 1056
1056 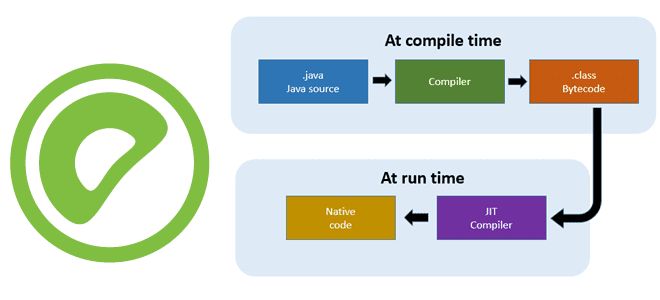
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных.
Что такое JIT-компиляция
Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В отличие от традиционной компиляции, которая генерирует машинный код заранее, на этапе компиляции исходного кода, JIT позволяет компилятору адаптироваться к специфическим условиям выполнения программы, таким как ввод-вывод и динамическое изменение данных. Также это повышает производительность программных систем, использующих байт-код. Это достигается благодаря адаптивной оптимизации и динамической рекомпиляции.
Интерпретация и JIT-компиляция особенно хорошо подходят для динамических языков программирования, и могут быть применены как ко всей программе, так и к её отдельным частям. Большинство реализаций JIT имеют последовательную структуру: сначала приложение компилируется в байт-код виртуальной машины среды исполнения (AOT-компиляция), а потом JIT компилирует байт-код непосредственно в машинный код. Хотя это может занимать дополнительное время при запуске приложения, в результате повышается его производительность. Так достигается высокая скорость выполнения по сравнению с интерпретируемым байт-кодом за счёт увеличения потребления памяти для хранения результатов компиляции и затрат времени на компиляцию.
JIT компилирует байт-код непосредственно в машинный код, что выполняется быстрее, чем из исходного кода. Байт-код лучше переносится, чем машинный код, и среда может контролировать его выполнение после компиляции. Компиляторы из байт-кода в машинный код легче в реализации, так как большинство работы по оптимизации уже было проделано компилятором. Благодаря своему динамическому характеру и оптимизациям во время исполнения, JIT-компиляция может быть более производительной, чем статическая компиляция. Интерпретация и JIT-компиляция особенно хорошо подходят для динамических языков программирования, когда среда исполнения справляется с поздним связыванием типов и гарантирует безопасность исполнения.
JIT-компиляция может выполняться непосредственно для целевого процессора и операционной системы, где запущено приложение. Например, JIT может использовать векторные SSE2 расширения процессора, если тот их поддерживает. Среда собирает статистику о работающей программе, чтобы применять оптимизации, включая встраивание библиотечных функций в код, без потери преимуществ динамической компиляции и без накладных расходов, присущих статическим компиляторам и компоновщикам. Наконец, JIT позволяет использовать кэш более эффективно за счет упрощенного перестраивания кода на лету с помощью оптимизаций.
Примером использования JIT-компиляции может служить текстовый редактор, который на лету компилирует регулярные выражения для более быстрого поиска по тексту. JIT-компиляция также используется в реализациях Java (JRE), JavaScript, .NET Framework, и в одной из реализаций Python — PyPy. Большинство реализаций JIT имеют последовательную структуру: сначала приложение компилируется в байт-код виртуальной машины среды исполнения (AOT-компиляция), а потом JIT компилирует байт-код непосредственно в машинный код. Хотя так при запуске приложения тратится лишнее время, это потом компенсируется более быстрой работой.
Обычно задержки при запуске JIT-компилятора складываются из временных расходов на загрузку среды и компиляции приложения в машинный код. Чем лучше и чем больше оптимизаций выполняет JIT, тем больше получается задержка. Поэтому разработчикам JIT приходится искать компромисс между качеством генерируемого кода и временем запуска.
Кроме качества кода и времени запуска, еще одним узким местом JIT-компилятора являются задержка системы ввода-вывода. Например, JAR-архив среды выполнения, файл rt.jar, который содержит классы начальной загрузки, в JVM имеет размер несколько десятков МБ, и поиск метаданных в нём занимает достаточно много времени.
Также имеет место вопрос безопасности и возможных уязвимостей, поскольку JIT включает в себя компиляцию исходного кода или байт-кода в машинный код и его выполнение. Впрочем, среда может контролировать выполнение байт-кода после компиляции, поэтому приложение может быть запущено в песочнице, что исключает некоторые угрозы безопасности. Справедливости ради стоит отметить, что для нативных программ тоже есть такая возможность, но она сложнее реализуется.
Еще одним аспектом потенциальной уязвимости в JIT-компиляции является запись результата в память и его немедленное исполнение без промежуточного сохранения на диск. В современных архитектурах для повышения безопасности произвольные участки памяти не могут быть исполнены как машинный код. Для корректного запуска регионы памяти должны быть предварительно помечены как исполняемые, при этом для большей безопасности флаг исполнения может ставиться только после снятия флага разрешения записи (защита W^X).
Вспомнив, что такое JIT-компиляция, далее рассмотрим, как эта технология используется в Greenplum.
Применение в Greenplum
В Greenplum JIT-компиляция реализуется как процесс преобразования интерпретируемой оценки программы в нативную программу во время выполнения. Например, вместо использования кода общего назначения, который может вычислять произвольные SQL-выражения для оценки конкретного оператора, такого как WHERE a.col=3, можно сгенерировать функцию, специфичную для этого выражения, которая будет более быстро выполняться ЦП.
Greenplum и PostgreSQL используют LLVM (Low Level Virtual Machine), проект программной инфраструктуры для создания компиляторов и сопутствующих им утилит, для JIT-компиляции. Этот компонент включен во все RPM-дистрибутивы Greenplum. При сборке Greenplum из исходного кода поддержку JIT-компиляции следует включить самостоятельно, указав опцию —with-llvm.
JIT-компиляцию можно использовать со всеми оптимизаторами Greenplum: Postgres Planner и GPORCA, о котором мы писали здесь. Поскольку GPORCA и Postgres Planner используют разные алгоритмы и значения расчетных затрат выполнения SQL-запросов, пороговые значения JIT зависят от используемого компилятора. Сегодня JIT-реализация в Greenplum поддерживает ускорение вычисления выражений и операций преобразования кортежей, называемых деформациями. Деформация кортежа — это процесс преобразования кортежа на диске в его представление в памяти. Его можно ускорить, создав функцию, специфичную для макета таблицы и количества извлекаемых столбцов. Оценка выражений используется для оценки предложений WHERE, целевых списков, агрегатов и прогнозов. Эту операцию можно ускорить, генерируя код, специфичный для каждого случая.
Расширяемость Greenplum, которая позволяет определять новые типы данных, функции, операторы и другие объекты базы данных подразумевает некоторые накладные расходы, например, из-за вызовов функций. Чтобы уменьшить эти накладные расходы, JIT может использовать встроенную компиляцию, чтобы поместить тела небольших функций в использующие их выражения. Так можно оптимизировать значительный процент накладных расходов.
LLVM поддерживает оптимизацию сгенерированного кода. Некоторые оптимизации достаточно дешевы, и их можно выполнять каждый раз заново при использовании JIT, а другие выгодны только для длительных SQL-запросов.
JIT-компиляция удобна в первую очередь для длительных аналитических запросов. Для коротких запросов дополнительные накладные расходы на выполнение JIT-компиляции часто превышают время экономии, что невыгодно. Внутренний рабочий процесс JIT состоит из 3-х этапов:
- Этап планировщика, который проходит в координаторе Greenplum. Планировщик создает дерево плана запроса и его расчетную стоимость. Планировщик решает инициировать JIT-компиляцию, если параметр конфигурации jit равен true и расчетная стоимость запроса выше, чем значение параметра конфигурации jit_above_cost. Если параметр jit_expressionsвключен, планировщик предлагает исполнителю скомпилировать выражения в JIT-пространстве. Если предполагаемая стоимость больше, чем порог, заданный в конфигурации jit_inline_above_cost , планировщик компилирует короткие функции и операторы, используемые в запросе, используя встроенную компиляцию. Если предполагаемая стоимость больше, чем значение jit_optimize_above_cost, применятся дорогостоящие оптимизации для улучшения сгенерированного кода. Включенный параметр конфигурации jit_tuple_deforming создает пользовательскую функцию для деформации целевой таблицы. Каждый из этих вариантов увеличивает нагрузку на JIT-компиляцию, но может значительно сократить время выполнения длительного аналитического SQL-запроса. Необходимо настроить эти параметры конфигурации при включении или отключении оптимизатора GPORCA, поскольку значение стоимости отличается для GPORCA и Postgres Planner. Установка параметров стоимости JIT в значение 0 приводит к принудительной JIT-компиляции всех запросов и замедляет их выполнение. Установка для них отрицательного значения отключит функцию, предоставляемую параметром. Когда план выполнения запроса готов, планировщик предоставляет исполнителю деревья планов и флаги JIT.
- Этап инициализации исполнителя проходит в сегментах Greenplum. Greenplum создает шаги оценки выражения. Если используется JIT-компиляция, он перезаписывает шаги как функции в пространстве JIT. Решения, принятые во время планирования, определяют, рекомендуется ли запускать JIT-компиляцию на этапе выполнения, а также стратегию JIT, которую следует применять. Именно во время выполнения Greenplum принимает решение об использовании JIT, если параметр конфигурации jit включен и JIT-библиотеки успешно загружены. Исполнитель может игнорировать кэшированные решения, если jit_expression изменены на false между этапами планировщика и выполнения, или если он обнаруживает ошибку. Дополнительно исполнитель проверяет следующие параметры конфигурации разработчика:
-
- jit_provider — имя используемой библиотеки JIT-провайдера;
- jit_dump_bitcode — запись сгенерированного LLVM IR в файловую систему внутри data_directory;
- jit_profiling_support — LLVM выдает данные, необходимые perf-разрешению команды профилировать функции, сгенерированные JIT;
- jit_debugging_support — LLVM регистрирует сгенерированные функции в Greenlpum.
- Этап запуска исполнителя происходит в сегментах Greenplum, которые выполняют шаги, предусмотренные этапом инициализации. Функции в пространстве JIT объединяются как единое целое перед первым вызовом.
Рабочий процесс JIT также может обеспечивать отказоустойчивость исполнителя: если JIT не удается загрузить сегменты, режим выполнения возвращается к обычному, без использования JIT.
В заключение подчеркнем, что использование JIT может добавить больше накладных расходов, чем потенциальная экономия. Чтобы понять, дает ли JIT-компиляция выигрыш при выполнении SQL-запросов, можно включить параметр конфигурации gp_explain_jit для отображения сводной информации по всем выполненным запросам при выполнении команды EXPLAIN, о которой мы писали здесь. Но при запуске регрессионных тестов этот параметр следует отключить. Выходные данные EXPLAIN предоставляют информацию о JIT, такую как среднее время среза, затраченное на JIT, из какого сегмента исходит максимальный вектор, или сколько функций JIT создано, и общее время, затраченное на задачи JIT. Эта информация может быть полезна при настройке JIT или отладке проблемы синхронизации. Просмотреть эту информацию позволит команда EXPLAIN ANALYZE VERBOSE.
Узнайте больше подробностей про администрирование и эксплуатацию Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

