
Почему в кластере Trino может возникнуть OOM-ошибка и как справиться с нехваткой памяти, оптимизировав SQL-запросы и настроив конфигурации: примеры и рекомендации. Причины OOM-ошибок в кластере Trino и как их устранить Для Trino, как и для многих JVM-приложений, характерны проблемы с управлением памятью, включая возникновение OOM-ошибок (Out Of Memory). Это связано...
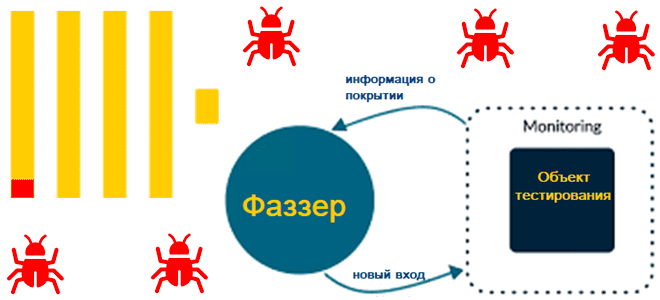
Что такое фаззинг-тестирование, зачем нужен новый фаззер для ClickHouse, и как BuzzHouse выявляет сложные проблемы и потенциальные уязвимости самой популярной колоночной СУБД, Что такое фаззинг-тестирование баз данных Поскольку база данных тоже программный продукт, перед выпуском в релиз она тестируется. Используемых при этом методов тестирования довольно много, и одним из них...

Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...
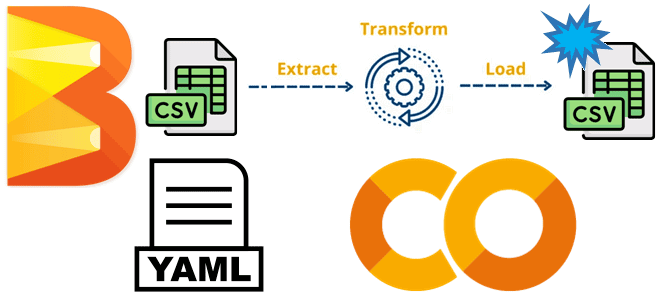
Как написать конвейер обработки данных Apache Beam, задав цепочку преобразований в YAML-конфигурации: практический пример фильтрации и агрегации платежей из CSV-файла. Пример разработки и запуска YAML-конвейера Apache Beam в Google Colab Недавно я рассказывала про Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
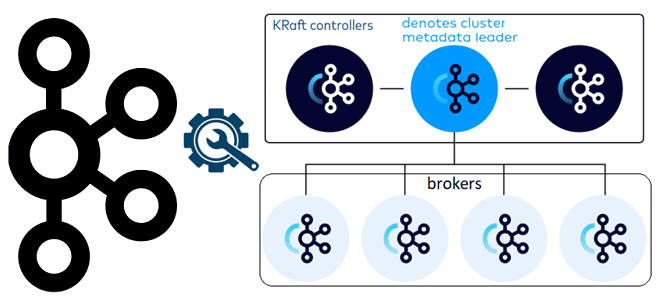
Чем контроллеры Kafka в режиме KRaft отличаются от режима Zookeeper, как их настроить и чем статический кворум отличается от динамического: краткий ликбез для администратора кластера. Брокеры и контроллеры: новые роли серверов Kafka в режиме KRaft Поскольку уже совсем скоро, в мажорном релизе Kafka 4.0, ожидается полный отказ от Zookeeper в...

Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии. О важности потоковой обработки данных и EDA-архитектуры для LLM-систем Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку...
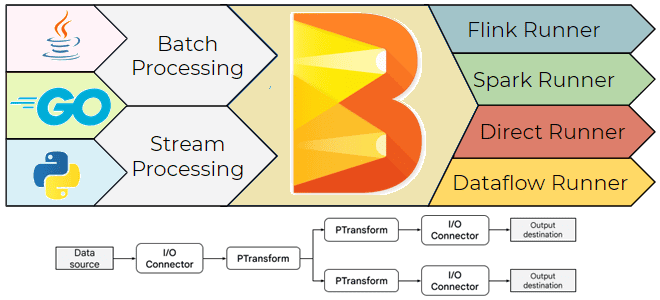
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...
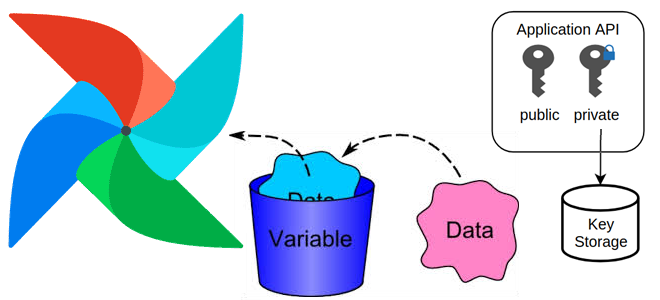
Зачем нужны переменные в Apache AirFlow, какие они бывают, как создать переменную и использовать ее: примеры и рекомендации для эффективной дата-инженерии. Зачем нужны переменные в Apache AirFlow, и какие они бывают Чтобы хранить информацию, которая редко меняется, например, ключи API, пути к конфигурационным файлам, в Apache Airflow используются переменные. Переменные...
Почему репортеры мониторинга системных метрик Flink, отправляющие данные в Prometheus, не решают проблемы предварительной обработки измерений с IoT-устройств, и как новый коннектор расширяет сферу применения фреймворка потоковой обработки. Встроенные средства мониторинга системных метрик Flink В декабре 2024 года вышел новый коннектор Apache Flink к Prometheus – популярной базе данных временных...
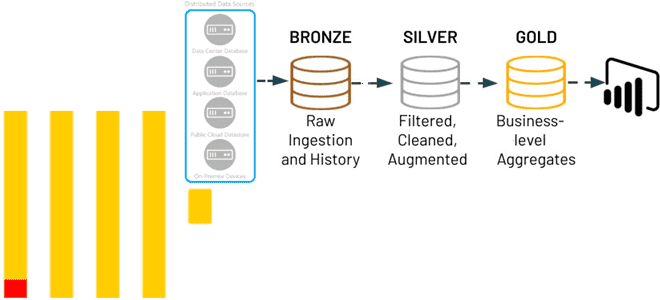
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...

Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
Где и как задавать настройки безопасного доступа клиента к кластеру Trino, каким образом обеспечить безопасность внутри кластера и защитить доступ к внешним источникам данных: примеры конфигураций. Как настроить безопасную работу кластера Trino По умолчанию в Trino не включены функции обеспечения безопасности. Однако, это можно настроить для различных частей архитектуры фреймворка:...
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch. ETL-конвейер Flink CDC в YAML-файле Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink...

Как Quix Streams реализует отказоустойчивую stateful-обработку потоковых датафреймов из топиков Kafka с помощью встроенного key-value хранилища состояний RocksDB: практический пример. Потоковый stateful-конвейер на Apache Kafka и Quix Streams Продолжая знакомиться с библиотекой Quix Streams, которая позволяет получить потоковые датафреймы из данных в топиках Kafka, сегодня разберем, как здесь организована работа...

Быстрая и простая обработка потоков сообщений в одном приложении с Quix Streams вместо Kafka Streams: практический пример на Python с обогащением и фильтрацией данных. Практический пример потокового конвейера с Apache Kafka и Quix Streams Сегодня я познакомилась с Quix Streams - очередной замечательной библиотекой для создания потоковых конвейеров обработки данных...
В чем сложности оркестрации параллельных заданий в Kubernetes и как их решить с помощью Argo Workflows: обзор фреймворка и практический пример YAML-спецификации шаблона рабочего процесса для развертывания веб-приложения. Что такое Argo Workflows и зачем он нужен Оркестрация параллельных заданий на платформе Kubernetes довольно сложна из-за их внутренних зависимостей друг от...

Как расширение Citus повышает производительность PostgreSQL, организуя распределенный кластер с помощью шардирования и почему этого недостаточно для эффективных OLAP-запросов как в Greenplum. Что такое Citus для PostgreSQL Поскольку Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных, у тех, кто знакомится с...

Как работает исполнитель Celery в Apache AirFlow, зачем ему очередь сообщений и каким образом это помогает масштабировать параллельное выполнение задач. Как работает исполнитель Celery в Apache AirFlow Именно исполнитель (Executor) в Apache Airflow отвечает за выполнение задач в рабочих процессах, определяя их локацию и последовательность, а также использование ресурсов. Хотя...
Зачем создавать разные проекции таблиц в базе данных и как это работает в Clickhouse: практический пример с агрегатным запросом. Возможности и ограничения механизма проекций в колоночной аналитической СУБД. Что такое проекции и как они реализованы в ClickHouse Поскольку основное назначение ClickHouse – аналитика больших объемов данных в реальном времени, это...