В прошлом году Databricks выпустили новый проект для ускорения потоковой передачи в Apache Spark. Сегодня рассмотрим, как именно Lightspeed сокращает задержку в операционных рабочих нагрузках Structured Streaming с помощью асинхронного управления смещением.
Операционные рабочие нагрузки и что их тормозит в Apache Spark Structured Streaming
Рабочие нагрузки потоковой передачи можно разделить на аналитические и эксплуатационные нагрузки. Аналитические рабочие нагрузки обычно принимают, преобразуют, обрабатывают и анализируют данные в режиме реального времени и записывают результаты в Delta Lake, поддерживаемое объектным хранилищем, таким как AWS S3, Azure Data Lake Gen2 и Google Cloud Storage. Эти результаты используются последующими механизмами хранения данных и инструментами визуализации. Например, к аналитическим нагрузкам относится анализ пользовательского поведения в режиме реального времени, анализ настроений, мониторинг транспортных потоков, качества воздуха, положения дрона и других IoT-устройств.
Операционные рабочие нагрузки принимают и обрабатывают данные в режиме реального времени, автоматически запуская какие-либо вычисления согласно заданным бизнес-правилам. К примеру, потоковая передача данных для мониторинга безопасности или производительности сети, чтобы отправить предупреждение в отдел безопасности при выявлении подозрительного трафика или несанкционированного доступа. Также можно просматривать системные логи, чтобы проинформировать ответственную команду при обнаружении утечки конфиденциальной информации. Операционные рабочие нагрузки также характерны для диспетчеризации устройств, например, мониторинг данных о температуре и запуск действий по ее снижению, когда это измерение превысит допустимый порог.
Потоковые конвейеры с операционными рабочими нагрузками обычно имеют следующие характеристики:
- низкая ожидаемая задержка обработки данных (менее секунды);
- чтение данных из потокового канала сообщений с выполнением простых вычислений по преобразованию или обогащению данных. Например, может использоваться Apache Kafka или Pulsar, NoSQL-хранилища типа ключ/значение Apache Cassandra или Redis.
В этих случаях использования Apache Spark Structured Streaming управление смещениями для отслеживания хода выполнения микропакетов требует значительного времени. Чтобы отслеживать ход обработки данных, Spark Structured Streaming использует сохранение и управление смещениями, которые используются в качестве индикаторов прогресса. Обычно смещение конкретно определяется исходным коннектором, поскольку разные системы имеют разные способы представления прогресса или __cpLocations в данных. Например, конкретной реализацией смещения может быть номер строки в файле. Для хранения этих смещений и отметки завершения микропакетов используются логи.
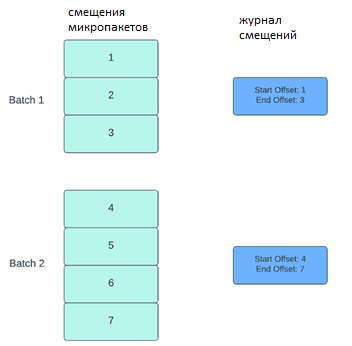
В Apache Spark Structured Streaming структурированной потоковой передаче данные обрабатываются микропакетами. Для каждого микропакета выполняются две операции по управлению смещением: в начале и в конце. В начале каждого микропакета до фактического начала обработки данных рассчитывается смещение на основе того, какие новые данные можно прочитать из целевой системы. Это смещение сохраняется в долговременном логе offsetLog в каталоге контрольных точек и используется для расчета диапазона данных, которые будут обработаны в этом микропакете. В конце каждого микропакета в логе сохраняется запись commitLog, указывающая, что это микропакет успешно обработан.
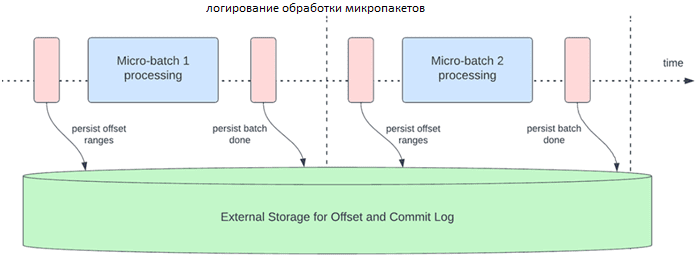
Другая операция управления смещением выполняется в конце каждого микопакета и представляет собой операцию очистки для удаления/усечения старых и ненужных записей из offsetLog и из commitLog, чтобы эти логи не слишком разрастались.
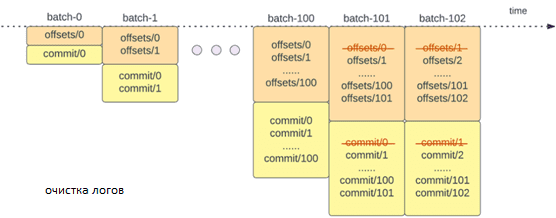
Эти операции управления смещениями выполняются одновременно с фактической обработкой данных. Поэтому их продолжительность напрямую влияет на задержку обработки, которая не может выполняться до завершения этих операций. В результате производительность кластера Apache Spark снижается, что особенно заметно для stateless-конвейеров, которые часто используются в операционных рабочих нагрузках и сценариях мониторинга в реальном времени. Именно поэтому компания Databricks,которая коммерциализирует и развивает Apache Spark, в 2022 году выпустила проект Lightspeed для ускорения потоковой обработки данных, о чем мы писали здесь. А в мае 2023 года анонсировала улучшения производительности за счет более эффективного управления смещением с помощью этого механизма, что и рассмотрим далее.
Асинхронное управлении смещениями
Прежде всего, следует упомянуть про асинхронное отслеживание прогресса. Включение этой опции позволяет конвейерам структурированной потоковой передачи проверять ход выполнения, т. е. обновлять offsetLog и commitLog асинхронно и параллельно с фактической обработкой данных в микропакете. Другими словами, фактическая обработка данных теперь не будет блокироваться этими операциями управления смещением, что значительно уменьшит задержку обработки данных.
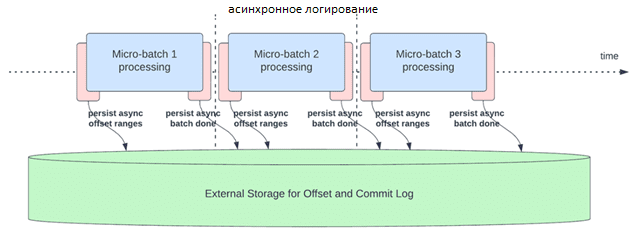
Для асинхронного выполнения обновлений можно настроить частоту проверки выполнения, что особенно полезно для сценариев, в которых операции управления смещениями происходят с большей скоростью, чем они могут быть обработаны. Это происходит в конвейерах, когда время, затрачиваемое на фактическую обработку данных, значительно меньше по сравнению с этими операциями управления смещением. В таких случаях будет возникать постоянно увеличивающееся отставание в операциях по управлению компенсациями. Чтобы остановить это растущее отставание, обработку данных придется заблокировать или замедлить, что возвращает ее к одновременному выполнению операций управления смещением. Как правило, разработчику Spark-приложения не приходится настраивать или устанавливать частоту контрольных точек, поскольку значение по умолчанию вычисляется наиболее оптимальным образом. Время восстановления после сбоя растет с увеличением времени интервала между контрольными точками. В случае сбоя конвейер должен повторно обработать все данные до предыдущей успешной контрольной точки. Разработчику следует найти баланс между меньшей задержкой во время обычной обработки и временем восстановления в случае сбоя. Для включения и настройки асинхронного выполнения обновлений логов используются следующие конфигурации:
- asyncProgressTrackingEnabled — включение или отключение асинхронного отслеживания прогресса, по умолчаниюfalse;
- asyncProgressCheckpointingInterval — интервал, в течение которого смещения фиксируются и завершаются фиксации, по умолчанию: 1 минута.
Следующий пример Java-кода показывает, как включить эту функцию:
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Эта функция не будет работать с Trigger.once или Trigger.availableNow, поскольку они выполняют конвейеры вручную или по расписанию и асинхронное отслеживание прогресса не актуально. Запрос завершится неудачно, если он отправлен с использованием любого из вышеупомянутых триггеров.
Пока асинхронное отслеживание прогресса поддерживается только в конвейерах без сохранения состояния с использованием приемника Kafka. При этом не поддерживается сквозная обработка с семантикой строго однократной доставки сообщений, поскольку диапазоны смещения для пакета могут быть изменены в случае сбоя. Впрочем, приемник Kafka поддерживает семантику at least once.
Аналогично асинхронному обновлению лога, его асинхронная очистка журнала позволяет ускорить обработку данных. Благодаря асинхронному характеру этой операции и ее выполнению в фоновом режиме, можно устранить накладные расходы, которые возникают при фактической обработке данных. Кроме того, подобные очистки не обязательно выполнять для каждого микропакета. Примечательно, что эта функция не имеет применима для всех типов конвейеров и рабочих нагрузок, поэтому она включена в фоновом режиме по умолчанию для всех конвейеров Apache Spark Structured Streaming.
Бесчмаркинговый тест производительности, проведенный дата-инженерами Databricks показал, что асинхронное отслеживание прогресса и асинхронная очистка логов сокращают задержку обработки данных почти в 3 раза, позволяя сэкономить около 500 мс без ухудшения пакетного планирования и обработки запросов. Эти улучшения производительности доступны на платформе Databricks Lakehouse начиная с DBR 11.3, а также внесены в исходный код Apache Spark и доступны с версии 3.4, об основных новинках которых мы рассказывали здесь.
Освойте возможности Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники