 729
729 
Содержание
Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие.
Способы трансляции Python-кода для исполнения в JVM
Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python API, позволяя писать код на Python, который будет работать в JVM-среде. Под капотом этого улучшения пользовательского опыта выполняется ряд довольно сложных преобразований, которые позволяют коду Python вызывать, контролировать или встраивать объекты Java так, будто он взаимодействует с собственными API, но эти вызовы делегируются Java API. Это работает и в обратную сторону, когда структуры данных со стороны JVM передаются на сторону Python.
Например, при запуске PySpark или PyFlink-приложения, главным процессом является Python-скрипт, который выполняет роль драйвера, отвечающего за координацию выполнения задач. Он инициирует соединение с JVM, где работают основные компоненты фреймворка. При этом запускается дополнительный JVM-процесс, который содержит ядро Spark или Flink. Этот JVM-процесс управляет распределенной обработкой данных, распределением задач между узлами кластера и управлением ресурсами. Основные вычисления происходят внутри JVM, что обеспечивает высокую скорость, кроссплатформенность и оптимизированное использование ресурсов. Однако, межпроцессное взаимодействие имеет накладные расходы и сложности в реализации. Вообще организовать межпроцессное взаимодействие Java и Python можно несколькими способами:
- схема сетевой коммуникации, т.е. взаимных вызовов между процессами. Сюда относится использование сокетов с готовыми протоколами коммуникации и схемы библиотеки Py4J для написания заданий на стороне клиента, что применяется в PySpark и PyFlink. Также схема Alink, которая использует библиотеку Py4J во время выполнения, и имеет пользовательские функции Python. Сюда же можно отнести схему gRPC, которая использует существующий RPC-сервис, не требует пользовательского протокола, имеет пользовательские службы и сообщения со строгими структурами данных.
- использование общей памяти для межпроцессного взаимодействия. Например, так работает Tensorflow на Flink и PyArrow Plasma, которая является объектно-ориентированным хранилищем общей памяти.
- преобразование кода Python в Java;
- интерфейс внешних функций FFI (Foreign Function Interface).
Вспомнив сложности межпроцессного взаимодействия, далее рассмотрим подробнее варианты его реализации через преобразование кода Python в Java и FFI.
Преобразование кода Python в Java
Для перевода Python-кода в Java используются соответствующие трансляторы. Например, P2J – транслятор исходного кода, преобразующий синтаксис Python в эквивалент Java и профилировщик, который использует отладчик Python и инструменты AST для индексации всей информации об аргументах методов времени выполнения при выводе типа. Или VOC — транспилятор, т.е. транслятор и компилятор, преобразующий код Python в байт-код Java. Он предоставляет API, позволяющий программно создавать файлы классов Java, компилирует исходные файлы Python в файлы классов Java, позволяя запускать код Python на JVM, включая виртуальную машину Android.
Суть этих решений заключается в преобразовании Python в набор кодов, которые могут работать непосредственно на JVM. Но Python постоянно развивается и у него множество различных грамматик, которые сложно сопоставить с соответствующими объектами в Java. Вместо этого можно реализовать интерпретатор Python на основе Java, такой как Jython— реализация языка Python для выполнения программ на платформе Java. Однако, Jython больше не поддерживает Python 3 и не поддерживается активно. На самом деле Python имеет целый набор интерпретаторов, написанных на языке C. Интерпретатор Python, написанный на C, может работать поверх C. Поэтому интерпретатор Python, реализованный на Java, также может работать непосредственно в JVM.
Еще одним решением может быть Graalvm – виртуальная машина Java и JDK на Java. GraalVM поддерживает разные языки программирования и модели выполнения, такие как JIT- и AOT-компиляция. GraalVM предоставляет структуру реализации языка Truffle — библиотеку с открытым исходным кодом для создания инструментов и реализаций языков программирования в качестве интерпретаторов для самомодифицирующихся абстрактных синтаксических деревьев (AST, Abstract Syntax Tree). Этот фреймворк поддерживает различные языки программирования для использования общей структуры так, чтобы они работали на JVM в одном процессе. Решение основано на распознавании кода Python и его сопоставлении с подобными структурами в Java. Такое сопоставление и преобразование довольно сложная задача. Truffle поддерживает не все библиотеки Python, а также работает только с GraalVM, что означает высокие затраты на миграцию.
Интерфейс внешних функций
Интерфейс внешних функций FFI — это механизм, с помощью которого программа, написанная на одном языке программирования, может вызывать подпрограммы, написанные на другом языке. Связывание одного языка программирования с другим – довольно непростая задача. Язык, для которого создаётся интерфейс к другому языку, должен разбираться в соглашениях вызова, системе типов, структурах данных, механизмах выделения памяти и методов линковки целевого языка для корректной работы. Для корректной передачи данных семантика обоих языков должна быть тщательно согласована. Добавление FFI к типобезопасному языку может внести набор операций, нарушающих безопасность неочевидными способами. Это как раз характерно для Java, которая является типобезопасным языком, в отличие от Python. Типобезопасные языки стремятся предотвратить ошибки, связанные с несоответствием типов данных, обеспечивая строгую проверку типов во время компиляции или выполнения программы. Однако при использовании FFI возникает необходимость взаимодействия с кодом, написанным на других языках, которые могут не соблюдать те же правила типобезопасности.
Это происходит по следующим причинам:
- отсутствие автоматической проверки типов — при вызове функций из других языков через FFI типобезопасный язык может иметь ограниченные механизмы для проверки соответствия типов данных. Это может привести к передаче некорректных или неожиданно сформированных данных, что нарушает гарантии безопасности типизации.
- ручное управление памятью – многие FFI-интерфейсы требуют ручного управления памятью, что увеличивает риск утечек памяти, повреждения данных или других ошибок, связанных с памятью. Такие операции часто обходят автоматические механизмы управления памяти, предоставляемые типобезопасным языком.
- вызов низкоуровневых функций – FFI позволяет вызывать низкоуровневые функции операционной системы или сторонних библиотек, которые могут выполнять операции, несоответствующие ожиданиям типобезопасного языка. Это может включать прямой доступ к аппаратным ресурсам или выполнение системных вызовов, обходящих механизмы безопасности языка.
Например, Java предоставляет собственный интерфейс (JNI, Java Native Interface) для взаимодействия с нативными библиотеками, написанными на языках C или C++. Если разработчик некорректно управляет указателями или передает неправильные типы данных, это может привести к сбоям JVM или к выполнению непредсказуемого кода. Так некорректная работа с массивами или строками может привести к возврату неверных данных или даже к уязвимостям. Поскольку Python, в отличие от Java, динамически типизирован, это уже само по себе увеличивает риск ошибок типизации. Также неправильное определение типов аргументов или возвращаемых значений может привести к сбоям интерпретатора или непредсказуемому поведению программы.
Хотя Python не является строго типобезопасным языком из-за своей динамической типизации, использование FFI в Python также может нарушать безопасность, но механизмы защиты и диагностики отличаются. В Python ошибки типов могут быть выявлены во время выполнения, но из-за динамической природы языка некоторые проблемы могут быть обнаружены только при запуске конкретных участков кода.
Итак, суть FFI в том, что нативный язык вызывает гостевой, реализуя взаимные вызовы между Java и Python. JNI позволяет пользователям Java вызывать некоторые С-библиотеки и наоборот. Поэтому разработчики JVM реализуют JNI, чтобы осуществить взаимные вызовы между языками Java и С. Подобное решение подходит и для Python, который имеет набор интерпретаторов, реализованных на языке С. Таким промежуточным слоем между Python и С/С++ является Cython — язык программирования, позволяющий писать код на С/C++ для Python-приложений. Это в десятки раз повышает быстродействие Python-кода. К примеру, можно преобразовать код Python в очень эффективный код на C, а затем встроить его в интерпретатор CPython для непосредственного запуска.
Python-библиотека внешних функций ctypes предоставляет C-совместимые типы данных и позволяет вызывать функции из DLL или разделяемых библиотек. Таким образом Python-код может эффективно вызывать инкапсулированные C-библиотеки. Ядром такого взаимодействия на основе FFI является C. Так Java-код может вызывать C через интерфейс JNI, а затем C вызывает API CPython, обеспечивая работу Java и Python в одном процессе. Именно так работает JPype –расширение Python, позволяющее Python-программе получить полный доступ к библиотекам классов Java. По сравнению с Jython, JPype работает быстрее и дает доступ ко всем Python-расширениям. Хотя JPype позволяет вызвать Java из Python, он не работает в обратную сторону, т.е. не поддерживает вызов Python из Java. Обойти это можно с помощью JEP (Java Embedded Python), который встраивает CPython в Java через JNI.
Но JEP можно установить только с исходным кодом. В частности, JEP не предоставляет JAR-архив в репозиторий Maven, а процесс загрузки собственных пакетов необходимо указывать заранее через параметры JVM или переменные среды при запуске JVM, что довольно затруднительно. JEP ссылается на некоторые файлы .source из CPython, что не очень подходит для кроссплатформенной установки. Запуск JEP должен быть программой, которая заранее установлена в переменной среды и динамически загружает библиотеку классов. Это не позволяет запускать ее в другой архитектуре в качестве стороннего плагина промежуточного ПО. Наконец, JEP имеет проблемы с производительностью. Он не очень хорошо справляется с проблемами глобальной блокировки интерпретатора (GIL, Global Interpreter Lock) в Python, что снижает его производительность.
Напомним, Python для синхронизации потоков использует GIL – мьютекс, примитив синхронизации для взаимного исключения исполнения критических участков кода. Он блокирует доступ к объекту интерпретатора Python в многопоточных средах, разрешая выполнять лишь одну инструкцию за раз. Это обеспечивает безопасность и целостность данных, но ограничивает многозадачность и эффективную утилизацию многоядерных процессоров. Избежать этих проблем можно с библиотекой PEMJA (Python Embedded Java), о которой мы поговорим далее.
Как работает библиотека PEMJA
PEMJA – это кросс-языковая инфраструктура вызовов с открытым исходным кодом на основе интерфейса внешних функций FFI. Подобно JEP и JPype, PEMJA основана на CPython, поэтому не может поддерживать другие интерпретаторы Python, такие как PyPy и пр. Впрочем, именно CPython является наиболее часто используемой реализацией и официальным стандартом Python Runtime. Поэтому большинство Python-библиотек построены на основе CPython Runtime и могут работать с PEMJA естественным образом.
PEMJA обеспечивает высокопроизводительную структуру вызовов между Python и Java, позволяя их виртуальным машинам вызывать друг друга в одном и том же процессе через эту библиотеку. PEMJA запускает поток-демон в JVM, который отвечает за инициализацию среды Python и создание основного интерпретатора Python, принадлежащего этому процессу. Выделенный поток для инициализации среды Python позволяет PEMJA избежать потенциальных взаимоблокировок в интерпретаторе Python, который может заблокироваться при попытке получить GIL через такие методы, как PyGILState_* в API Python/C одновременно. Хотя PEMJA не вызывает эти методы напрямую, их могут вызывать что сторонние библиотеки, например, numpy и пр. Чтобы обойти это, используется выделенный поток для инициализации среды Python. Затем каждый рабочий поток Java может вызывать функции Python через Python ThreadState, созданный из Python Main Interpreter.
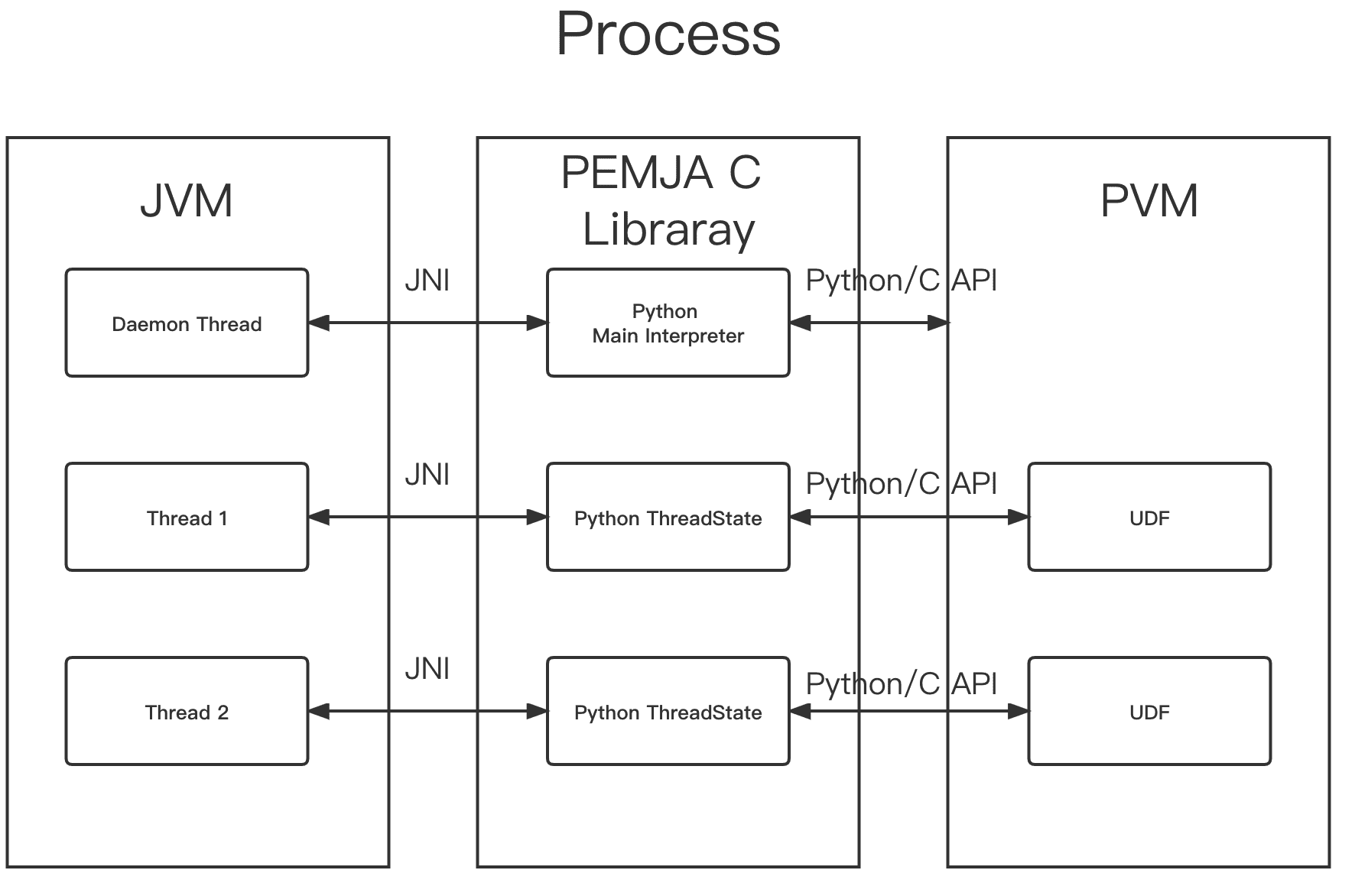
Высокая производительность PEMJA и двусторонняя совместимость вызова Java-классов и методов непосредственно из Python-кода привела к тому, что именно эта библиотека стала использоваться в Apache Flink для реализации поточного режима THREAD. Об этом мы поговорим завтра. А о том, как строить мультиязычные конвейеры обработки данных в Apache Beam, используя преобразования из разных SDK, читайте в новой статье.
Освойте возможности Apache Spark и Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

