Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать.
Транзакции в Neo4j
Neo4j — это популярная нативная графовая СУБД, способная управлять несколькими базами данных, отдельным сервером или группой серверов в кластере. Экземпляр Neo4j представляет собой процесс Java, в котором выполняется серверный код Neo4j. Для поддержания целостности данных и обеспечения надежного выполнения операций Neo4j отвечает ACID-требованиям к транзакциям и использует журнал транзакций с упреждающей записью. В Neo4j все операции с базой данных, которые обращаются к графу, индексам или схеме, должны выполняться в транзакции. Причем уровень изоляции по умолчанию обеспечивает изоляцию операций чтения зафиксированных данных (read committed). Этот уровень означает недопустимость так называемого «грязного чтения» (Dirty Read), когда транзакция считывает данные, записанные параллельно незафиксированной транзакцией. Однако, на этом уровне изоляции возможно неповторяемое чтение (Non-Repeatable), когда транзакция повторно считывает данные, которые она ранее читала, и обнаруживает, что они были изменены другой транзакцией, зафиксированной с момента первоначального чтения. Еще на уровне read committed возможны такие нарушения строгой изоляции, как фантомное чтение (Phantom Read), когда транзакция повторно выполняет запрос, возвращающий набор строк, удовлетворяющих условию поиска, и обнаруживает, что он изменился из-за другой недавно зафиксированной транзакции. Также на уровне read committed изоляцию нарушает аномалия сериализации, когда результат успешной фиксации группы транзакций несовместим со всеми возможными порядками их выполнения по одной за раз.
Блокировки записи в Neo4j устанавливаются автоматически на уровне узлов и отношений. Можно вручную получить блокировки записи, если надо достичь более высокого уровня изоляции — сериализуемого (Serializable). Сериализуемость означает параллельное выполнение набора транзакций, которое гарантированно дает тот же эффект, что и их последовательное выполнение по одной. Этот уровень является самым строгим уровнем изоляции транзакций без каких-либо взаимодействий между ними, поскольку не допускает ни одно из нарушений строгой изоляции.
Данные, полученные обходами графа, не защищены от модификации другими транзакциями. Могут происходить неповторяющиеся операции чтения, когда устанавливаются и удерживаются до конца транзакции только блокировки записи. Обнаружение взаимоблокировок встроено в основное управление транзакциями.
Набор графов, которые можно обновлять в контексте одной транзакции в Neo4j называется доменом транзакции. А среда выполнения запроса, транзакции, внутренней функции или процедуры называется контекст выполнения.
Сама база данных представляет собой объект администрирования СУБД, физическая структура файлов, организованных в одноименном каталоге. В Neo4j каждая стандартная база данных содержит один граф. Многие административные команды обращаются к определенному графу, используя имя базы данных. База данных Neo4j определяет домен транзакции и контекст выполнения, т.е. транзакция не может охватывать несколько баз данных. Аналогично процедура работы с данными вызывается в конкретной базе, хотя ее логика может обращаться к данным, хранящимся в других базах.
Системные и составные базы данных
По умолчанию установка Neo4j 5 содержит две базы данных:
- system – системная база данных, содержащая метаданные о СУБД и конфигурации безопасности. При подключении к базе данных system пользователю доступны только некоторые из административных функций. Доступ к большинству доступных административных команд ограничен пользователями с определенными административными привилегиями.
- neo4j – база данных по умолчанию , единая база данных для пользовательских данных.
Поскольку в одной базе данных Neo4j хранится один граф знаний, чтобы работать с несколькими графами нужно несколько баз. Для реализации этой возможности в Neo4j используется концепция составной базы данных – логической группы нескольких графов, содержащихся в разных стандартных базах. Составная база данных определяет контекст выполнения и (ограниченный) домен транзакции. Концепция составной базы данных реализована в Neo4j версии 5 и заменяет предыдущую реализацию Fabric в версии 4. Fabric — это архитектурный проект унифицированной системы, обеспечивающий единую точку доступа к локальным или распределенным данным графа.
Составная база данных является средством доступа к разделенным данным или графам с помощью одного Cypher-запроса. Однако, будучи логическим, а не физическим понятием, составная база данных не хранит данные, а содержит псевдонимы баз, которые составляют структуру данных. Локальная база данных использует псевдонимы целевых баз данных в той же СУБД, а удаленная база данных использует псевдонимы целевых баз данных из другой СУБД Neo4j.
Составные базы данных управляются с помощью административных Cypher-команд. Администратор кластера этой NoSQL-СУБД может создавать их как любую другую базу данных в автономных и кластерных развертываниях Neo4j без необходимости развертывания выделенного прокси-сервера, как это было необходимо в случае с Fabric в версии 4. Будучи физически разделенными экземплярами, составные базы данных не могут гарантировать совместимость компонентов из разных основных версий Neo4j. Поэтому все компоненты должны принадлежать к одной и той же основной версии, чтобы обеспечить унифицированную возможность использовать функции работы с графами.
При работе с составными базами данных используются следующие понятия:
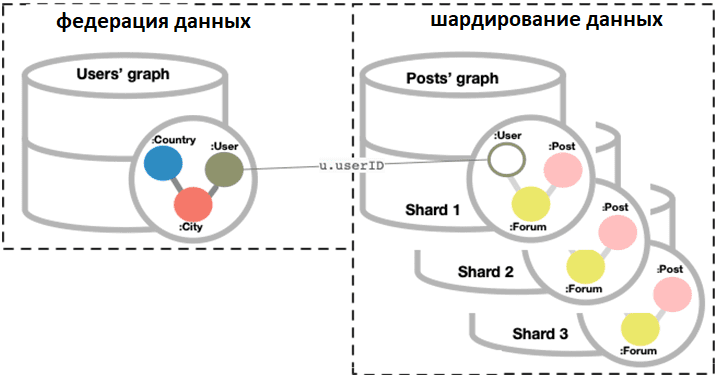
- федерация или объединение данных, когда запрашиваемые данные находятся в двух непересекающихся графах с разными метками и типами отношений;
- шардирование или разделение данных, когда есть два графа с одной и той же моделью, т.е. одинаковыми метками и типами отношений, но содержащие разные данные. Например, можно развернуть шарды на отдельных серверах, разделив нагрузку на ресурсы и хранилище. Также можно развернуть сегменты в разных местах, чтобы управлять ими независимо или разделить нагрузку на сетевой трафик. Существующую базу данных Neo4j можно шардировать с помощью административной команды database copy.
Чтобы запрашивать графы в составных базах данных, необходимо их объединить с помощью шаблона моделирования прокси-узла , где узлы с определенной меткой должны присутствовать в обоих федеративных доменах. На одном из графов узлы с этой конкретной меткой содержат все данные, относящиеся к этой метке, а на другом графе такая же метка связана с прокси-узлом, который содержит только свойство <node>ID. Именно это свойство <node>ID позволяет связать данные разных графов в одной федерации.
Наконец, отметим, что при подключении пользователя к Neo4j без указания базы данных, он будет подключен к домашней базе данных, настроенную для этого пользователя . Если у подключающегося пользователя не настроена домашняя база данных, сервер будет использовать базу данных по умолчанию, которая есть у каждого экземпляра Neo4j. Домашние базы данных для каждого пользователя управляются с помощью команд администрирования Cypher. Чтобы установить домашнюю базу данных для пользователя, он должен существовать как запись в Neo4j. Для развертываний с использованием внешних провайдеров аутентификации OpenID Connect (OIDC), таких как Okta, Microsoft Azure, Active Directory или Google, следует создать собственного пользователя с соответствующим именем, а затем установить домашнюю базу данных для него. Про миграцию баз данных и импорт данных из реляционного источника в графовую модель мы рассказываем здесь. Также читайте в нашей новой статье, как концепция составных баз данных Neo4j может использоваться в платформе BioCypher для биомедицинских исследований.
Графовые алгоритмы. Бизнес-приложения
Код курса
GRAF
Ближайшая дата курса
по запросу
Продолжительность
24 ак.часов
Стоимость обучения
54 000 руб.
Узнайте больше про особенности администрирования и эксплуатации Neo4j, а также других инструментов работы с графами для практического использования в реальных проектах аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники