
Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...
В данном разделе мы публикуем информационно-аналитические статьи и новости о технологиях Больших Данных (Big Data), машинного обучения (Machine Learning), Data Science, администрировании распределенных кластеров Hadoop, NoSQL, Kafka, Spark, а также реальные истории и лучшие практики их прикладного использования (use cases и best practices) в российских и зарубежных компаниях.
Какие бывают таблицы для быстрой работы с Big Data в Hive

В прошлой статье мы рассматривали архитектуру Apache Hive и ее основные элементы. Сегодня поговорим про основные виды таблиц в Hive. Также подробно рассмотрим создание этих таблиц на практических примерах. Читайте далее про виды таблиц в Hive и их особенности. 2 основных вида таблиц для быстрой работы с большими данными в...
Большая разница: чем структурированная потоковая передача в Apache Spark отличается от Spark Streaming

В этой статье рассмотрим, что такое Apache Spark Structured Streaming и Spark Streaming, чем они отличаются и что общего между этими 2-мя способами обработки потоковых данных в самом популярном фреймворке аналитики больших данных. Читайте далее, как микро-пакетная передача приближается к режиму реального времени и при чем здесь структуры данных для...
Ускоряем и масштабируем Apache Spark Structured Streaming: 2 проблемы строго однократной доставки и их решения

Вчера мы говорили про реализацию exactly once семантики доставки сообщений в Apache Spark Structured Streaming. Сегодня рассмотрим, что не так с размером компактных файлов для хранения контрольных точек потоковой передачи, какие параметры конфигурации Spark SQL отвечают за такое логирование и как ускорить микро-пакетную обработку больших данных и чтение результатов выполнения...
Архитектура СУБД Apache Hive: основы Big Data для начинающих

В этой статье мы поговорим про структуру системы управления базами данных (СУБД) Apache Hive. Также рассмотрим, какие базовые компоненты входят в структуру известной SQL-подобной СУБД, входящей в экосистему Hadoop. Читайте далее про основные компоненты структуры Apache Hive, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки больших...
Только сегодня и только сейчас: как устроена строго однократная доставка сообщений в Apache Spark Structured Streaming

Недавно мы рассматривали оптимизацию SQL-запросов и выполнение JOIN-операций в Apache Spark. Сегодня поговорим, что обеспечивает строго однократную семантику доставку сообщений (exactly once) в этом Big Data фреймворке и как на это влияют особенности микро-пакетной обработки больших данных с помощью заданий Spark Structured Streaming. Особенности exactly once доставки сообщений в Apache...
Как работает Join в Apache Spark SQL: краткий ликбез для начинающих
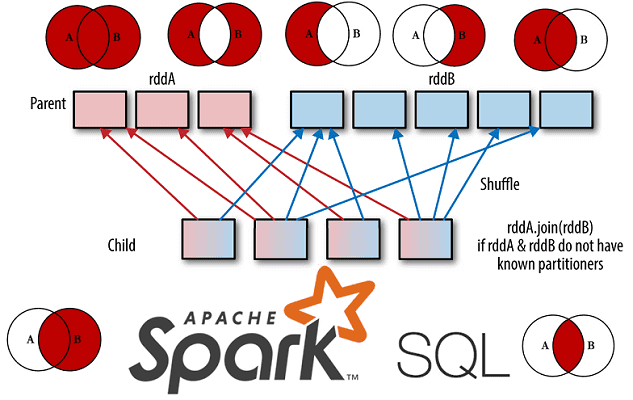
Развивая наши новые курсы по Apache Spark, сегодня мы рассмотрим Join-операции в SQL-модуле этого популярного фреймворка для аналитики больших данных. Читайте далее, чем отличаются разные Join-соединения друг от друга, как они реализуются в Spark SQL, какие существуют механизмы для их выполнения и от чего зависит выбор того или иного способа...
Насколько ты знаешь Apache Spark: открытый тест на знание популярного Big Data фреймворка

Обучение Apache Spark, Kafka, Hadoop и прочим технологиям Big Data – это не только курсы, теоретические статьи и практические задания, но и проверка полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по основам Спарк для начинающих. Проверьте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...
Конвейрезируй это: как построить ML-pipeline в Apache Spark MLLib
Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...
10 вопросов на знание основ Big Data: открытый интерактивный тест для начинающих

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...