 752
752 
Содержание
Почему репортеры мониторинга системных метрик Flink, отправляющие данные в Prometheus, не решают проблемы предварительной обработки измерений с IoT-устройств, и как новый коннектор расширяет сферу применения фреймворка потоковой обработки.
Встроенные средства мониторинга системных метрик Flink
В декабре 2024 года вышел новый коннектор Apache Flink к Prometheus – популярной базе данных временных рядов, часто используемой для мониторинга системных метрик. Поскольку основным сценарием применения Prometheus является мониторинг, он отлично подходит для наблюдения за кластерами и заданиями Flink. Вообще, чтобы отправлять метрики во внешние системы, во Flink есть специальные объекты – репортеры, которые настраиваются в файле конфигурации. Эти репортеры будут созданы для каждого задания и менеджера задач при их запуске. Репортеры бывают двух типов:
- на основе идентификаторов, которые собирают плоскую строку, содержащую всю информацию о области действия и имя метрики, например, MyJobName.numRestarts.
- на основе тегов, которые определяют общий класс метрик, состоящий из логической области действия и имени метрики, например, numRestarts, и сообщают о конкретном экземпляре указанной метрики в виде тегов или переменных – набора пар ключ-значение, например, jobName=MyJobName.
Метрики экспортируются либо через push- или pull-уведомления. Push-репортеры обычно реализуют интерфейс Scheduled и периодически отправляют сводку текущих показателей во внешнюю систему. Pull-репортеры запрашиваются из внешней системы. В частности, org.apache.flink.metrics.prometheus.PrometheusReporter, репортер для Prometheus, является pull-репортером на основе тегов. Для его использования необходимо указать в настройках порт, который прослушивает экспортер Prometheus (по умолчанию 9249). Чтобы запускать несколько экземпляров репортера на одном хосте, например, когда один TaskManager размещен вместе с JobManager, рекомендуется использовать диапазон портов, например 9250-9260. Также можно необязательно включить настройку filterLabelValueCharacters, которая указывает, следует ли фильтровать символы значений меток. При ее включении все символы, не соответствующие паттерну [a-zA-Z0-9:_], будут удалены. Все переменные метрик Flink экспортируются в Prometheus в виде меток.
Также во Flink есть PrometheusPushGateway (org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter) – push-Репортер на основе тегов, который отправляет метрики в Pushgateway, чтобы Prometheus мог их считывать. Это полезно для мониторинга системных метрик эфемерных и пакетных заданий. Поскольку такие задания обычно имеют короткий жизненный цикл, т.е. существуют недостаточно долго, чтобы их можно было скопировать, они могут отправлять свои метрики в Pushgateway, который предоставляет их Prometheus. Тем не менее, Pushgateway не превращает Prometheus в систему мониторинга на основе push-уведомлений, т.к. не является агрегатором, распределенным счетчиком или хранилищем событий. Скорее Pushgateway работает как кэш метрик уровня сервиса и не имеет семантики, подобной statsd. Pushgateway предназначен для метрик уровня сервиса.
Таким образом, у Flink уже есть инструменты мониторинга. Возникает логичный вопрос – зачем тогда нужен новый коннектор? Ответим на него далее.
Зачем нужен новый коннектор к Prometheus
Цель нового коннектора Flink к Prometheus состоит не в самом мониторинге, а в использовании Flink в качестве препроцессора системных метрик из внешних источников, чтобы затем записать обработанный временной ряд непосредственно в Prometheus. Ведь, помимо мониторинга инфраструктуры, Prometheus также можно использовать как базу данных временных рядов общего назначения, например, для мониторинга IoT-устройств, smart-датчиков, интеллектуальных автомобилей, устройств потоковой передачи мультимедиа и прочих систем, которые непрерывно транслируют события или измерения. При этом данные мониторинга таких устройств отличаются от системных метрик инфраструктуры, поскольку часто имеют следующие проблемы:
- рассинхронизация событий, когда они поступают в порядке, не соответствующем хронологии их происхождения в реальном мире. Это случается из-за разных каналов передачи данных, которые вносят различные задержки. Для переупорядочивания таких событий можно использовать stateful-логику и отметок времени.
- высокая частота и мощность различных устройств, каждое из которых излучает сигналы несколько раз в секунду. Агрегирование по времени и измерениям может снизить частоту и мощность, сократив объем данных для анализа.
- отсутствие контекстной информации — необработанные события, отправляемые устройствами, часто не содержат контекстной информации для осмысленного анализа. Обогащение исходных событий с добавлением полезной справочной информации может улучшить качество анализа.
- шумы в измерениях датчика, например, когда GPS-трекер теряет соединение и сообщает о ложных позициях. Эти очевидные выбросы можно отфильтровать, чтобы упростить визуализацию и анализ данных.
Благодаря мощным возможностям потоковой обработки, Flink отлично подходит для устранения всех этих проблем. При этом обычная регистрация некоторых пользовательских метрик Flink и их отправка в Prometheus с помощью репортеров не подойдет по следующим причинам:
- размеры временных рядов заранее неизвестны и часто имеют высокую кардинальность даже после предварительной обработки. Например, deviceID – это идентификатор IoT-устройства, генерирующего измерение. Их может быть несколько тысяч. Используя обычный интерфейс Flink, пришлось бы регистрировать отдельную пользовательскую метрику для каждого устройства.
- Пользовательская метрика Flink будет отправлять Prometheus образец каждый фиксированный период, обычно с интервалом в несколько секунд, с помощью репортера Prometheus или PrometheusPushGateway . При обработке измерений с устройств надо контролировать эту частоту.
- Временные ряды представляют собой данные с точки зрения приложения Flink, а пользовательские метрики предназначены для наблюдения за тем, как Flink обрабатывает данные, а не для самих данных.
Чтобы исправить это, и был реализован новый коннектор, рассматриваемый в настоящей статье. Помимо предобработки данных, этот коннектор позволяет записывать данные временных рядов в Prometheus с помощью push-интерфейса Remote-Write в любом масштабе.
Хотя можно было реализовать приемник с нуля или использовать AsyncIO для вызова конечной точки Prometheus Remote-Write, разработка нового коннектора также обусловлена техническими ограничениям интерфейса Remote-Write, для которого нет высокоуровневого клиента. Также удаленная запись может быть неэффективной, если write-запросы не пакетированы и не распараллелены. Новый коннектор Prometheus устраняет эти ограничения. Как он устроен, рассмотрим далее.
Как работает новый коннектор
Prometheus — это размерная база данных временных рядов. Каждый временной ряд представлен серией выборок (метка времени и значение), идентифицированных набором уникальных меток ключ-значение. Метки представляют измерения с одной именованной меткой __name__. Набор меток представляет уникальный идентификатор временного ряда. Записи (выборки) — это просто значения типа double в порядке метки времени.
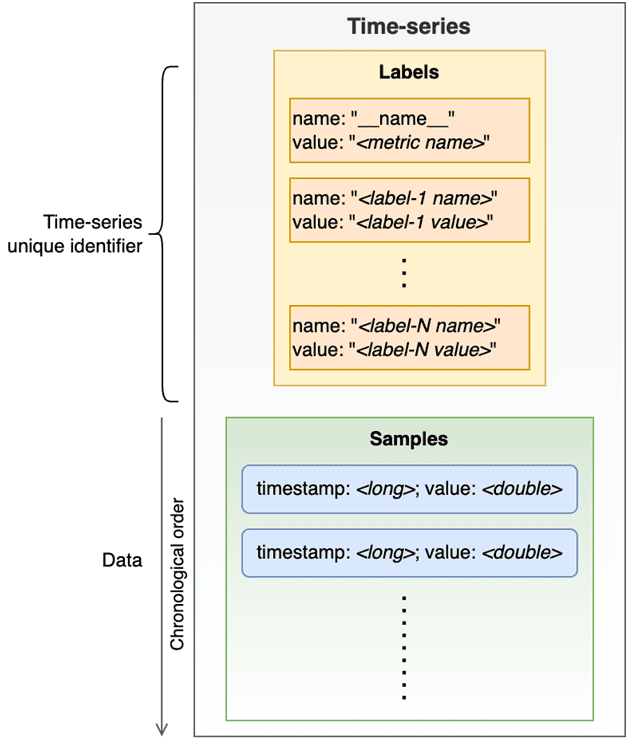
Термин временной ряд (TimeSeries) означает уникальная серия образцов в хранилище данных, идентифицированная уникальным набором меток, и блок WriteRequest. WriteRequest может содержать несколько элементов TimeSeries, относящихся к одному и тому же временному ряду хранилища данных. Полезная нагрузка протокола Wire, определенная спецификациями Remote-Write, позволяет пакетировать в одном запросе записи точки данных (выборки) из нескольких временных рядов и несколько выборок для каждого временного ряда в виде protobuf-сообщения, сжатого с помощью кодека Snappy. Спецификации не накладывают никаких ограничений на повторение временных рядов с тем же набором меток, но требуют строгого упорядочения принадлежности выборок к одному и тому же временному ряду по отметке времени и метке в едином временном ряде по имени.
Спецификации Remote-Write очень строги в отношении порядка меток внутри запроса, порядка принадлежности выборки к одному и тому же временному ряду и предотвращения повторных попыток отправки отклоненных запросов. В свою очередь, во Flink консистентность прежде всего: по умолчанию любая непредвиденная ошибка приводит к сбою потокового задания и перезапуску с последней контрольной точки. Prometheus же отдает приоритет доступности, а не строгой согласованности, ориентируясь на быстрый прием данных. Если запрос на запись содержит неправильно сформированные записи, весь запрос должен быть отклонен и не повторяться. При повторной попытке Prometheus продолжит отклонять некорректную запись. Кроме того, образцы, принадлежащие к одному и тому же временному ряду (с одинаковыми измерениями или метками), должны быть записаны в строгом порядке временных меток. Если данные недействительны, Prometheus отклонит запрос на запись, и задание Flink продолжится. Поэтому коннектор отклоняет весь некорректный запрос и продолжает работать со следующей записью. Спецификации не определяют стандартный формат ответа, и нет надежного способа автоматически идентифицировать и выборочно отбрасывать нарушающие образцы. Сам коннектор не вводит записи вне порядка. Если потеря данных неизбежна, коннектор информирует пользователя об этом. Каждый раз, когда запрос теряется, логируется предупреждение WARN, содержащий ответ конечной точки, который дает указание на проблему, и увеличивающиеся счетчики для количества потерянных образцов и запросов.
В коннекторе отсутствует встроенная проверка данных на стороне Flink, позволяющая отбрасывать или отправлять в очередь недоставленных сообщений невалидные записи, прежде чем приемник попытается выполнить запрос на запись, отклоненный Prometheus. Хотя это уменьшило бы потерю данных в случае некорректных данных, поскольку Prometheus отклоняет весь пакет независимо от количества ошибочных записей, такая проверка сильно снизила бы производительность. Поскольку это требует проверки каждой метки с помощью регулярных выражений и проверки порядка списка меток для каждой отдельной записи ввода. Кроме того, проверка порядка выборок не позволит переупорядочивать их без растягивания временного окна, что увеличит задержку. Впрочем, если необходимо, дата-инженер может самостоятельно реализовать изменение порядка выше по потоку от коннектора.
Хотя Flink позволяет работать с огромными потоками данных с высокой пропускной способностью, при взаимодействии с Prometheus надо учитывать способы масштабирования записи в этой базе данных временных рядов. Их два: объединение нескольких выборок в один запрос на запись и распараллеливание записей. Распараллеливание создает проблемы из-за требований к порядку, налагаемых Prometheus. Необходимо гарантировать, что все образцы, принадлежащие к одному и тому же временному ряду, определяемому как записи с идентичным набором меток, записаны одним и тем же потоком. Кроме того, максимальный запрос в реальном времени зафиксирован на уровне 1 для базового асинхронного приемника. Нарушение этих ограничений приводит к риску случайных неупорядоченных записей, даже если исходные данные изначально упорядочены. Коннектор справляется с этим, гарантируя, что записи никогда не будут повторяться асинхронно. Однако, пользователь несет ответственность за разделение данных до достижения приемника, чтобы сохранить правильный порядок.
Помимо ответственности за отправку в коннектор валидных данных, на стороне пользователя ответственность за правильное разделение данных в приложении Flink и выше по течению, чтобы сохранялся порядок по временным рядам. Невыполнение этого требования приведет к потере некоторых данных. Хотя обычно потеря нескольких точек данных, не является проблемой для мониторинга. Кроме того, некоторые бэкэнды Prometheus могут иногда терять записи, даже если они строго отправляются по порядку. Этот риск повышается при записи с высоким параллелизмом и увеличении пропускной способности до пределов ресурсов бэкэнда.
Коннектор реализует настраиваемую пакетную запись с сохранением порядка при повторных попытках и гарантиями at-most-once. Можно настроить параллелизм больше 1, стратегию повторных попыток для повторных ответов сервера и поведение при достижении лимита повторных попыток.
Коннектор имеет DataStream API и Java Sink, основанный на AsyncSinkBase, поскольку структура записи, которую ожидает Prometheus, является иерархической. Временной ряд содержит несколько меток, т.е. пар ключ-значение, которые образуют первичный ключ записи, и несколько выборов, которые содержат фактическое измерение значений и отметок времени. Кроме того, одна запись временного ряда может содержать сотни выборок. Этот тип структурированной записи нелегко представить в виде абстракции таблицы. Использование Table API потребовало бы сглаживания этой структуры, наложения разумного ограничения на количество меток и включения только одной выборки на запись. Хотя это не мешает приемнику объединять несколько записей в один Write-запрос, это ограничило бы гибкость и масштабируемость пользователя. Поэтому коннектор использует DataStream API.
В заключение отметим, что коннектор предоставляет универсальный интерфейс PrometheusRequestSigner для управления запросами и добавления заголовков. Это позволяет реализовать любую схему аутентификации, требующую добавления заголовков к запросу, например, API-ключи, авторизацию или токены подписи.
Таким образом, новый коннектор расширяет сферу применения Flink, позволяя использовать его как препроцессор системных метрик из внешних источников с последующей записью обработанных временных рядов в Prometheus.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

