 676
676 
Как написать конвейер обработки данных Apache Beam, задав цепочку преобразований в YAML-конфигурации: практический пример фильтрации и агрегации платежей из CSV-файла.
Пример разработки и запуска YAML-конвейера Apache Beam в Google Colab
Недавно я рассказывала про Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить в любой среде исполнения: Flink, Spark, AirFlow и пр., используя соответствующий движок (Runner). Сегодня покажу, как написать собственный конвейер без фактической разработки кода, декларативно описав преобразования с помощью YAML API этого фреймворка.
YAML API поддерживается в Beam с версии 2.52, но пока еще находится в стадии активной разработки, поэтому в нем присутствуют не все функции, которые есть в других SDK (Python, Java, Go, TypeScript). О том, как строить мультиязычные конвейеры обработки данных, используя преобразования из разных SDK, читайте в новой статье.
Конвейер в YAML API Beam представляет собой последовательность шагов, через которые проходят данные. Каждый шаг определяет определённое преобразование или действие над данными. Общая структура конвейера соответствует концепции ETL-процесса:
- сперва определяется источник данных (файл, база данных, потоковые платформы и пр.),
- затем над считанными из источника выполняются преобразования — операции обработки данных (фильтрация, агрегация, маппинг и т.д.);
- наконец, обработанные данные записываются в конечный приемник (файл, база данных, потоковые платформы и пр.).
Структура конвейера может быть сложной, с ветвлениями и параллельными ветками, и простой – линейной, что и рассмотрим сегодня. Последовательные преобразования данных, выстроенные в цепочку, где выход одного этапа служит входом для следующего, маркируются типом chain. И, в отличие от конвейеров с более сложной структурой для каждого преобразования не нужно явно указывать вход, заполняя поле input, т.к. каждая последующая трансформация автоматически связывается с выходом предыдущей.
В качестве примера рассмотрим линейный конвейер типа chain, который считывает данные о платежах из CSV-файла и считает LTV каждого клиента, фильтруя только платежи с типом Входящий и группируя по ИНН_Плательщика. Результаты запишем в новый CSV-файл.
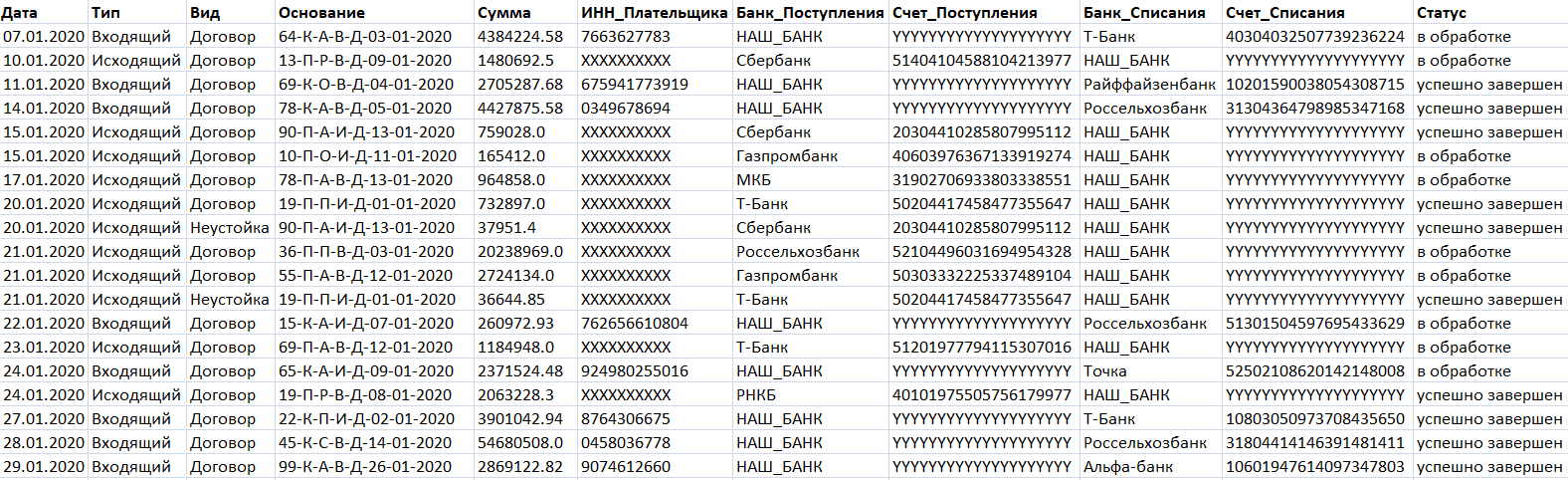
Этот CSV-файл с исходными данными я загрузила в текущую директорию Google Colab, где буду запускать конвейер Beam. Туда же загрузила YAML-файл, который будет описывать цепочку преобразований в Beam-конвейере.
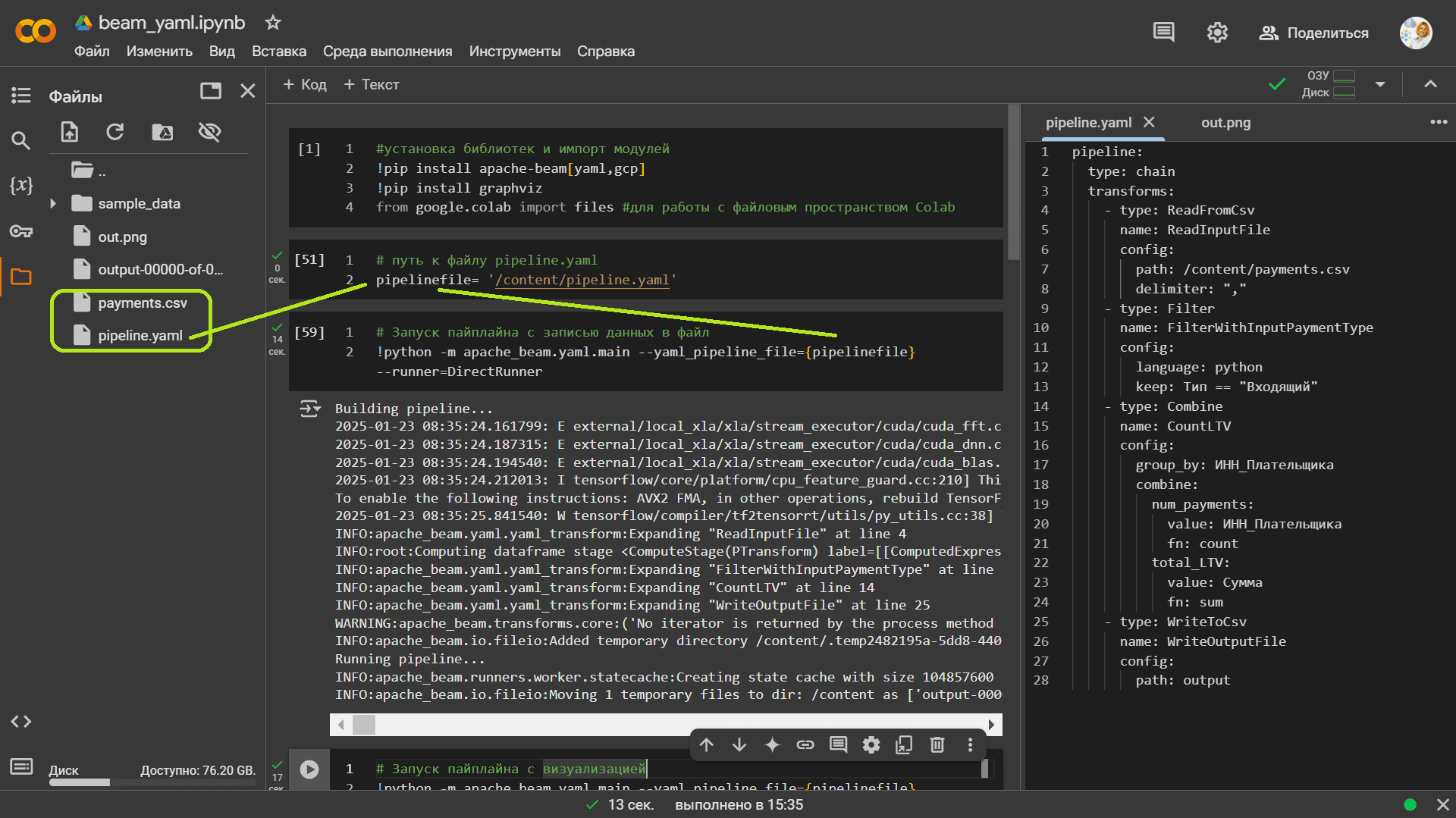
Конфигурация Beam-конвейера в YAML выглядит так:
pipeline:
type: chain
transforms:
- type: ReadFromCsv
name: ReadInputFile
config:
path: /content/payments.csv
delimiter: ","
- type: Filter
name: FilterWithInputPaymentType
config:
language: python
keep: Тип == "Входящий"
- type: Combine
name: CountLTV
config:
group_by: ИНН_Плательщика
combine:
num_payments:
value: ИНН_Плательщика
fn: count
total_LTV:
value: Сумма
fn: sum
- type: WriteToCsv
name: WriteOutputFile
config:
path: output
Чтобы запустить этот конвейер, надо сперва установить нужные библиотеки и импортировать модули:
#установка библиотек и импорт модулей !pip install apache-beam[yaml,gcp] !pip install graphviz from google.colab import files #для работы с файловым пространством Colab
Затем задать путь к файлу с конвейером:
# путь к файлу pipeline.yaml pipelinefile= '/content/pipeline.yaml'
И, наконец, можно запустить сам Beam-конвейер, используя прямой движок (DirectRunner), который выполняет пайплайн локально на текущей машине. Он не предназначен для масштабного распределённого выполнения, но полезен для разработки и отладки.
# Запуск пайплайна с записью данных в файл
!python -m apache_beam.yaml.main --yaml_pipeline_file={pipelinefile} --runner=DirectRunner
В результате выполнения получим выходной файл output-00000-of-00001.
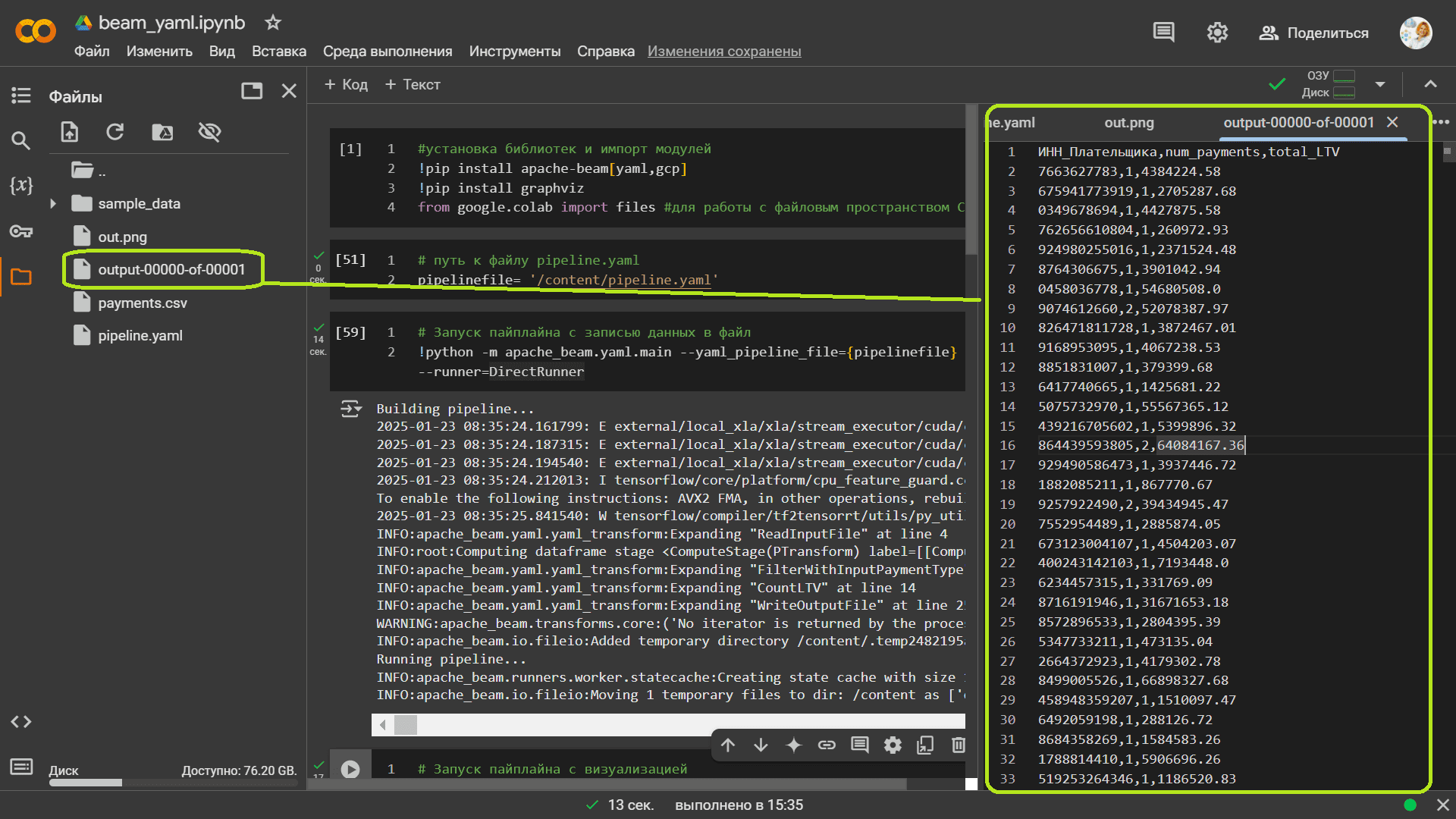
К названию выходного файла output, заданного в YAML-конфигурации конвейера, добавлены номер текущего шарда (начиная с 00000) и общее количество шардов 00001. Это всегда добавляется в Beam-конвейерах, поскольку имя файла формируется по шаблону шардирования выходных данных. В моем примере создан только один шард, поскольку данных немного и количество доступных рабочих ресурсов ограничено. Данные пишутся в единый файл, но при большем объеме и/или заданием нескольких разделителей, общее количество шардов было бы больше. Шардирование помогает эффективнее обрабатывать большие объемы данных, распределяя их между несколькими файлами и, при необходимости, параллельными процессами.
Чтобы визуально показать шаги выполнения конвейера, запустим его на другом движке – RenderRunner, который используется не для исполнения пайплайна, а для его визуализации. Он позволяет создать графическое представление структуры пайплайна и сохранить в файле. Для этого запустим команду:
# Запуск пайплайна с визуализацией
!python -m apache_beam.yaml.main --yaml_pipeline_file={pipelinefile} --runner=apache_beam.runners.render.RenderRunner \
--render_output=out.png
В результате получим картинку шагов выполнения Beam-конвейера в файле out.png.
Полученная картинка показывает последовательность блоков, соединённых стрелками, которые указывают направление потока данных. Каждый блок соответствует конкретной трансформации или действию над данными, демонстрируя, как данные проходят через различные этапы пайплайна для достижения конечной цели обработки.
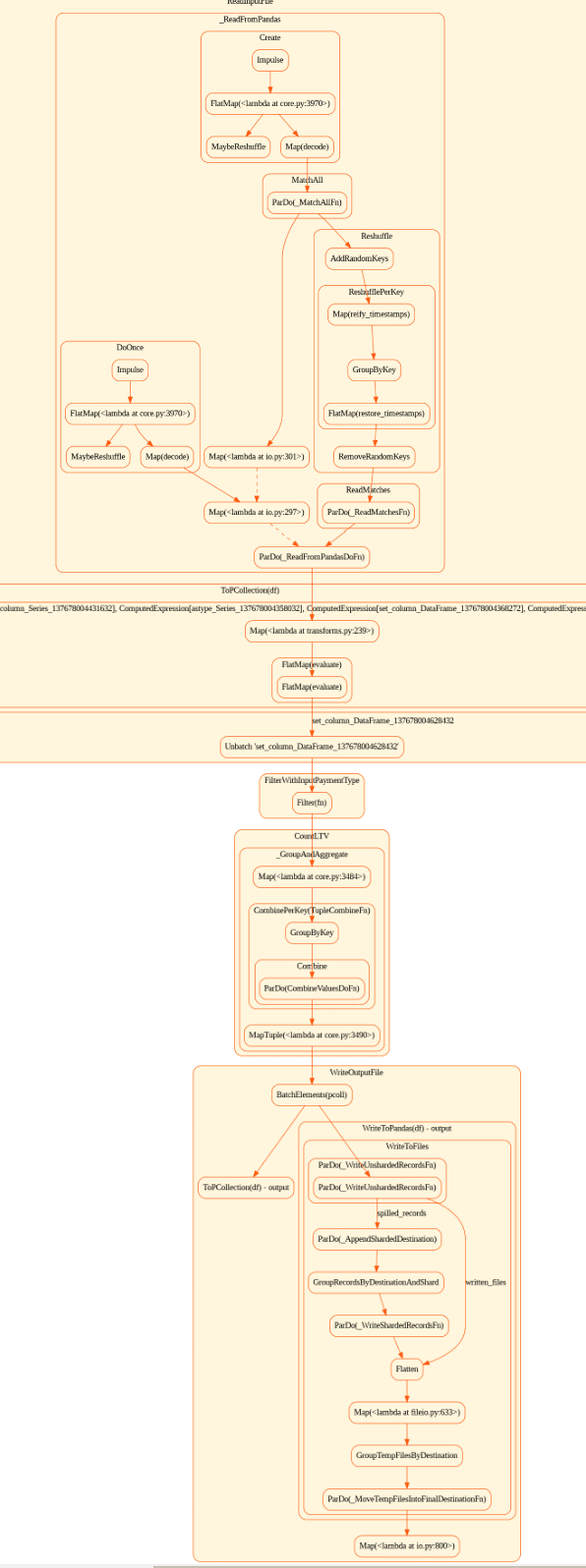
Таким образом, Apache Beam позволяет создавать масштабируемые и гибкие конвейеры для обработки больших объёмов данных, используя декларативные описания в виде YAML-конфигураций. Это существенно снижает порог входа в технологию, а также упрощает управление и версионирование процессов обработки данных.
Узнайте больше про Apache Beam на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

