Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ.
Запуск приложения Apache Spark в кластере Kubernetes с помощью скрипта
Напомним, Apache Spark – это комплексный Big Data фреймворк для потоковой и пакетной обработки информации в режиме near real-time, а также аналитики больших данных. Запустить готовое приложение Спарк можно с помощью скрипта bin/spark-submit. Этот скрипт заботится о настройке пути к классам Spark и их зависимостями, поддерживая различные менеджеры кластеров, например, Hadoop Yarn или K8s, а также режимы развертывания [1].
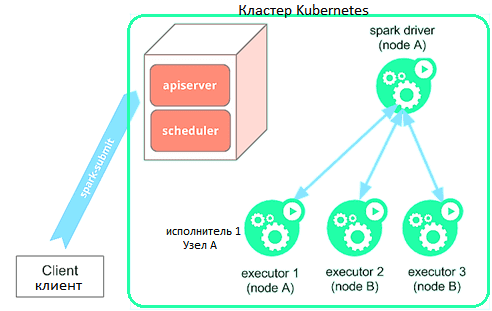
Таким образом, spark-submit может напрямую отправлять приложения Спарк в кластер Kubernetes. Это работает следующим образом [2]:
- Apache Spark создает собственный драйвер, работающий в поде (модуле) Kubernetes;
- драйвер Спарк создает исполнителей, которые также работают в подах Kubernetes, подключается к ним и выполняет код приложения;
- после завершения работы Spark-приложения исполнители на подах также завершают работу и очищаются, при этом под драйвера сохраняет журналы и остается в состоянии «завершено» в Kubernetes API до тех пор, пока так называемый мусор (garbage) не будет собран или очищен вручную;
- важно, что в завершенном состоянии под драйвера не использует никаких вычислительных ресурсов или памяти.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
12 мая, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Kubernetes сам планирует запуск по расписанию (scheduling) подов драйверов и исполнителей, а связь с Kubernetes API осуществляется через fabric8. Можно планировать запуск подов драйвера и исполнителя на подмножестве доступных узлов с помощью соответствующего селектора через настройку его конфигурации. В перспективе будет доступна привязка узлов или подов при планировании регулярного запуска задач на кластере K8s [2].
Как работает Спарк-оператор в K8s
Как мы недавно рассказывали, с мая 2020 года Kubernetes поддерживает Spark Operator для Apache Spark 2.4.5 и выше. Он позволяет настраивать параметры конфигурации, например, монтировать ConfigMap с конфигурацией доступа к Hadoop в поды Спарк и запускать задачи по расписанию. Примечательно, что исходный код Spark Operator открыт и доступен на GitHub в репозитории Google Cloud Platform.
Чтобы запустить задачи Спарк в кластере Kubernetes с помощью оператора, необходимо сделать следующее [3]:
- создать Docker-образ со всеми библиотеками, конфигурационными и исполняемыми файлы;
- опубликовать Docker-образ в реестр, доступный из кластера Kubernetes;
- сформировать манифест с типом «SparkApplication» и описанием запускаемой задачи, включая указание версия API для оператора, пространства имён для запуска приложения, адрес созданного Docker-образа в доступном реестре, класса задачи Спарк, пути к исполняемому jar-файлу, версии, сервисной учётной записи для запуска приложения, количества выделяемых ресурсов и локальной директории, где будут создаваться локальные файлы задачи Спарк.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
12 мая, 2025
Продолжительность
32 ак.часов
Стоимость обучения
96 000 руб.
3 особенности работы приложений Apache Spark на Кубернетес в клиентском режиме
Спарк-приложение на K8s может быть запущено как в кластерном режиме, так и в режиме клиента. При запуске в клиентском режиме, драйвер может работать внутри пода Kubernetes или на физическом хосте. Поэтому рекомендуется учитывать следующие факторы [2]:
- работа сети, т.к. исполнители Спарк должны иметь возможность подключаться к драйверу через имя хоста и порт, который маршрутизируется из них. Конкретная конфигурация сети, которая потребуется для работы распределенного приложения в клиентском режиме, зависит от настройки. При запуске драйвера внутри пода Kubernetes можно использовать автономную службу, чтобы обеспечить маршрутизацию пода драйвера от исполнителей по стабильному имени хоста. При развертывании автономной службы следует убедиться, что селектор меток службы соответствует только поду драйвера, а не другим модулям. Рекомендуется присвоить поду драйвера уникальную метку и использовать ее в селекторе меток автономной службы. Подробнее об этом читайте в нашей новой статье.
- сборка мусора (garbage collection) пода исполнителя, которая гарантирует, что после удаления пода драйвера из кластера все поды-исполнители приложения также будут удалены. Для этого следует установить spark.kubernetes.driver.pod.name в качестве имени пода драйвера, что позволит планировщику Спарк развертывать поды-исполнители с помощью OwnerReference. Драйвер будет искать под с заданным именем в пространстве имен, заданном параметром spark.kubernetes.namespace с учетом OwnerReference. Однако, не стоит устанавливать OwnerReference для пода, который на самом деле не является подом драйвера, чтобы работа исполнителей не завершилась преждевременно, когда будет удален ненужный под. Если Spark-приложение не работает внутри пода или свойство spark.kubernetes.driver.pod.name не задано, то поды-исполнители могут быть удалены из кластера, когда приложение закрывается. Планировщик Спарк пытается удалить эти поды, но, если сетевой запрос к API-серверу не выполняется, они останутся в кластере. Однако, процессы-исполнители завершаются, когда не могут связаться с драйвером, поэтому поды-исполнители не должны потреблять вычислительные ресурсы (ЦП и память) в кластере после завершения работы приложения.
- параметры аутентификации Kubernetes в клиентском режиме распределенного приложения настраиваются через префикс spark.kubernetes.authenticate.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
27 февраля, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Больше подробностей по администрированию и эксплуатации Apache Spark для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark