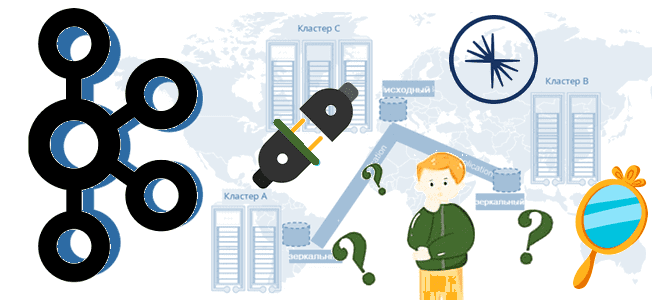
Продолжая разговор про межрегиональную репликацию Apache Kafka, сегодня рассмотрим 4 способа ее реализации: мультирегиональный кластер, MirrorMaker 2, Cluster Linking в Confluent Server и Confluent Replicator. Чем георепликация Kafka с MirrorMaker 2 отличается от решений Confluent и что выбирать для различных сценариев. Мультирегиональный кластер Confluent Геораспределенная репликация реплицирует данные по кластерам...
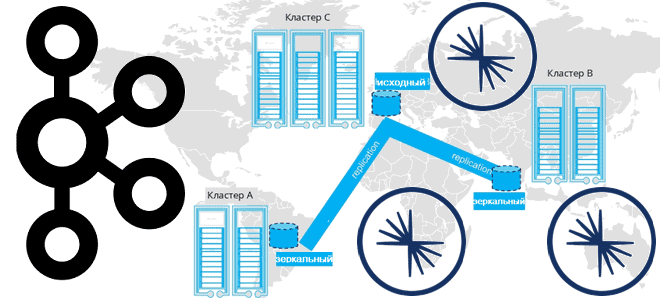
Недавно мы писали про мультирегиональную репликацию Apache Kafka. Сегодня рассмотрим, как выполнить геораспределенную репликацию с помощью Cluster Linking в Confluent Server и Kafka Connect с Confluent Replicator. Cluster Linking для Apache Kafka Связанные кластеры представляют собой 2 или более кластера в разных географических регионах. В отличие от топологии растянутого кластера,...

Как спроектировать DAG и выбрать способ обмена данными между задачами, где определить подключения и запросы к БД и что поможет избежать ада Python-зависимостей при использовании Apache AirFlow. Сегодня я расскажу своем личном опыте наступания на грабли при работе с этим оркестратором batch-процессов и уроках, которые из этого вынесла. 5 советов...
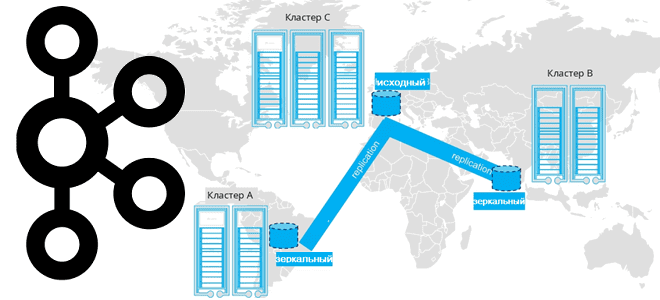
Какую топологию может иметь кластер Apache Kafka при межрегиональной репликации по нескольким ЦОД и как это реализовать. Чем брокеры-наблюдатели отличаются от подписчиков в Confluent Server и при чем здесь конфигурация подтверждений acks в приложении-продюсере. Принципы репликации данных в Apache Kafka Будучи средством интеграции информационных систем в режиме реального времени, Apache...
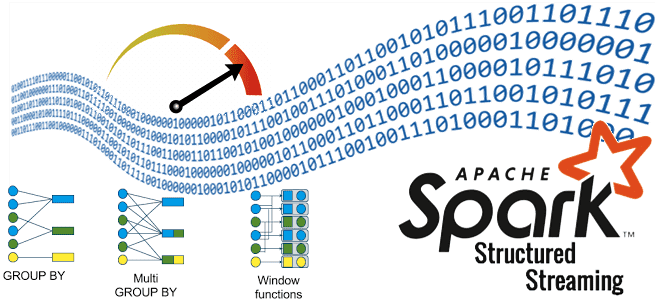
Как выполнение нескольких stateful-операторов в одном потоке снижает стоимость обработки данных: возможности и ограничения Spark Structured Streaming. Про водяные знаки и состояния в потоковой передаче событий. Stateful-операторы и водяные знаки в потоковой обработке данных Благодаря распределенной обработке микропакетов в памяти Spark Structured Streaming позволяет обрабатывать огромные объемы данных очень быстро....
Одной из причин быстрой работы ClickHouse являются движки таблиц, оптимизированные на конкретные операции с данными. Сегодня рассмотрим, чем они отличаются и какой из них выбирать для разных сценариев. Движки БД ClickHouse Прежде чем разбираться с движками таблиц ClickHouse, вспомним само назначение этого термина. Движок БД или механизм хранения отвечает за...

Что необходимо реализовать в собственном процессоре, написанном на Python, чтобы запускать его в Apache NiFi. Классы и методы для настройки свойств, а также отношения и состояния жизненного цикла. Классы и методы для настройки свойств Предустановленные обработчики данных или процессоры (processor) Apache NiFi, написанные на Java, можно настроить прямо в GUI,...

Какие инфраструктурные компоненты самые дорогие в эксплуатации популярной платформы потоковой передачи сообщений и как снизить затраты на сетевые ресурсы и хранилища данных при использовании Apache Kafka. TCO для Apache Kafka: что учитывать в расчете затрат Поскольку Apache Kafka используется для интеграции информационных систем в режиме реального времени, она становится критически...
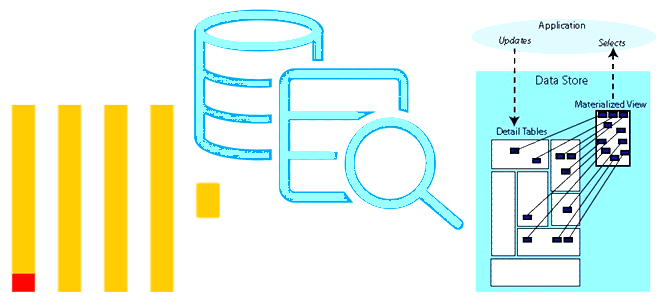
Чем материализованное представление в ClickHouse отличается от обычного, зачем нужны LIVE-представления и как их использовать. Примеры SQL-запросов с VIEW для самой популярной колоночной аналитической СУБД. Представления vs словари в ClickHouse Поскольку ClickHouse, как типовая колоночная СУБД, используется для аналитической обработки огромных объемов данных в реальном времени, вопрос ускорения вычислений для...

Продолжая разговор про рассмотренные в прошлой статье принципы взаимодействия процессов Python с Java, на которой написан Apache NiFi, сегодня разберем, как использовать это на практике. Пишем свои процессоры, используя классы FlowFileTransform и RecordTransform. Python-процессор Apache NiFi на базе FlowFileTransform Хотя Apache NiFi предоставляет более 300 процессоров для вычислительных операций и...