
Изоляция рабочих процессов и универсальное выполнение на удаленных машинах в обновленной клиент-серверной архитектуре, версионирование DAG, активы данных и изменения интерфейсов: главные новинки Apache AirFlow 3.0. Изоляция рабочих процессов и универсальное выполнение В марте 2025 года ожидается выпуск бета-релиза Apache AirFlow, а общедоступная версия (GA) выйдет в середине апреля. До этого...
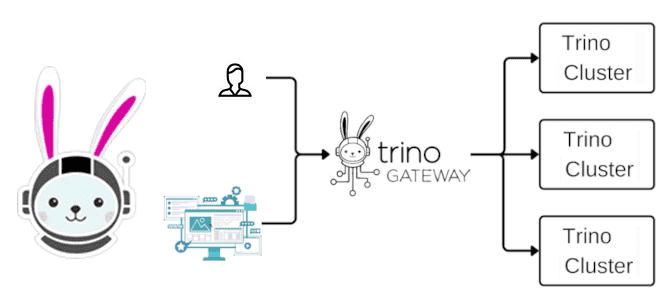
Что такое Trino Gateway, зачем он нужен и как работает: для чего делить один большой кластер Trino на несколько маленьких и как к ним обращаться без изменений на стороне клиентов. Проблемы бесконечного масштабирования кластера Благодаря горизонтальному масштабированию, о котором мы говорили вчера, кластер Trino можно расширять, добавляя новые рабочие узлы....
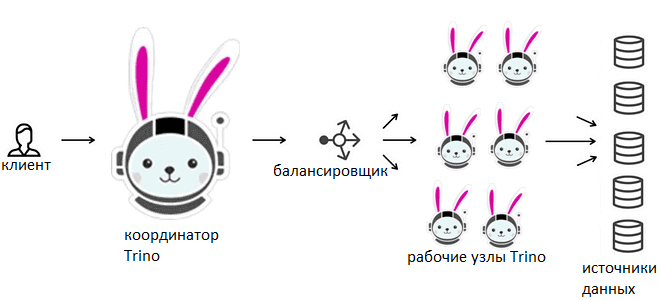
Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов. Масштабирование кластера Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают...

Как библиотека PemJa реализует потоковый режим выполнения Flink-заданий, где UDF-функции Python выполняются в JVM, ускоряя обработку данных за счет исключения межпроцессного взаимодействия. Выполнение PyFlink-приложения в JVM Хотя Flink-приложение работает в JVM-среде, фреймворк позволяет писать код не только на Java и Scala. О том, как работает PyFlink, Python-интерфейс для Apache Flink,...
Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие. Способы трансляции Python-кода для исполнения в JVM Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python...
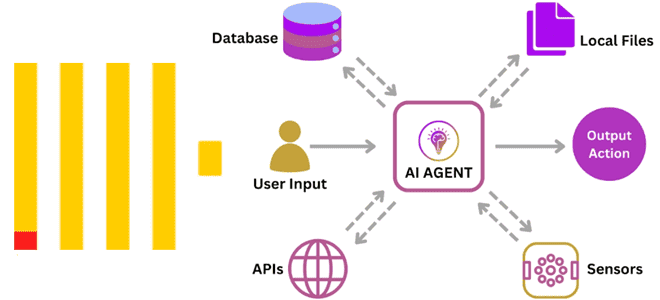
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...
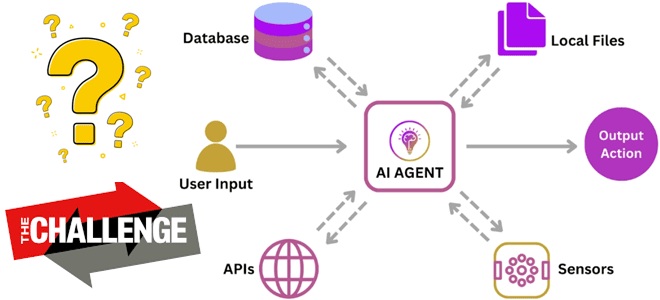
Чем хорош агентский ИИ, какие риски и проблемы с ним связаны, и как их избежать: технические и организационные меры внедрения ML-систем в реальный бизнес. Что сдерживает внедрение агентского ИИ Мы уже писали об агентском ИИ, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без...
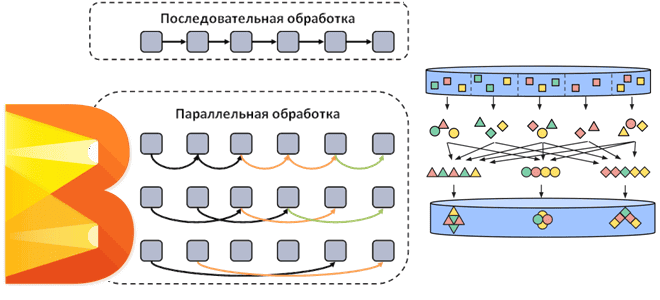
Как Apache Beam распараллеливает потоковые и пакетные конвейеры обработки данных, добавляя собственные операции к пользовательским преобразованиям. Смотрим на примере простого пакетного конвейера с ограниченным параллелизмом. Распараллеливание операций в Apache Beam Напомним, Apache Beam представляет собой унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить в любой...

Мы уже писали о том, как Trino работает с удаленными объектными хранилищами и файловыми системами. Сегодня поговорим о том, какие изменения выпущены в февральском релизе 2025 года, почему в Trino удалена поддержка доступа к Azure Storage, Google Cloud Storage, S3 и S3-совместимым файловым системам через Hive и что использовать вместо...

7 февраля 2025 года вышел очередной релиз ClickHouse. Знакомимся с его главными новинками: ускорение параллельного хэш-соединения, индексы MinMax на уровне таблицы, автоинкременты полей и улучшенное объединение таблиц с табличной функцией merge. Улучшение параллельного хэш-соединения в ClickHouse 25.1 В ClickHouse 25.1 добавлено 15 новых функций, 36 улучшений и 77 исправлений ошибок....
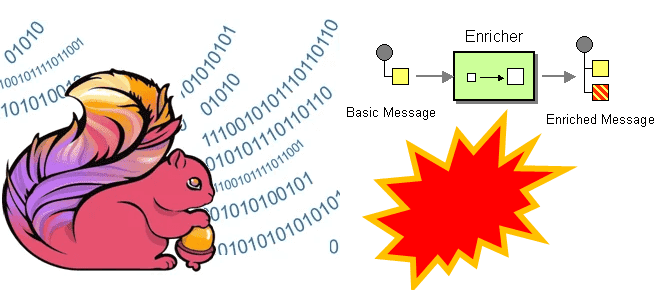
Как FLIP-304 помогает понять причину сбоя и повысить надежность Flink-приложения: обогащение типовых сообщений об ошибках пользовательскими метаданными. Зачем нужен FLIP-304 и как это позволяет дополнять сообщения об ошибках при сбоях заданий Apache Flink Хотя Apache Flink имеет встроенные механизмы обеспечения отказоустойчивости, такие как контрольные точки и точки сохранения, а также...

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Как устроен механизм отказоустойчивого выполнения в Trino, чем политика повтора QUERY отличается от TASK, зачем настраивать диспетчер обмена на внешнее S3-совместимое хранилище и задавать коэффициент задержки перед повторными попытками выполнить SQL-запрос. 2 политики отказоустойчивого выполнения в Trino Будучи движком online-обработки больших объемов данных с помощью распределенных SQL-запросов, Trino должен иметь...
Как получить спецификацию AsyncAPI из кода с помощью декораторов функций публикации и потребления сообщений средствами Python-библиотеки FastStream: простой пример потокового конвейера на Apache Kafka. Еще раз про FastStream и спецификацию AsyncAPI Вчера я рассказывала про Python-библиотеку FastStream для разработки потоковых конвейеров на Apache Kafka, RabbitMQ, NATS и Redis. Помимо мощного,...

Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений. О библиотеке FastStream Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а...
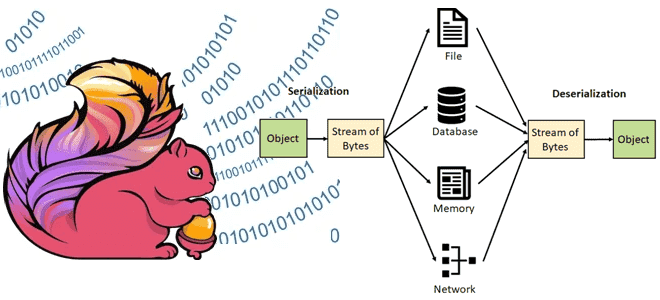
Какие типы данных поддерживает Apache Flink, как сериализация влияет на скорость обработки, зачем выбирать специализированные типы данных вместо общих структур и возможно ли изменение схемы данных без перезапуска приложения. Типы данных в Apache Flink В Apache Flink сериализация играет ключевую роль в процессе обработки данных, обеспечивая преобразование объектов в байтовый...
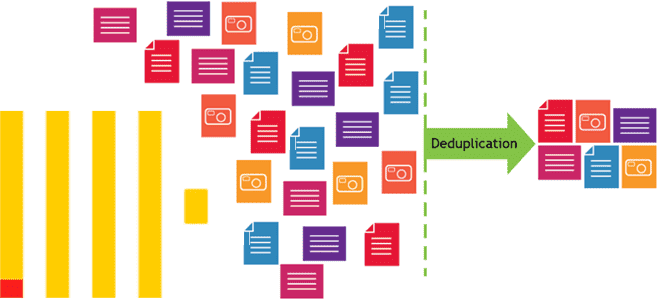
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...
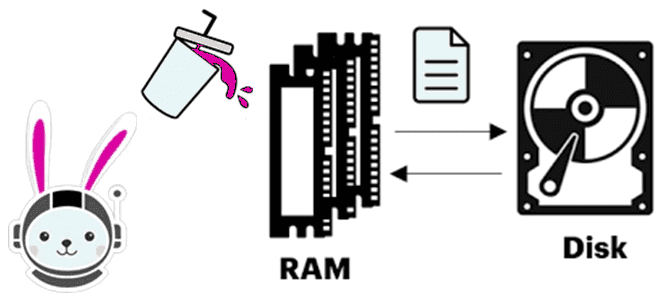
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...