 665
665 
Чтобы сделать наши курсы по Spark еще более интересными и добавить в них самые актуальные тренды, сегодня мы расскажем о новом релизе этого Big Data фреймворка. Читайте далее, что нового в Apache Spark 3.0 и почему Spark SQL стал еще лучше.
10 лет в Big Data или немного истории
В июне 2020 года вышел новая версия Apache Spark – 3.0. Примечательно, что в этом году проект празднует первый серьезный юбилей – 10 лет. Напомним, Apache Spark, как и многие Big Data проекты, начал свой путь из академической среды – исследовательской лаборатории AMPlab Калифорнийского университета Беркли, которая специализировалась на вычислениях с интенсивным использованием данных. Команда ученых AMPlab создала новый движок для решения проблем с обработкой больших объемов данных, одновременно предоставив API для разработчиков. Дальнейшее развитие Spark было обусловлено его продвижением в профессиональном сообществе Data Science энтузиастов, включая возможности потоковой передачи, Python и SQL для обработки больших данных. Благодаря этому Apache Spark стал весьма популярным движком для обработки и анализа больших данных, а также задач машинного обучения. Apache Spark 3.0 продолжает эту тенденцию, оптимизируя производительность и работоспособность всех компонентов фреймворка, о чем мы поговорим далее [1].
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
96 000
Apache Spark 3.0: 7 главных нововведений
Итак, в этом релизе Apache Spark было разрешено более 3400 обращений в результате вклада более 440 участников. При этом почти половина (46%) разрешенных заявок относятся к Spark SQL. В частности, теперь он соответствует принятому стандарту ANSI SQL и содержит подробную документацию. Также введено адаптивное выполнение запросов и динамическая обрезка разделов. Эти улучшения полезны всем компонентам фреймворка, включая пользовательский интерфейс для структурированной потоковой передачи (Structured Streaming), а также API более высокого уровня, в т.ч. SQL и DataFrames [2].
Из улучшений Spark SQL наиболее важными считаются следующие [1]:
- новая структура адаптивного выполнения запросов (AQE, Adaptive Query Execution) повышает производительность и упрощает настройку, создавая лучший план во время выполнения, даже если первоначальный план неоптимален из-за отсутствия / неточной статистики данных и неверно оцененных затрат. Поскольку из-за разделения памяти и вычислений в Spark поступление данных может быть непредсказуемым, адаптивность среды выполнения для этого фреймворка весьма существенна.
- Динамическое объединение разделов (shuffle partitions) в случайном порядке упрощает или даже позволяет избежать настройки количества разделов в случайном порядке. Пользователи могут установить относительно большое количество перемешиваемых разделов в начале, а затем AQE объединит соседние небольшие разделы в более крупные во время выполнения.
- Динамическое переключение стратегий соединения частично позволяет избежать выполнения неоптимальных планов из-за отсутствия статистики или неправильной оценки размера. Эта адаптивная оптимизация автоматически может преобразовывать соединение сортировки-слияния (sort-merge join) в соединение широковещательного хеширования (broadcast-hash join) во время выполнения, что еще больше упрощает настройку и повышает производительность.
- Динамическая оптимизация стыковок с перекосом (skew joins) также улучшает производительность, т.к. эти преобразования могут привести к экстремальному дисбалансу работы и серьезному торможению. После того, как AQE обнаружит любой перекос в статистике файлов в случайном порядке, он разделит перекос на более мелкие и объединит их с соответствующими разделами, с другой стороны. Эта оптимизация может распараллелить обработку перекоса и повысить общую производительность.
На рисунке ниже показаны результаты бенчмаркингового теста AQE-оптимизаций в Apache Spark 3.0.
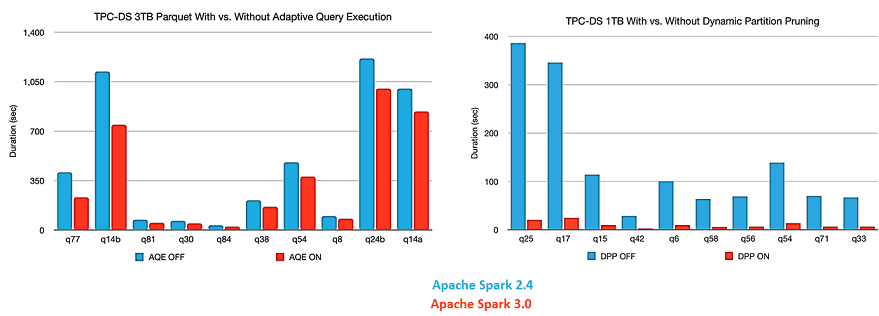
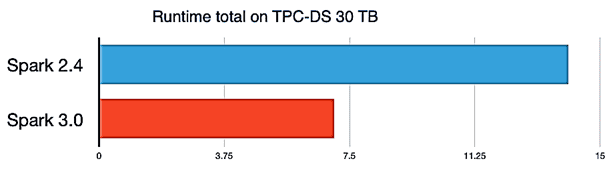
Еще этот же бенчмаркинговый тест TPC-DS (TPC Benchmark Decision Support) показал, что версия 3.0 работает примерно в 2 раза быстрее, чем релиз 2.4. Напомним, TPC-DS считается наиболее популярным бенчмаркинговым тестом для оценки производительности систем по следующим параметрам [3]:
- время ответа на запрос в однопользовательском режиме;
- пропускная способность запросов в многопользовательском режиме;
- производительность обслуживания данных для данного оборудования, операционной системы и конфигурации системы обработки данных при контролируемой, сложной и многопользовательской рабочей нагрузке.
Наконец, отдельно стоит сказать о новостях, особенно важных для аналитиков данных и разработчиков Big Data:
- значительные улучшения в API-интерфейсах популярной среди ML-специалистов библиотеки Pandas, включая подсказки типов Python и дополнительные UDF-функции. Подробнее о новинках Spark ML мы рассказываем в этом материале.
- лучшая обработка ошибок Python и упрощение исключений PySpark;
- ускорение вызова пользовательских функций языка R до 40 раз.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Именно о SparkR мы поговорим в следующей статье, а о главных фишках нового релиза 3.1.1, связанных с развертыванием на Kubernetes, читайте здесь. А о выпуске Spark 3.2.0 читайте в этом материале.
Как использовать все преимущества этого фреймворка для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://databricks.com/blog/2020/06/18/introducing-apache-spark-3-0-now-available-in-databricks-runtime-7-0/
- https://spark.apache.org/releases/spark-release-3-0-0/
- http://www.tpc.org/tpcds/

