
Что такое assert, зачем это нужно в тестировании и отладке, как эта конструкция применяется для сравнения датафреймов в PySpark: примеры работы функций assertDataFrameEqual() и assertSchemaEqual() в Apache Spark.
Что такое assert: конструкция тестирования
При разработке PySpark-приложения дата-инженер чаще всего оперирует такими структурами данных, как датафрейм. Датафрейм (DataFrame) – это распределенная таблица, коллекция данных, сгруппированная в именованные столбцы аналогично реляционной таблице в Spark SQL. Обычно работа с данными в PySpark включает в себя применение преобразований, агрегаций и манипуляций к датафреймам, которые в т.ч. могут быть созданы на основе данных из внешних источников. Чтобы протестировать полученный код в Apache Spark 3.5 были добавлены утилиты проверки равенства датафреймов. Они позволяют сверить данные с ожидаемыми результатами, помогая выявить неожиданные различия и ошибки на ранних этапах процесса анализа. На текущий момент в PySpark есть следующие функции, которые можно использовать для тестирования написанного кода распределенного приложения:
- assertDataFrameEqual(actual, expected[, …]) – утилита для подтверждения равенства между фактическим и ожидаемым датафреймом или списками строк с дополнительными параметрами checkRowOrder, rtol и atol;
- assertSchemaEqual(actual, expected) – утилита для подтверждения равенства между фактической и ожидаемой схемами датафрейма;
- assertPandasOnSparkEqual(actual, expected[, …]) – утилитная функция для подтверждения равенства между фактическим объектом pandas-on-Spark и ожидаемым объектом pandas-on-Spark или pandas. О разнице между классическим API pandas и его реализации в PySpark мы ранее писали здесь и здесь.
Все эти функции основаны на понятии assert – конструкции, которая позволяет проверять предположения о значениях произвольных данных в произвольном месте программы, подавая сигнал об обнаружении некорректных данных, что может привести к сбою. Assert завершает программу сразу же после обнаружения некорректных данных, давая разработчику возможность быстро определить ошибки и исправить их. Assert может отловить ошибки в коде на этапе компиляции или во время исполнения. Проверки на этапе компиляции можно заменить аналогичными синтаксическими конструкциями во время исполнения программы, например, try-except-finally. В большинстве языков программирования позволяют отключить assert на этапе компиляции или во время выполнения программы, поэтому влияние этих конструкций на производительность итогового продукта незначительно.
Примеры сравнения датафреймов в PySpark
Вспомнив, что такое assert, далее разберем, как эта конструкция применяется в функциях проверки равенства датафреймов в PySpark. Сперва рассмотрим функцию assertDataFrameEqual(). В качестве примера возьмем датафрейм из 2-х столбцов, в 1-м из которых будет дата регистрации, а во 2-м емейл пользователя. Чтобы запустить скрипт в Google Colab, сперва установим библиотеки и импортируем необходимые модули:
# Установка необходимых библиотек !pip install pyspark # Импорт необходимых модулей из pyspark import pyspark from pyspark.sql import SparkSession from pyspark.testing import assertDataFrameEqual
Затем создадим сессию Spark и 2 датафрейма: ожидаемый и актуальный, которые необходимо сравнить с помощью функции assertDataFrameEqual(). При этом намеренно введем разницу в некоторые значения этих датафреймов:
#создаем сессию
spark = SparkSession.builder.getOrCreate()
#ожидаемый датафрейм
df_expected = spark.createDataFrame(data=[("2024-25-04", "123@mail.ru"), ("2024-22-04", "987@gmail.ru"), ("2024-20-04", "cx@xc.com")], schema=["date", "login"])
#реальный датафрейм
df_actual = spark.createDataFrame(data=[("2024-25-04", "123gmail.ru"), ("2024-22-04", "987@mail.ru"), ("2024-20-04", "cx@xc.com")], schema=["date", "login"])
#сравнение датафреймов
assertDataFrameEqual(df_actual, df_expected)
Функция assertDataFrameEqual() возвращает описательную информацию о том, что 2 первых строки в двух датафреймах отличаются.

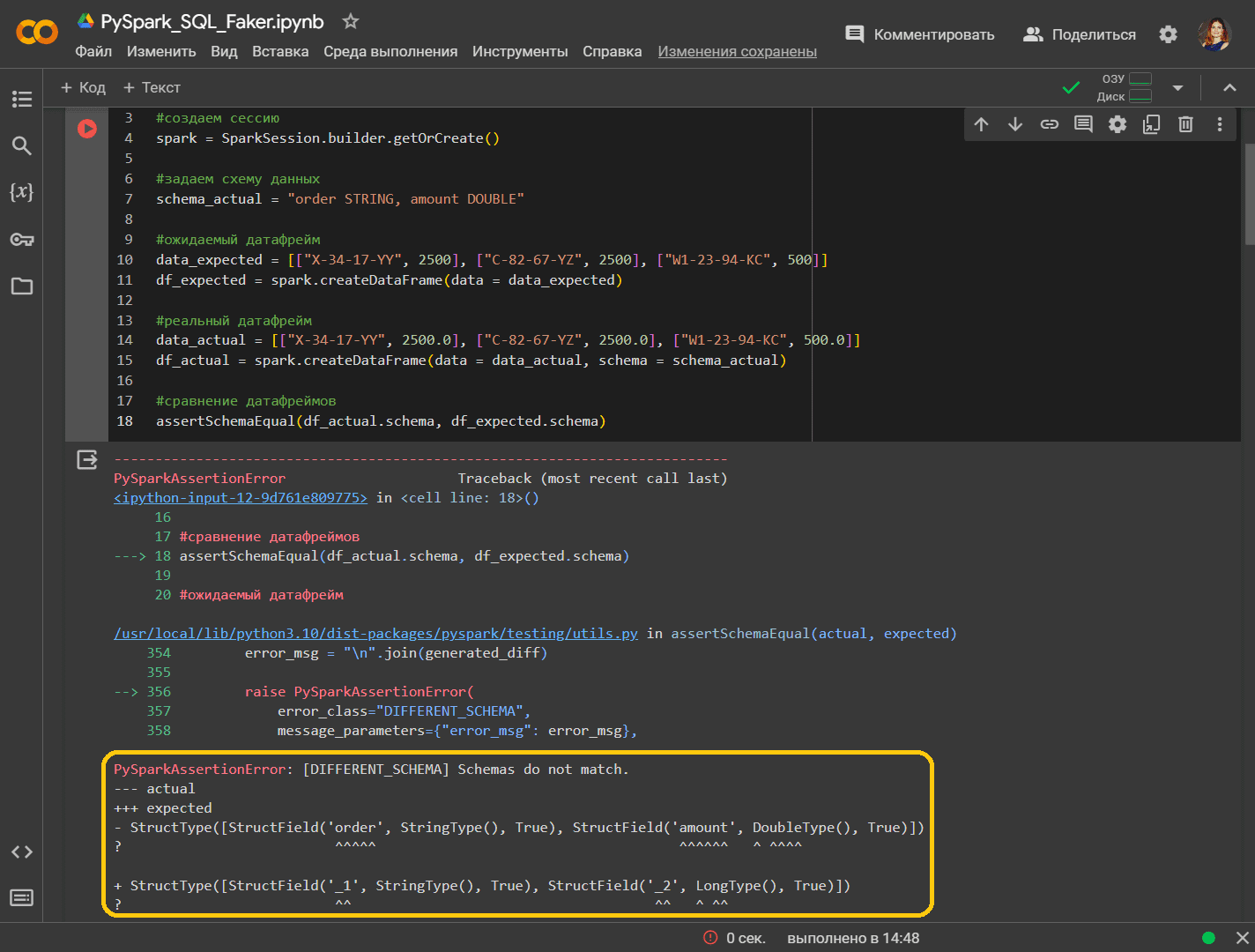
Теперь рассмотрим, как работает функция assertSchemaEqual(), которая сравнивает только схемы двух датафреймов, не обращая внимание на значения строк. Это позволяет проверить, совпадают ли имена столбцов, типы данных и допустимость NULL-значений для двух разных датафреймов. Применим функцию к нашему примеру, немного изменив его. Предположим, датафреймы содержат данные о номер заказа и его сумме. Введем намеренное разночтение в столбце сумма, в одном случае показав ее ка целочисленное, а в другом – как вещественное число. Код примера на PySpark выглядит так:
# Установка необходимых библиотек !pip install pyspark # Импорт необходимых модулей из pyspark import pyspark from pyspark.sql import SparkSession from pyspark.testing import assertSchemaEqual #создаем сессию spark = SparkSession.builder.getOrCreate() #задаем схему данных schema_actual = "order STRING, amount DOUBLE" #ожидаемый датафрейм data_expected = [["X-34-17-YY", 2500], ["C-82-67-YZ", 2500], ["W1-23-94-KC", 500]] df_expected = spark.createDataFrame(data = data_expected) #реальный датафрейм data_actual = [["X-34-17-YY", 2500.0], ["C-82-67-YZ", 2500.0], ["W1-23-94-KC", 500.0]] df_actual = spark.createDataFrame(data = data_actual, schema = schema_actual) #сравнение датафреймов assertSchemaEqual(df_actual.schema, df_expected.schema)
Функция определяет, что схемы двух DataFrames различны, а выходные данные указывают, где они расходятся. В реальном датафрейме тип данных столбца amount является LONG, тогда как в ожидаемом датафрейме указан DOUBLE. Поскольку ожидаемый датафрейм создан без указания схемы, имена столбцов также различаются, что показано в выходных данных функции.
Хотя функции assertDataFrameEqual() и assertSchemaEqual() прежде всего предназначены для модульного тестирования с не очень большими набрами данных, их можно использовать и с относительно большими датафреймами, чтобы упростить дальнейшую отладку.
В дополнение к функциям для проверки равенства кадров данных PySpark, пользователи Pandas API в Spark могут использовать функции проверки равенства датафреймов, которые предоставляют возможности для управления строгостью сравнений и отлично подходят для модульного тестирования API Pandas в датафреймах Spark. Они предоставляют тот же API, что и служебные функции тестирования pandas , что позволяет использовать их, не изменяя существующий код pandas. Так можно найти ошибки и понять, почему они возникли, чтобы быстро устранить их. Эти функции будут доступны в Apache Spark 4.0.
Узнайте больше про возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- Архитектура данных с Apache Spark
Источники

