
Изоляция рабочих процессов и универсальное выполнение на удаленных машинах в обновленной клиент-серверной архитектуре, версионирование DAG, активы данных и изменения интерфейсов: главные новинки Apache AirFlow 3.0.
Изоляция рабочих процессов и универсальное выполнение
В марте 2025 года ожидается выпуск бета-релиза Apache AirFlow, а общедоступная версия (GA) выйдет в середине апреля. До этого крупный выпуск выходил 5 лет назад: версия 2.0 в 2020 году. В выпуске 3.0 нас ждет много нового: внешнее выполнение задач, явное управление версиями DAG, планирование на основе событий и разделение API и GUI.
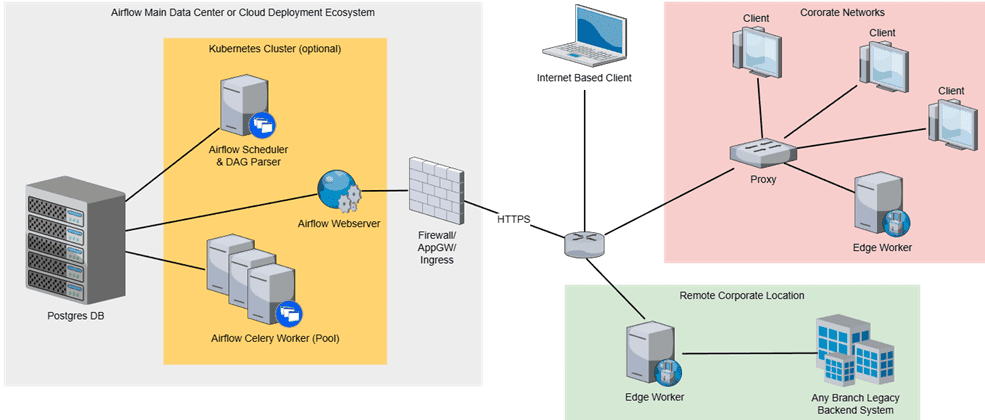
Начнем с главного изменения – изоляции рабочих процессов. Раньше рабочие процессы Airflow обычно развертывались внутри самого фреймворка, например, как поды Kubernetes или рабочие процессы Celery. Хотя добавление отстроченных операторов позволило запускать асинхронные рабочие процессы, освобождая слоты, изначально Airflow не поддерживал запуск рабочих процессов на удаленных машинах. Но это станет возможным с версии 3.0, чтобы обеспечить выполнение конвейеров обработки данных в любой среде и на любом языке. Основой для этого стал интерфейс выполнения задач (Task Execution Interface), позволяющий преобразовать развертывание Airflow в клиент-серверную архитектуру. Эта новая функция обеспечивает облачные развертывания и мультиязычную поддержку. Функция поддерживает удаленные исполнители Celery и Kubernetes, а также локальный Local Executor. Дополнительно в релизе AirFlow 3.0 появился Edge Executor— вариант исполнителя, который распределяет задачи по удаленным машинам (Edge Worker).
При этом рабочие процессы больше не будут включаться развертывание Airflow и не смогут получить доступ к базе данных метаданных напрямую, а будут взаимодействовать с ней через REST API фреймворка, для аутентификации используя JWT- или ID-токены в заголовке HTTP-запроса. Чтобы сократить зависимости, рабочие процессы больше не будут привязаны к пакетам Airflow или пользовательскому образу. Для запуска внешнего рабочего процесса придется использовать отдельный пакет провайдера, который намного легче базового образа Airflow и включает все необходимые инструменты и зависимости.
Это существенное изменение, которое не только позволяет запускать тяжеловесные конвейеры обработки данных где угодно и писать задачи на любом языке программирования. Еще новая архитектура повышает безопасность фреймворка и качество разработки кода, не позволяя напрямую спускаться на уровень базы данных метаданных.
Версионирование DAG
Одной из причин популярности Airflow – это представление конвейера обработки данных в виде единого графа, т.е. DAG. Фреймворка позволяет управлять версиями DAG, но запускает конвейер, постоянно анализируя изменения в DAG-файле. Это не эффективно, т.к. вынуждает дата-инженера ждать, пока изменения будут отражены. Чтобы улучшить это и повысить уровень контроля над версиями DAG, позволяя запускать не только последнюю, а выбирать нужную, в AirFlow 3.0 появились комплекты – файлы, которые определяют DAG. Такой комплект называется DAG Bundle. Любой файл можно поместить в DAG Bundle, и он будет версионирован, если бэкенд это поддерживает. DAG Bundle реализует управление версиями, позволяя Airflow контролировать версию кода DAG, используемого для данной попытки запуска задачи, т.е. Task Instance. Это означает, что запуск DAG может продолжаться на том же коде DAG для всего запуска, даже если DAG был изменен, поскольку рабочий процесс может получить определенный пакет DAG при запуске задачи. Каждый экземпляр задачи (Task Instance) будет использовать определенный DAG Bundle для запуска.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
1 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
При этом Airflow будет работать только с полными пакетами DAG, не пытаясь идентифицировать или извлечь часть файлов. Разумеется, для хранения и обработки всех DAG Bundle нужно отдельное выделенное пространство и бэкенд, обеспечивающий одновременное версионирование целого набора файлов. А поскольку из-за удаленного запуска DAG может не находиться на локальной машине, Airflow меняется способ извлечения DAG. По умолчанию запуски DAG будут выполняться на одном и том же пакете DAG для всего запуска, предполагая, что бэкэнд файла DAG поддерживает версионирование. Однако, вместо этого можно выбрать продолжение существующего поведения запуска на последнем коде DAG.
Чтобы уменьшить зависимость от внешних систем, бэкенд DAG Bundle будет поддерживать локальное кэширование и настраиваемое размещение файлов. А для реализации подхода IaaS (Infrastructure as a Code) вместо непрерывного парсинга файлов DAG, бэкенд DAG Bundle будет поддерживать YAML-манифесты. В этих YAML-файлах можно описать, нужно ли сканировать файлы, содержащие DAG, в папках DAG и как часто это делать, задач список файлов для парсинга, его частоту и условия, например, при изменении контрольной суммы файлов.
По умолчанию планировщик при создании новых запусков DAG всегда будет использовать последнюю версию. При этом планировщик сможет указать DAG Bundle при отправке задачи исполнителю, чтобы запустить задачу на конкретной версии комплекта. Исполнитель сообщит рабочему процессу, с какой версией DAG Bundle нужно запустить задачу. Затем worker может использовать бэкэнд DAG Bundle, чтобы получить DAG Bundle и выполнить задачу. Если worker способен выполнять более одной задачи, как рабочий процесс LocalExecutor или CeleryExecutor, он сможет хранить DAG Bundle на временном диске и использовать его для нескольких задач. Причем комплекты DAG могут храниться, даже если ни одна задача в данный момент не использует эту версию DAG Bundle.
Управление на основе данных и событийное планирование
Понятие актива данных (Data Assets) существует во многих популярных инструментах дата-инженерии, например, Great Expectations, Atlan и Dagster. В AirFlow 3.0 решено переименовать Dataset в Asset и декомпозировать его на типы. Актив данных — это генерализованное представление логически связанных данных, например, таблица в реляционной базе данных, модель машинного обучения, аналитический дашборд или отчет, каталог с файлами и т.д.
С точки зрения программирования активы можно рассматривать как сущности внутри функции, которые генерируются при ее вызове и выполнении. Активы могут создаваться как одноразовые события, но чаще всего обновляются периодически, постоянно или до определенного момента времени. Каждое выполнение задачи изменяет в данные активе. Для повышения надежности и наблюдаемости данных Airflow нужна возможность определять влияние таких изменений на другие зависимые активы и, при необходимости, воссоздать измененные записи. Например, при замене таблиц БД, вставке или обновлении записей, создании новых файлов в каталоге, публикации новой версии ML-модели или новой итерации аналитического отчета. Это улучшает управляемость и наблюдаемость данных, положительно влияя на их качество.
Еще одним важным изменением в Apache Airflow 3.0 стала возможность планирования запуска рабочих процессов на основе событий. Исторически фреймворк был предназначен для пакетных процессов, запускаемых по расписании и с учетом зависимостей. Однако, современные архитектуры данных часто требуют обработки в режиме, близком к реальному времени, и быстрой реакции на события из потоковых источников, таких как очереди сообщений. Airflow уже позволяет создавать рабочие процессы на основе событий, используя внешний датчик задач, отстроченные операторы, REST API и Dataset (в будущем Asset). Именно активы данных позволят реализовать в Airflow автоматическое планирование на основе внешних событий. Это будет сделано двумя вариантами:
- планирование на основе опросов и событий, где Airflow постоянно отслеживает состояние внешнего ресурса и обновляет актив всякий раз, когда внешний ресурс достигает заданного состояния. Для этого планируется использовать триггеры – небольшие асинхронные фрагменты Python-кода, которые опрашивают состояние внешнего ресурса. Сегодня триггеры в Airflow используются только для отстроченных операторов, но их применение будет расширена на обновление активов на основе внешних условий.
- планирование на основе событий с push-уведомлениями, где Airflow будет получать от внешней системы push-уведомление при событии изменения, случившегося на ее стороне. Как это будет работать, подробнее рассмотрим в новой статье.
В заключение отметим изменения в интерфейсах. В Airflow 3.0 будет снижена зависимость ядра от Flask App Builder (FAB), с которым была связана критическая уязвимость CVE-2024-25128. Для этого GUI переходит на современный фронтенд-стек. React (TypeScript, React Query), который позволяет более гибко настраивать пользовательский интерфейс Airflow, используя плагины React вместо шаблонов Flask.
Хотя GUI и API фреймворка будут полностью разделены, GUI будет полностью построен поверх REST API Airflow. Это не только унифицирует пользовательские операции, но и позволит повысить их безопасность. Также будет улучшен CLI-интерфейс, чтобы облегчить обслуживание платформы. Подробнее обо всем этой читайте в нашей новой статье.
Освойте все эти и другие тонкости администрирования и эксплуатации Apache AirFlow вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

