Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных.
Что такое Apache Beam и зачем он нужен
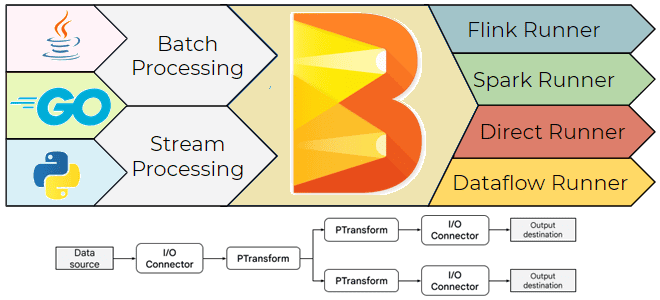
Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения конвейера обработки данных, которое можно запустить в любой среде исполнения: Flink, Spark, AirFlow и пр. Это можно сделать с помощью Apache Beam – унифицированной модели для определения пакетных и потоковых конвейеров параллельной обработки данных. Она изолирует разработчика от низкоуровневых деталей распределенной обработки, таких как координация отдельных рабочих, сегментирование наборов данных и других подобных задач. Запустить конвейер Apache Beam без изменения кода можно в разных средах: Flink, Spark, Google Cloud Dataflow, локальный компьютер и пр. Исполнитель запускает конвейер Beam, используя Runner – выбранный пользователем механизм обработки данных.
Конвейер — это граф преобразований, применяемых к коллекциям данных. В Apache Beam коллекция называется PCollection, а преобразование называется PTransform. Ограниченные коллекции относятся к пакетной обработке данных: они имеют известный фиксированный размер. В неограниченных коллекциях используются потоковые конвейеры, обрабатывая данные по мере их поступления. Подробнее про обработку PCollection читайте в нашей новой статье. Для подключения к сторонним системам Apache Beam предоставляет соответствующие коннекторы: source для чтения и sink для записи.
Apache Beam поддерживает оконные агрегации, позволяя делить коллекции на окна по временным меткам отдельных элементов. Триггер определяет, когда следует агрегировать результаты каждого окна. Полный контроль над агрегацией коллекций входных данных достигается благодаря низкоуровневым примитивам – обратным вызовам и таймерам для каждого ключа агрегации. Каждый уникальный ключ соответствует набору связанных с ним значений, что позволяет эффективно обрабатывать и агрегировать данные по этим ключам. Например, ключом может быть идентификатор пользователя, категория продукта или любое другое значение, по которому вы хотите структурировать и анализировать ваши данные. Также в конвейерах Beam учитывается задержка и неравномерность поступления потоковых данных благодаря водяным знакам (watermark), подобно тому, как это работает в Apache Flink и Spark. Еще Beam позволяет делать контрольные точку обработки элемента, чтобы исполнитель разделил оставшуюся работу, обеспечив дополнительный параллелизм.

Таким образом, Apache Beam предоставляет высокоуровневый API, который упрощает разработку сложных конвейеров обработки данных, обеспечивая масштабируемость и гибкость. Он позволяет абстрагироваться от конкретных исполнителей, выбирая наиболее подходящую инфраструктуру для конкретных задач, что делает этот фреймворк универсальным инструментом для разработки MVP аналитических приложений, ML-систем, ETL-конвейеров и прочих задач стека Big Data.
Вспомнив, что такое Apache Beam и чем он хорош, далее рассмотрим практический пример получения семантического ядра веб-страницы, включая парсинг ее содержимого, извлечение русскоязычных слов и их сортировку по количеству упоминаний. Для этого напишем простой Beam-конвейер на Python и запустим его в Google Colab.
Практический пример парсинга веб-страницы на Python
Как обычно, сначала надо установить необходимые библиотеки и импортировать модули. Помимо самого Beam, нужны пакеты для выполнения HTTP-запросов, работы с регулярными выражениями, парсинга HTML-страниц и обработки естественного языка.
#установка библиотек !pip install apache-beam requests beautifulsoup4 pymorphy2 nltk from apache_beam.options.pipeline_options import PipelineOptions # импорт опций конфигурации для пайплайна Apache Beam import requests #для выполнения HTTP-запросов import re #для работы с регулярными выражениями from bs4 import BeautifulSoup #для парсинга HTML и XML документов from pymorphy2 import MorphAnalyzer #для морфологического анализа слов import nltk #для обработки естественного языка from nltk.corpus import stopwords #список стоп-слов из NLTK
Загрузим так называемые стоп-слова, которые часто встречаются в языке, но при этом не несут значимой смысловой нагрузки для анализа текста. Например, предлоги, союзы, местоимения, частицы. В обработке естественного языка (NLP) стоп-слова удаляются из текста перед проведением дальнейшего анализа. Это помогает сократить объем данных и сосредоточиться на более значимых словах, которые могут лучше отражать содержание и смысл текста. Использование списка стоп-слов позволяет автоматизировать процесс фильтрации таких нерелевантных слов и повысить эффективность последующих этапов обработки текста.
# загрузка списка русских стоп-слов
nltk.download('stopwords')
russian_stopwords = set(stopwords.words('russian'))
# инициализация морфологического анализатора
morph = MorphAnalyzer()
Напишем пользовательский класс обработки веб-страницы, используя DoFn – абстрактный класс Apache Beam для создания пользовательских функций обработки элементов в конвейере данных. В пользовательском классе, наследуемом от beam.DoFn, определяются особенности обработки каждого элемента входного PCollection. DoFn позволяет эффективно обрабатывать большие объемы данных параллельно, используя возможности распределенных вычислений фреймворка. Также DoFn поддерживает сложные сценарии обработки, такие как создание боковых выходов (side outputs) или управление состояниями и таймерами для обработки событий во времени. Обычно DoFn часто используется вместе с такими преобразованиями, как ParDo, которое применяет функцию DoFn ко всем элементам PCollection.
# класс для обработки URL
class FetchPage(beam.DoFn):
def process(self, element):
url = element
try:
response = requests.get(url)
response.raise_for_status()
text = response.text
# Парсим HTML и извлекаем видимый текст
soup = BeautifulSoup(text, 'html.parser')
# Удаляем нежелательные теги, такие как скрипты и стили
for script_or_style in soup(['script', 'style', 'header', 'footer', 'nav', 'aside']):
script_or_style.decompose()
visible_text = soup.get_text(separator=' ')
# Извлекаем только русские слова, игнорируя регистр и специальные символы
words = re.findall(r'\b[а-яё]+\b', visible_text.lower(), re.UNICODE)
for word in words:
# Пропускаем стоп-слова
if word in russian_stopwords:
continue
# Лемматизируем слово
lemma = morph.parse(word)[0].normal_form
yield lemma
except requests.RequestException as e:
# Обработка ошибок по необходимости
pass
Наконец, напишем и запустим cам конвейер:
# функция run для построения и запуска пайплайна Apache Beam
def run():
# Явно задаём URL страницы
url = 'https://babok-school.ru/'
# Опции пайплайна
pipeline_options = PipelineOptions()
with beam.Pipeline(options=pipeline_options) as p:
(
p
# Создаём PCollection с единственным элементом - URL
| 'Create URL' >> beam.Create([url])
# Загружаем содержимое страницы и извлекаем леммы
| 'Fetch and Extract Lemmas' >> beam.ParDo(FetchPage())
# Группируем по леммам и считаем количество упоминаний
| 'Count Lemmas' >> beam.combiners.Count.PerElement()
# Собираем все пары (лемма, количество) в список
| 'To List' >> beam.combiners.ToList()
# Сортируем список по количеству упоминаний в порядке убывания
| 'Sort Results' >> beam.Map(lambda kvs: sorted(kvs, key=lambda x: x[1], reverse=True))
# Форматируем отсортированные результаты для вывода
| 'Format Results' >> beam.FlatMap(lambda kvs: [f'{kv[0]}: {kv[1]}' for kv in kvs])
# Выводим результаты в консоль
| 'Print Results' >> beam.Map(print)
)
# запуск программы
if __name__ == '__main__':
run()
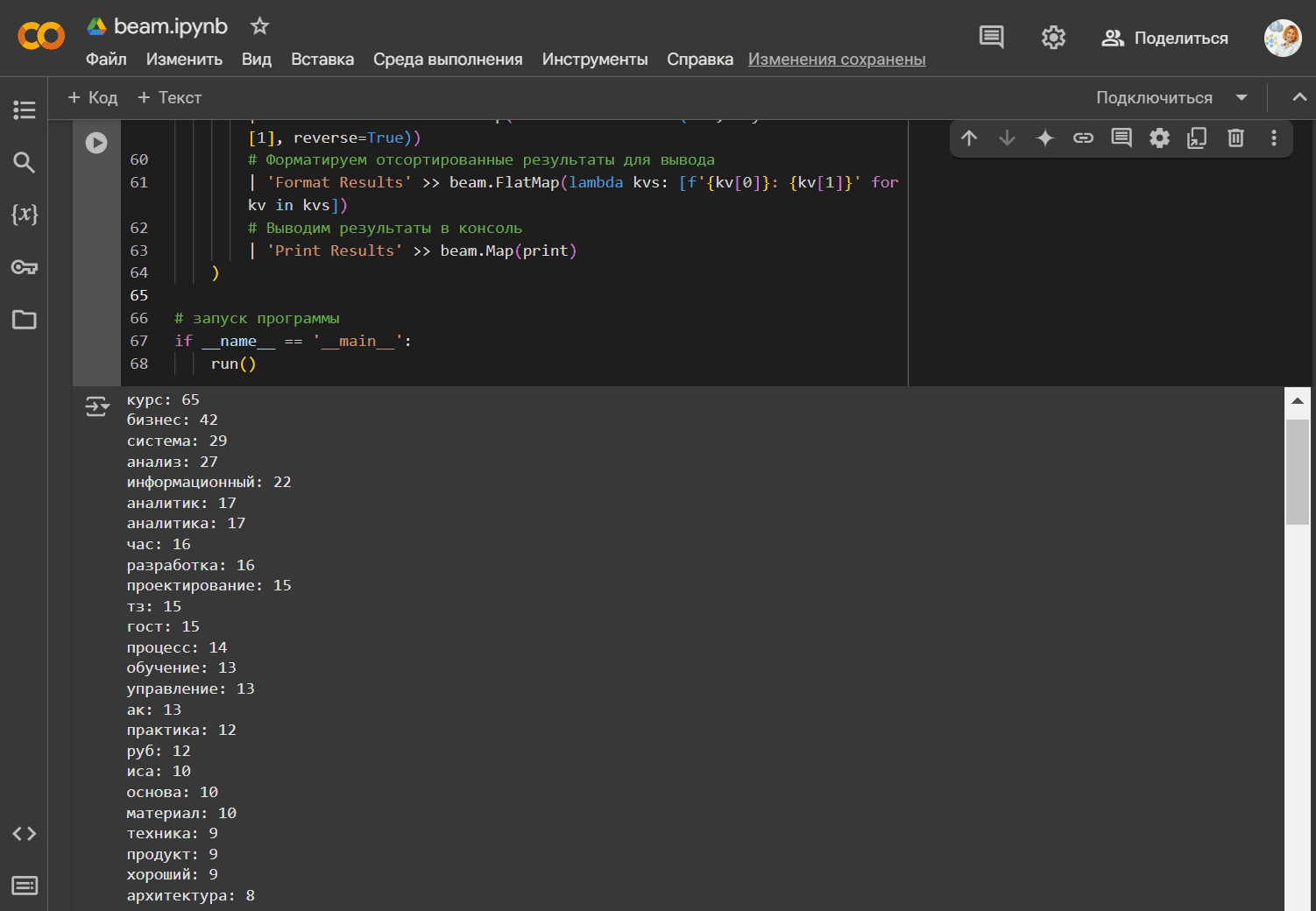
Выбрав в качестве анализируемой страницы главную страницу нашей Школы прикладного бизнес-анализа и проектирования информационных систем, запустим Beam-конвейер. Отсортированные в порядке убывания количества упоминаний слова позволяют сформировать семантическое ядро рассмотренного сайта: курсы по бизнес-анализу и проектированию информационных систем.
В заключение еще раз отметим, что Apache Beam можно запускать не только на локальной машине, что удобно для разработки, тестирования и отладки, но и в кластере. Например, исполнительный механизм FlinkRunner используется для выполнения Beam-пайплайнов на кластерах Apache Flink, обеспечивая масштабируемую обработку данных. Как это работает, читайте в новой статье. А SparkRunner позволяет запускать Beam-пайплайны на кластерах Apache Spark. Также можно работать с DataflowRunner – полностью управляемом сервисе от Google Cloud для обработки потоковых и пакетных данных. Некоторые облачные провайдеры также предлагают собственные решения или интеграции для запуска Apache Beam, позволяя использовать преимущества их инфраструктуры.
Разумеется, окончательный выбор исполнительного механизма и среды для запуска Beam-конвейеров зависит от требований и ограничений проекта, объемов обрабатываемых данных, существующей инфраструктуры и корпоративного техрадара. Для гибридных или многоплатформенных решений обработки больших объемов данных подойдет FlinkRunner или SparkRunner.
Кроме Python SDK, Beam также имеет YAML API, позволяя декларативно описать конвейер обработки данных. Как это сделать, читайте в новой статье.
Освойте использование Apache Beam на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

