В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных.
Что такое SQL-оптимизатор Spark-Radiant и чем он лучше Catalyst
Оптимизатор Spark-Radiant основан на сборке Maven и поддерживает версию фреймворка от 3.0 и выше, а также версию Scala от 2.12. Проект состоит из 2-х модулей:
- spark-radiant-sql, который содержит оптимизацию, связанную с производительностью Spark SQL. В частности, он отлично подходит для динамической фильтрации, например, при соединении таблиц в звездообразных схемах, когда одна таблица состоит из большого количества записей по сравнению с другими таблицами. Динамическая фильтрация работает во время выполнения, используя предикаты из меньшей таблицы, отфильтровывая столбцы соединения, используя результат этих предикатов для большей таблицы и отфильтровывая большую таблицу. Это приводит к менее затратному соединению. Поскольку количество записей в левой части уменьшается, что приводит к повышению производительности запросов Spark SQL за счет уменьшения объема данных, передаваемых по сети и минимизации сетевого ввода-вывода.
- spark-radiant-core содержит оптимизатор на основе затрат (total cost optimization), а также улучшенное автомасштабирование в Spark и сборщик метрик.
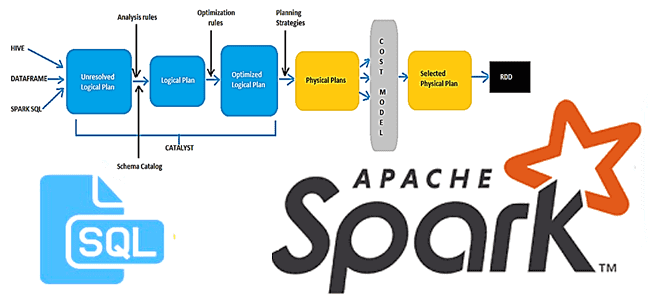
Тестирование показало, что динамическая фильтрация с оптимизатором Spark-Radiant работает быстрее регулярного JOIN-соединения. Это достигается за счет улучшения Catalyst-оптимизатора, включая индексацию BloomFilter и переупорядочивание соединений. Напомним, в Catalyst-оптимизаторе фреймворка имеется CostBasedJoinReorder – базовая логическая оптимизация, которая переупорядочивает соединения с целью сокращения затрат. ReorderJoin является частью пакета Join Reorder в стандартных пакетах Catalyst Optimizer. ReorderJoin — это просто правило Catalyst для преобразования логических планов, то есть правило логического плана выполнения SQL-запроса. В SQL-оптимизаторе правило — это именованное преобразование, которое может быть применено (выполнено или преобразовано) к дереву узлов логического плана (TreeNode) для создания нового TreeNode. CostBasedJoinReorder применяет оптимизацию соединения к логическому плану с 2 или более последовательными внутренними или перекрестными соединениями, когда оба свойства конфигурации spark.sql.cbo.enabled и spark.sql.cbo.joinReorder.enabled включены. Подробнее о работе оптимизатора Catalyst мы писали здесь, здесь и здесь.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 июня, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
В оптимизаторе Spark-Radiant-Sql правила логического плана доступны во время выполнения на языках Scala и PySpark. Например, код на Scala выглядит так:
import com.spark.radiant.sql.api.SparkRadiantSqlApi
// adding Extra optimizer rule
val sparkRadiantSqlApi = new SparkRadiantSqlApi()
sparkRadiantSqlApi.addOptimizerRule(spark)
А на PySpark так:
./bin/pyspark —packages io.github.saurabhchawla100:spark-radiant-1.0.2
// Importing the extra Optimizations rule from sparkradiantsqlpy
import SparkRadiantSqlApi
SparkRadiantSqlApi(spark).addExtraOptimizerRule()
OR
// Importing the extra Optimizations rule
spark._jvm.com.spark.radiant.sql.api.SparkRadiantSqlApi().addOptimizerRule(spark._jsparkSession)
Одним из интересных правил в Spark-Radiant является UnionReuseExchangeOptimizeRule, которое работает для сценариев соединения таблиц с агрегацией, имеющей те же столбцы группировки. Соединение происходит между одной и той же таблицей (источником данных). При этом вместо двойного сканирования исходной таблицы будет одно сканирование, которое будет использовать другой дочерний элемент узла – элемент SQL-запроса Union. Эта функция включается с помощью установки конфигурации spark.sql.optimize.union.reuse.exchange.rule в значение true.
Еще одним улучшающим правилом в Spark-Radiant является ExchangeOptimizeRule, которое работает для сценариев частичного агрегированного обмена и обмена данными в случайном порядке. Если стоимость создания обоих обменов почти одинакова, то обмен, созданный частичным агрегатом, пропускается. Это правило включается с помощью настройки фонфигурации spark.sql.skip.partial.exchange.rule.
Попробовать эти и другие возможности нового оптимизатора Spark SQL можно, установив его JAR-пакет в проект Maven:
./bin/spark-shell
—packages «io.github.saurabhchawla100:spark-radiant-sql:1.0.2,io.github.saurabhchawla100:spark-radiant-core:1.0.2»
./bin/spark-submit
—packages «io.github.saurabhchawla100:spark-radiant-sql:1.0.2,io.github.saurabhchawla100:spark-radiant-core:1.0.2»
—class com.test.spark.examples.SparkTestDF /spark/examples/target/scala-2.12/jars/spark-test_2.12-3.1.1.jar
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 июня, 2025
Продолжительность
32 ак.часов
Стоимость обучения
96 000
Узнайте больше подробностей эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вам помогут узнать специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

