но надо продолжать передавать данные из неизмененных столбцов таблицы источника.
Иногда синхронизировать все события изменения схемы источника с нижестоящим приемником нецелесообразно. Например, надо разрешить добавлять столбцы (событие AddColumnEvent), но запретить удалять их (событие DropColumnEvent). Это довольно распространенный сценарий, позволяющий избежать удаления существующих данных. Чтобы его реализовать, надо установить параметр include.schema.changes и exclude.schema.changes в разделе приемника (sink). Например, Следующая конфигурация YAML настроена на включение событий CreateTableEvent, связанных со столбцами, кроме DropColumnEvent:
sink: include.schema.changes: [create.table, column] # This matches CreateTable, AddColumn, AlterColumnType, RenameColumn, and DropColumn Events exclude.schema.changes: [drop.column] # This excludes DropColumn Events
Помимо раздела route, в YAML-конфигурацию ETL-конвейера Flink CDC можно добавить еще один необязательный раздел transform, чтобы удалить и/или изменить столбцы данных, а также отфильтровать ненужные данные во время процесса синхронизации. Параметры проекции и фильтрации при этом аналогичны SELECT и WHERE-операторам SQL соответственно. Например, чтобы добавить два вычисляемых столбца на основе таблицы orders в исходной базе данных mydb, можно определить правило преобразования так:
transform:
- source-table: mydb.public.orders
projection: id, order_id, UPPER(product_name) as product_name, localtimestamp as new_timestamp
description: append calculated columns based on source table
В этом преобразовании функция UPPER применяется к значению столбца product_name, что преобразует все символы в верхний регистр. Результат сохраняется в новом столбце с названием product_name. Также добавляется новый столбец new_timestamp, в который записывается текущее локальное время выполнения преобразования.
В правилах преобразования можно также использовать пользовательские функции (UDF), включая классы на Java, которые реализуют интерфейс org.apache.flink.cdc.common.udf.UserDefinedFunction, имеют открытый конструктор без параметров и хотя бы один публичный метод с именем eval.
Задав все необходимые и дополнительные параметры источника, приемника и конвейера данных, а также маршрутизации и преобразования в YAML-файле, можно отправить этот CDC-конвейер на выполнение в кластер Flink, используя CLI-интерфейс shell-оболочки Flink CDC (flink-cdc.sh). Например, сохранив ранее представленную конфигурацию как YAML-файл под названием postgresql-2-elastic.yaml, можно отправить задание в автономный кластер Flink с помощью командной строки:
./bin/flink-cdc.sh postgresql-2-elastic.yaml
После этого задание Flink будет скомпилировано и развернуто в кластере, вернув идентификатор задания и его описание, что будет отображено в веб-интерфейсе фреймворка.
В заключение отмечу, что задавать конфигурацию ETL-конвейера в YAML-файле довольно удобно. Примерно по этому же принципу работают коннекторы Flink, о которых я рассказывала здесь.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

