Что такое квоты в Apache Kafka и как этот механизм позволяет управлять ресурсами брокера, предупреждая DDOS-атаки от слишком активных потребителей и продюсеров. Разбираемся с типами клиентских квот, их конфигурациями и принципами работы.
Квоты клиента и пользователя в Apache Kafka
Чтобы управлять ресурсами брокера, кластер Kafka может применять квоты на запросы от клиентов. Для этого выделяют два типа клиентских квот для каждой группы клиентов:
- квоты пропускной способности сети, которые определяют пороги скорости передачи данных;
- квоты скорости запросов, которые определяют пороговые значения использования ЦП в процентах от сетевых потоков и потоков ввода-вывода.
Квоты нужны для предупреждения чрезмерного потребления ресурсов, поскольку продюсеры могут производить очень большие объемы данных, а потребители — генерировать запросы с очень высокой скоростью. Слишком высокая скорость работы клиентского приложения (продюсера или потребителя) может монополизировать ресурсы брокера, вызывать насыщение сети и привести к DOS-атаке других клиентов и самих брокеров. Наличие квот защищает от этих проблем, особенно в мультиарендных кластерах, где поведение нескольких клиентов может ухудшить работу всего кластера. Фактически, при запуске Kafka как сервиса механизм квот позволяет применять ограничения API в соответствии с согласованным контрактом.
Идентификацией клиентов Kafka является субъект пользователя, который представляет пользователя, прошедшего проверку подлинности, в защищенном кластере. В кластере, поддерживающем неаутентифицированных клиентов, субъект-пользователь представляет собой группу неаутентифицированных пользователей, выбранных брокером с помощью настраиваемого файла PrincipalBuilder. Логическая группа клиентов со значимым именем, выбранным клиентским приложением, имеет одинаковый идентификатор (client-id). Кортеж (пользователь, идентификатор клиента) определяет безопасную логическую группу клиентов, которые совместно используют как участника-пользователя, так и идентификатор клиента.
Квоты могут применяться к пользователям, идентификаторам клиентов, а также группа этих объектов (группа пользователей или идентификаторов клиентов). Для данного соединения применяется наиболее конкретная квота, соответствующая соединению. Все соединения группы квот используют квоту, настроенную для группы. Например, если пользователь test-user с идентификатором клиента test-client имеет квоту на публикацию 10 МБ/с, она распределяется между всеми экземплярами приложения-продюсера пользователя test-user с клиентом test-client. Квоту по умолчанию можно переопределить на любом уровне аналогично переопределению конфигурации журнала для каждого топика. Переопределение квоты пользователя и записывается в ZooKeeper в /config/users, а переопределение квоты идентификатора клиента записывается в /config/clients. Эти переопределения считываются всеми брокерами и вступают в силу немедленно, позволяя изменять квоты без последовательного перезапуска всего кластера. Квоты по умолчанию для каждой группы также могут динамически обновляться с использованием того же механизма. Порядок приоритета для конфигурации квоты выглядит следующим образом:
- /config/users/<user>/clients/<client-id>
- /config/users/<user>/clients/<default>
- /config/users/<user>
- /config/users/<default>/clients/<client-id>
- /config/users/<default>/clients/<default>
- /config/users/<default>
- /config/clients/<client-id>
- /config/clients/<default>
Квоты пропускной способности сети
Квоты пропускной способности сети определяются как пороговое значение скорости передачи данных для каждой группы клиентов, разделяющих квоту. По умолчанию каждая уникальная группа клиентов получает фиксированную квоту, выражаемую в количестве байтов в секунду, настроенную кластером. Эта квота определяется отдельно для каждого брокера. Каждая группа клиентов может публиковать или потреблять максимум X байтов в секунду на брокера.
Квоты скорости запросов определяются как процент времени, в течение которого клиент может использовать потоки ввода-вывода обработчика запросов и сетевые потоки каждого брокера в пределах окна квоты. Квота n% представляет n% одного потока, поэтому квота выходит за пределы общей емкости, рассчитываемой как сумма количества потоков ввода/вывода и сетевых потоков, умноженная на 100%, т.е. ((num.io.threads + num.network.threads) * 100)%. Каждая группа клиентов может использовать общий процент до n% по всем потокам ввода-вывода и сетевым потокам в окне квоты перед регулированием. Поскольку количество потоков, выделенных для операций ввода-вывода и сетевых потоков, обычно зависит от количества ядер, доступных на узле брокера, квоты скорости запросов представляют собой общий процент ЦП, который может использоваться каждой группой клиентов, разделяющих квоту.
По умолчанию каждая уникальная группа клиентов получает фиксированную квоту, настроенную кластером. Эта квота определяется отдельно для каждого брокера. Каждый клиент может использовать эту квоту для каждого брокера. Это лучше, чем фиксированная ширина полосы пропускания кластера для каждого клиента, т.к. не требует механизма распределения использования клиентских квот между всеми брокерами.
Брокер сначала вычисляет величину задержки, необходимую для того, чтобы клиент-нарушитель оказался в рамках своей квоты, и немедленно возвращает ответ с задержкой. В случае запроса на выборку ответ не будет содержать никаких данных. Затем брокер отключает канал для клиента, чтобы больше не обрабатывать запросы от клиента, пока не закончится задержка. Получив ответ с ненулевой продолжительностью задержки, клиент Kafka также воздержится от отправки дальнейших запросов брокеру во время задержки. Таким образом, механизм квотирования эффективно блокирует запросы от чрезмерно производительного клиента с обеих сторон.
Эта последовательность на UML-диаграмме sequence будет выглядеть следующим образом:
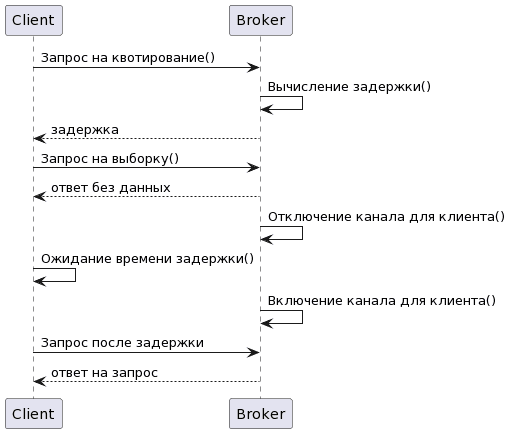
Скрипт PlantUML для этой диаграммы:
@startuml participant Client participant Broker Client -> Broker: Запрос на квотирование() Broker -> Broker: Вычисление задержки() Broker --> Client: задержка Client -> Broker: Запрос на выборку() Broker --> Client: ответ без данных Broker -> Broker: Отключение канала для клиента() Client -> Client: Ожидание времени задержки() Broker -> Broker: Включение канала для клиента() Client -> Broker: Запрос после задержки Broker --> Client: ответ на запрос @enduml
Даже со старыми реализациями клиентов, которые не учитывают задержку ответа от брокера, обратное давление, применяемое брокером путем отключения канала сокета, все еще может справиться с регулированием слишком высокопроизводительных клиентов. Те клиенты, которые отправили дальнейшие запросы в регулируемый канал, получат ответы только после того, как задержка закончится. Скорость передачи данных и использование потоков измеряются в нескольких небольших временных окнах, например, 30 окон по 1 секунде, для быстрого обнаружения и исправления нарушений квот. Как правило, длительные окна измерения, такие как 10 окон по 30 секунд каждое, приводит к большим вспышкам трафика, за которыми следуют длительные задержки, что негативно отражается на взаимодействии с пользователем.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники