440
440 
Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s).
Минусы запуска Apache Spark на Kubernetes
При запуске Apache Spark на Kubernetes, следует помнить об ограничениях совместного использования этих Big Data технологий, основных из которых можно назвать следующие:
- распределенность данных или отсутствие локальности (Data Locality) – в случае кластера K8s для выполнения задачи необходимо перемещать данные по сети, тогда как, например, в Hadoop YARN соблюдался принцип доставки кода к данным. Благодаря этому задачи Spark выполнялись на тех узлах, где лежали данные, что снижало время на передачу данных по сети. Таким образом, в случае запуска Spark на Kubernetes время выполнения задачи может значительно увеличиться. Также может потребоваться большой объём дискового пространства под экземпляры Spark-задачи для их временного хранения. Влияние этого недостатка можно частично нивелировать с помощью специализированных средств, обеспечивающих локальность данных в Kubernetes, таких как Alluxio — виртуальная распределенная файловая система с открытым исходным кодом. Однако, стоит помнить, что фактически данное ограничение приводит к необходимости хранить полную копию данных на всех узлах кластера K8s [1].
- проблемы информационной безопасности, связанные с отключением security-функций относительно запуска задач Spark, в т.ч. отсутствие защищенного протокола Kerberos в официальной документации Apache Spark версии 2.4. Впрочем, стоит отметить, что в новом релизе Spark0.0 данные настройки появились. Однако, эта версия еще носит экспериментальный характер и пока не получила широкого распространения на практике. В Apache Spark 2.4 пользователь, который запускает задачи Spark, не может быть указан напрямую: задается только сервисная учётная запись для пода K8s, а сам пользователь выбирается по настройкам политик безопасности. Поэтому используется либо суперпользователь root, что по умолчанию не является безопасным, либо пользователь с случайным UID, что неудобно при распределении прав доступа к данным. Последнее неудобство обходится с помощью создания политики безопасности пода (PodSecurityPoliciy) и ее привязки к соответствующим служебным учётным записям. Это делается через упаковку всех необходимых файлов непосредственно в Docker-образ, либо изменение скрипта запуска Spark для использования корпоративного механизма хранения и получения секретов [1].
- особенности конфигурирования кластера Kubernetes требуют опыта администрирования и могут показаться сложными новичку. В частности, чтобы запустить Apache Spark на K8s, следует выполнить целый ряд действий, от создания и настройки кластера Kubernetes до оптимизации конфигурации приложений и ввода-вывода [2].
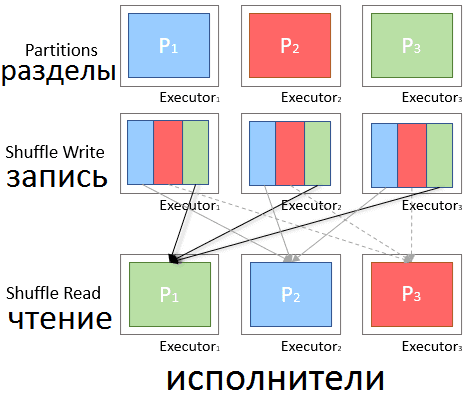
- ограничения динамического распределения структур данных из-за shuffle-архитектуры при MapReduce. Случайные перестановки – это дорогостоящие этапы обмена данными в Spark при выполнении операций MapReduce. Исполнители (executors) на этапе Map создают файлы в случайном порядке на локальном диске, которые позже будут загружены другими исполнителями на шаге Reduce. Если Map-исполнитель утерян, связанные shuffle-файлы тоже будут потеряны, и потребуется переносить их на другой исполнитель, что снизит производительность. С помощью YARN shuffle-файлы могут храниться во внешней службе, так что при включении динамического распределения исполнитель может быть безопасно удален при уменьшении масштаба без потери ценных shuffle-файлов. Такое невозможно в K8s, поэтому динамическое распределение должно работать с одним дополнительным ограничением: исполнители, хранящие активные shuffle-файлы для драйвера Spark, освобождаются от масштабирования. Подобное «мягкое» динамическое размещение доступно в версии новой Apache Spark 3.0. В перспективе ожидается, что вычислительные ресурсы (узлы и контейнеры K8s) будут полностью отделены от временного хранилища shuffle-данных. Это обеспечит «жесткое» динамическое распределение, а также сделает Спарк устойчивым к внезапной потере исполнителей, что является частой проблемой при использовании точечных или замещаемых виртуальных машин [2].
- экспериментальный характер Spark на Kubernetes, что чревато внесением существенных изменений в используемые артефакты, такие как конфигурационные файлы, базовые Docker-образы и скрипты запуска [1].
Теперь, зная основные достоинства и недостатки запуска Apache Spark на Kubernetes, в следующей статье мы рассмотрим механизмы совместной работы этих Big Data технологий. А все технические подробности по администрированию и эксплуатации Apache Spark для аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники