627
627 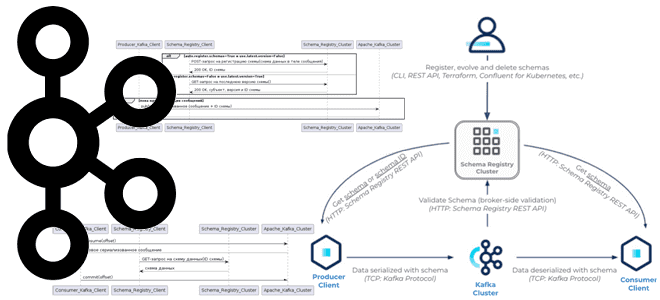
Содержание
Почему клиентское приложение для публикации сообщений или их потребления из Kafka при использовании реестра схем существует в двух экземплярах, что добавляется к сериализованному сообщению, где хранится идентификатор схемы и другие тонкости работы с Confluent Schema Registry.
Сериализация и десериализация сообщений с реестром схем Apache Kafka
Недавно я показывала небольшую демонстрацию Python-приложений публикации и потребления сообщений в формате AVRO с использованием реестра схем Apache Kafka и библиотеки confluent_kafka. Сегодня разберем теоретическую составляющую этой практики, познакомившись с принципами работы клиентов реестра схем.
Напомним, реестр схем (Schema Registry) – это модуль Confluent для Apache Kafka, который позволяет централизовано управлять схемами данных полезной нагрузки сообщений в топиках этой распределенной платформы потоковой передачи событий. Определив схемы данных для полезной нагрузки и зарегистрировав ее в реестре, ее можно использовать повторно, упростив код приложения-потребителя, исключив из него проверку структуры и формата потребляемых данных. Еще реестр схем делает потоковую передачу данных еще быстрее, передавая идентификатор схемы полезной нагрузки сообщения вместо ее полного определения.
По своей сути реестр схемы состоит из двух основных частей:
- REST-сервис проверки, хранения и получения схем AVRO, JSON-схема и Protobuf;
- сериализаторы и десериализаторы, которые подключаются к клиентам Apache Kafka, т.е. продюсерам и потребителям для хранения и извлечения схем данных полезной нагрузки сообщений в вышеуказанных трех форматах.
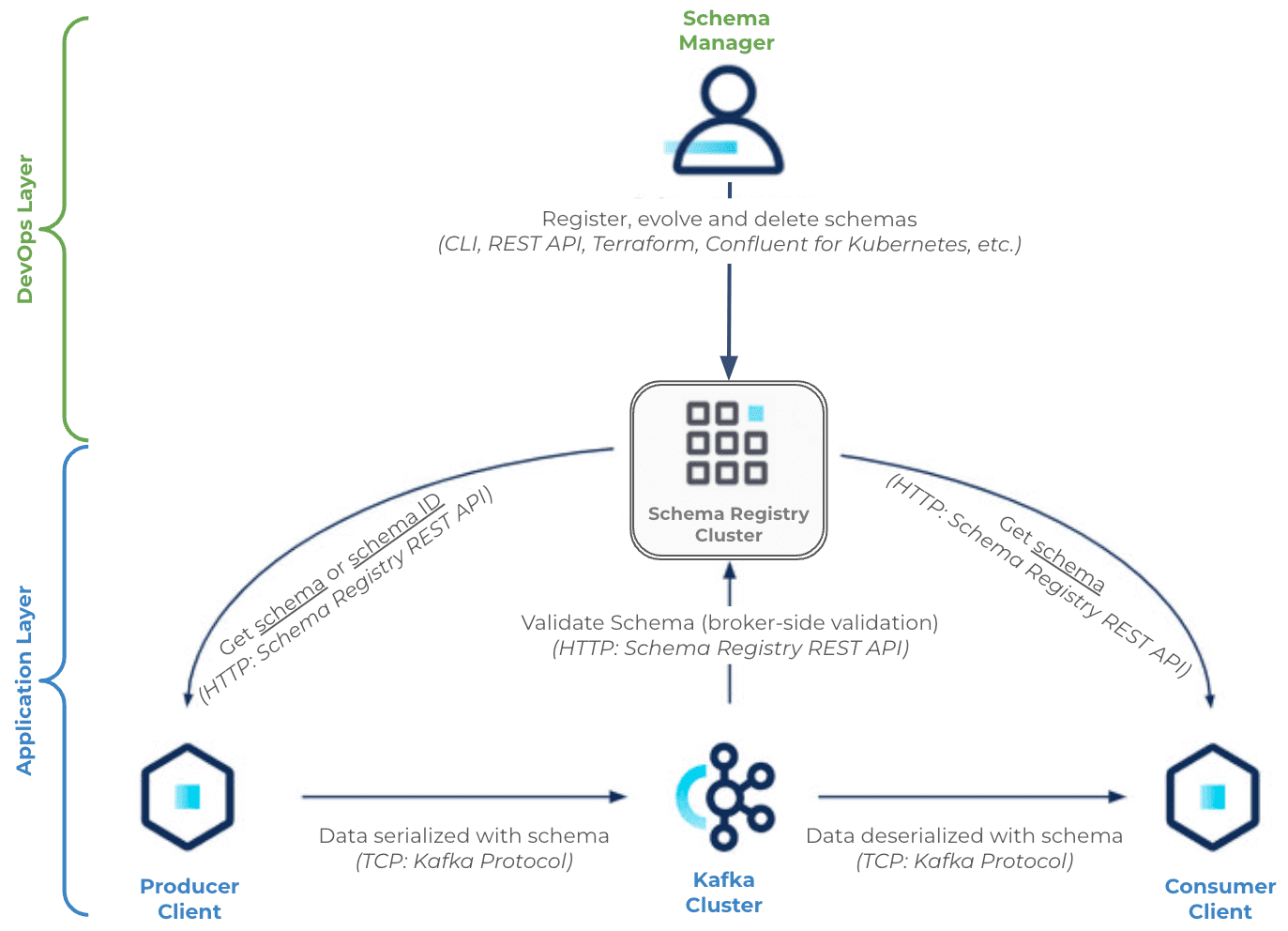
Таким образом, клиентское приложение, т.е. продюсер или потребитель Apache Kafka взаимодействует как минимум с двумя отдельными и разными системами: с самой платформой Kafka по ее нативному протоколу поверх TCP и REST API реестра схем. Примечательно, что реестр схем существует вне и независимо от самого кластера Kafka, он не хранит и не обрабатывает сообщения, которыми публикуют продюсеры, не сериализует и не десериализует сообщения. Реестр схем обрабатывает только метаданные: субъекты, версии, сами схемы и их идентификаторы, являясь инструментом обеспечения контракта данных в асинхронной интеграции приложений.
При работе с реестром схем используются следующие компоненты:
- менеджер схемы (Schema manager), например, плагин Schema Registry Maven. Хотя схема может регистрироваться и управляться на стороне приложения-продюсера, как я показывала в прошлой статье, это не очень удобно. Рекомендуется для управления схемами применять CI/CD-подход, чтобы клиенты-продюсеры и потребители имели доступ к реестру схем только для чтения данных. Это обеспечивает строгое соблюдение контрактов интеграции данных, гарантируя их качество и согласованность.
- кластер Apache Kafka. Брокеры Kafka взаимодействуют с реестром схем для проверки схемы полезной нагрузки сообщения, что включается для каждого топика в Confluent Cloud и в выделенных кластерах. Этот процесс позволяет брокеру проверить, что данные, опубликованные в топике Kafka, используют действительный идентификатор схемы в реестре схем, зарегистрированный в соответствии со стратегией именования субъектов. Это единственная проверка, т.е. структура самой схемы данных и формат сериализации не проверяются.
- клиент-продюсер, который взаимодействует с реестром схем и с кластерами Kafka. При сериализации сообщения продюсер получает идентификатор схемы из реестра схем, сериализует сообщение в соответствии с этой схемой, а затем создает двоичные данные в кластере Kafka. Приложение-продюсер также может получить копию всей схемы и ее идентификатора без необходимости хранить их локально.
- клиент-потребитель, который также взаимодействует с реестром схемы и с кластерами Kafka. Однако, потребитель сначала получает сериализованное сообщение из кластера Kafka, извлекает идентификатор схемы, по которому получает соответствующую схему из реестра и только затем десериализует сообщение, восстанавливая его исходную структуру.
Apache Kafka имеет несколько собственных сериализаторов для различных типов данных, например, org.apache.kafka.common.serialization.StringSerializer, org.apache.kafka.common.serialization.IntegerSerializer, org.apache.kafka.common.serialization.DoubleSerializer, org.apache.kafka.common.serialization.BytesSerializer.
Также можно создать свой собственный сериализатор и десериализатор. Библиотека Confluent предоставляет дополнительные сериализаторы и десериализаторы для форматов AVRO, JSON-схемы и Protobuf: io.confluent.kafka.serializers.KafkaAvroSerializer, io.confluent.kafka.serializers.KafkaAvroDeserializer, io.confluent.kafka.serializers.json.KafkaJsonSchemaSerializer, io.confluent.kafka.serializers.json.KafkaJsonSchemaDeserializer, io.confluent.kafka.serializers.protobuf.KafkaProtobufSerializer, io.confluent.kafka.serializers.protobuf.KafkaProtobufDeserializer.
Эти сериализаторы Confluent добавляют префикс из пяти байтов к сериализованному сообщению. Таким образом, сериализованное сообщение имеет следующую структуру в байтах:
- 0 — магический байт, номер версии формата сериализации Confluent, всегда равен нулю;
- 1–4 — идентификатор схемы, определенный в реестре схемы. Это целое число без знака емкостью 4 байта.
- 5 – сами данные, т.е. сериализованное сообщение для указанного формата схемы, например, двоичное кодирование для JSON, AVRO или Protobuf.
Могут существовать другие механизмы сериализации, которые могут иметь другое сопоставление байтов. Поэтому сериализация с помощью одного механизма и десериализация с помощью другого могут вызвать исключение или некорректно восстановить исходную структуру сообщения.
Чтобы сэкономить место, которое очень важно для Kafka, в каждое сообщение добавляется идентификатор схемы. Продюсеры и потребители должны использовать один и тот же реестр схем, чтобы получить одинаковое сопоставление между идентификатором схемы и ей самой. Когда потребитель десериализует сообщение, ему нужно знать только идентификатор схемы.
Публикация и потребление сообщений с реестром схем
Как уже было отмечено выше, продюсер при сериализации сообщения с использованием реестра схем будет взаимодействовать с кластером Schema Registry по протоколу HTTP, а также с кластером Kafka по TCP. Это означает, что у каждого продюсера будет два экземпляра клиента, по одному в каждом кластере. Когда для конфигурации auto.register.schemas установлено значение True, объект сериализатора отправляет POST-запрос в реестр схем, чтобы зарегистрировать схему, если она не существует, и получить соответствующий идентификатор схемы. Это не рекомендуется в производственных средах, но для разработки и тестирования может использоваться. Когда тому же экземпляру клиента-продюсера потребуется сериализовать другое сообщение, он не будет отправлять новый POST-запрос в реестр схем, поскольку схема и ее идентификатор кэшированы. Новый HTTP-запрос выполнится только при перезапуске клиента-продюсера, сериализации сообщения в другой топик или изменении схемы. При этом для объекта сериализатора в конфигурации use.latest.version надо установить значение False.
Если вместо этого оно будет True, а auto.register.schemas – наоборот, False, для получения последней схемы будет отправляться GET-запрос вместо POST. При этом вместо получения схемы, переданной при создании объекта сериализатора, будет использоваться ее последняя версия в топике.

Скрипт PlantUML для этой UML-диаграммы последовательности:
@startuml title Публикация сообщений в Kafka с использованием реестра схем Confluent participant Producer_Kafka_Client AS P participant Schema_Registry_Client AS C participant Schema_Registry_Cluster AS S participant Apache_Kafka_Cluster AS K alt auto.register.schemas=True и use.latest.version=False C -> S: POST-запрос на регистрацию схемы(схема данных в теле сообщения) S--> C: 200 OK, ID схемы else auto.register.schemas=False и use.latest.version=True C -> S: GET-запрос на последнюю версию схемы() S--> C: 200 OK, субъект, версия и ID схемы end alt loop пока идет публикация сообщений P -> K: publish(сериализованное сообщение + ID схемы) K-->P: ack end loop @enduml
Аналогично публикации сообщений с реестром схем, потребитель при десериализации данных полезной нагрузки взаимодействует с обоими кластерами: Kafka и Schema Registry. Поэтому потребитель тоже имеет два экземпляра клиента, по одному для каждого кластера. При вызове объекта десериализатора он отправляет запрос GET в реестр схемы, чтобы получить схему на основе ее идентификатора, 1-4 байты сериализованного сообщения.
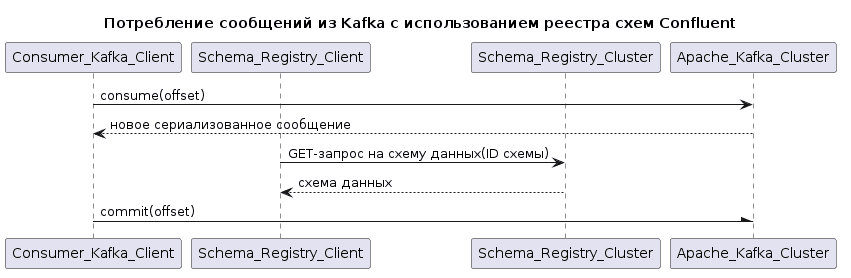
Скрипт PlantUML для этой UML-диаграммы последовательности:
@startuml title Потребление сообщений из Kafka с использованием реестра схем Confluent participant Consumer_Kafka_Client AS Co participant Schema_Registry_Client AS Cl participant Schema_Registry_Cluster AS S participant Apache_Kafka_Cluster AS K Co ->K: consume(offset) K--> Co: новое сериализованное сообщение Cl -> S: GET-запрос на схему данных(ID схемы) S-->Cl: схема данных Co -\K: commit(offset) @enduml
Таким образом, использование реестра схем вместе с Apache Kafka обеспечивает эволюцию данных, совместимость и управление распределенными компонентами, включая управление версиями и эффективное обнаружение ошибок. Schema Registry улучшает совместную работу, позволяя командам работать независимо над схемами полезной нагрузки сообщений, сохраняя обратную и прямую совместимость контрактов данных при асинхронной интеграции приложений-продюсеров и потребителей.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: