
Как библиотека PemJa реализует потоковый режим выполнения Flink-заданий, где UDF-функции Python выполняются в JVM, ускоряя обработку данных за счет исключения межпроцессного взаимодействия.
Выполнение PyFlink-приложения в JVM
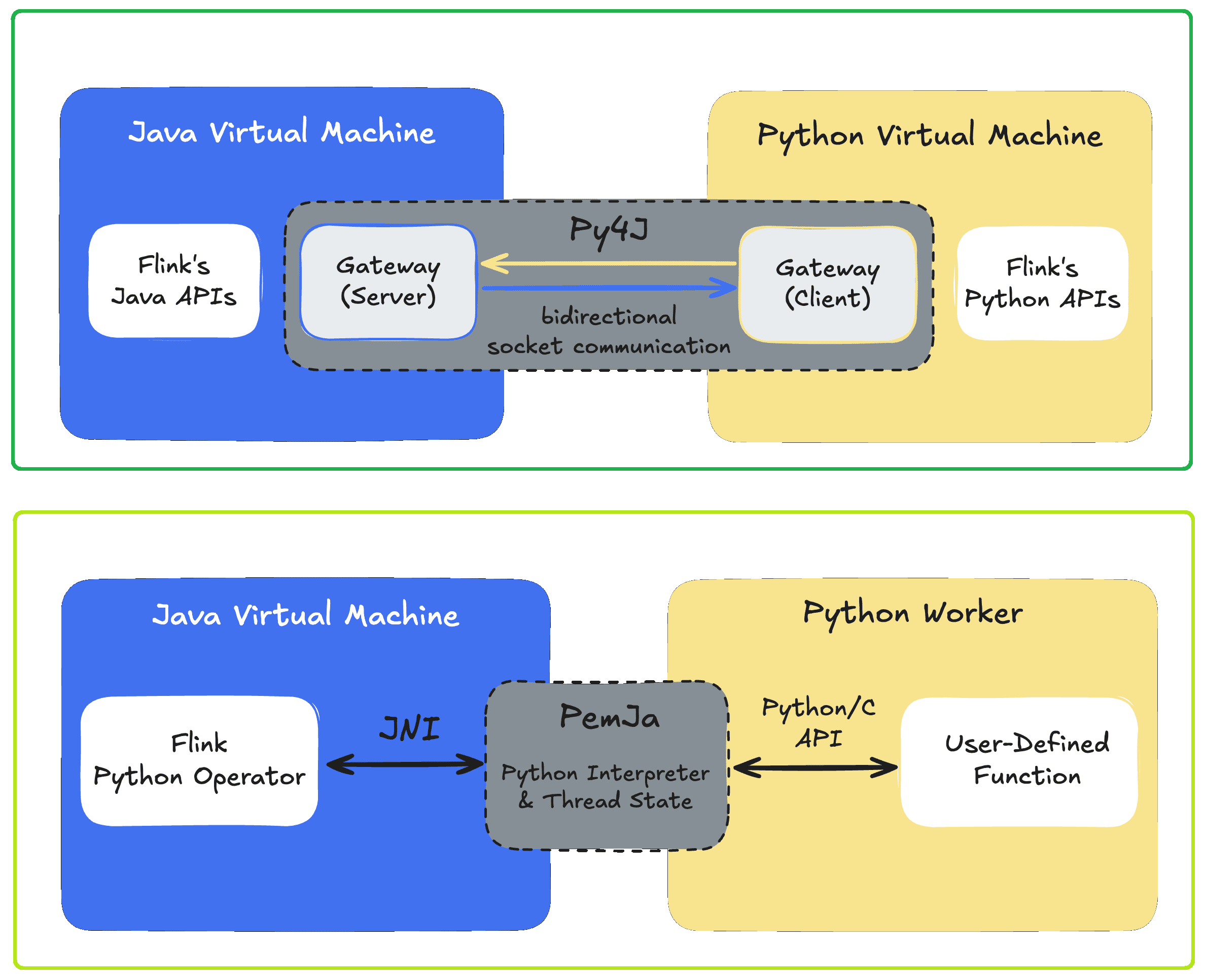
Хотя Flink-приложение работает в JVM-среде, фреймворк позволяет писать код не только на Java и Scala. О том, как работает PyFlink, Python-интерфейс для Apache Flink, предоставляющий среду для разработки Flink-приложений на Python и их развертывания в кластере Flink, я писала здесь. Однако, помимо Java-библиотеки Py4J, которая позволяет динамически взаимодействовать с объектами JVM, позволяя Python-программе в процессе Python получать доступ к объектам Java в JVM, в 15-ой версии фреймворка появилась альтернатива – PemJa (Python Embedded Java). Чтобы разобраться, чем она отличается от Py4J, сперва вспомним основные принципы работы PyFlink.
Программа PyFlink реализуется на двух уровнях:
- уровень управления, где определяется граф заданий на Python, соединяясь с Java API Flink;
- уровень данных, где код пользовательской функции выполняется в отдельном процессе или внедряется через JNI (Java Native Interface) – стандартный механизм для запуска кода под управлением JVM. Написанный на C/C++ или Ассемблере и скомпонованный в виде динамических библиотек, JNI позволяет не использовать статическое связывание. Благодаря этому байт-код Java, т.е. набор инструкций для JVM, может взаимодействовать с системным или прикладным кодом, запущенным на разных операционных системах.
При разработке программы на PyFlink, эти два уровня связываются способами, которые позволяют коду Python вызывать, контролировать или встраивать объекты Java так, будто он взаимодействует с собственными API, но эти вызовы делегируются Java API. Кроме того, для определенных этапов обработки, особенно при работе с UDF-функциями, Flink должен эффективно передавать структуры данных со стороны JVM на сторону Python и обратно. Для реализации этого в Apache Flink используются две библиотеки:
- Py4J – устанавливает шлюз в Java, который прослушивает сокет, и клиент Python, который может вызывать этот шлюз. Объекты Java предоставляются Python как прокси, а вызовы методов перенаправляются из Python в Java через этот сокет. И наоборот, Java может вызывать обратно в Python, если это необходимо. До Flink 1.14 это был единственный вариант выполнения UDF-функций Python, требующих межпроцессного взаимодействия.
- PemJa – более новая библиотека для встраивания CPython в процесс Java. В отличие от Py4J, она основана на интерфейсе внешних функций FFI (Foreign Function Interface), про который я подробно писала вчера. Он упрощает реализацию межпроцессных вызовов и повышает производительность по сравнению с Py4J. Код Python фактически запускается внутри процесса выполнения JVM, в том же процессе JVM, что и сам Flink. Это позволяет избежать дорогостоящего межпроцессного взаимодействия и накладных расходов на сериализацию данных.
Вспомнив, как Python-код PyFlink-приложения транслируется в Java для исполнения в JVM, далее рассмотрим, чем именно это полезно для потоковой обработки больших данных в Apache Flink.
Потоковый режим выполнения Flink-приложения
API Python в Apache Flink поддерживает различные режимы выполнения, которые определяют, как будут выполняться пользовательские функции Python. Это определяется в настройке python.execution–mode, где возможны два значения:
- PROCESS – процессный режим, где UDF-функции Python выполняются в отдельном процессе Python. Процесс оператора Java взаимодействует с рабочим процессом Python с помощью различных служб gRPC. Это режим по умолчанию.
- THREAD – потоковый режим, где пользовательские Python-функции выполняются в JVM, т.е. в том же процессе, что и операторы Java. Для встраивания Python в Java-приложение PyFlink использует библиотеку PEMJA.
Указать режим выполнения можно в API Table или DataStream заданий PyFlink, как конфигурацию среды, например:
# PROCESS mode
table_env.get_config().set("python.execution-mode", "process")
# THREAD mode
table_env.get_config().set("python.execution-mode", "thread")
До версии 1.15 в Apache Flink существовал единственный режим выполнения PROCESS, когда пользовательские функции Python выполнялись в отдельных процессах Python. В версии 1.15 был введен новый потоковый режим выполнения THREAD, где UDF-функции Python выполняются в JVM. Это сделано, чтобы снизить накладные расходы на сериализацию/десериализацию при межпроцессном взаимодействии Python и Java.
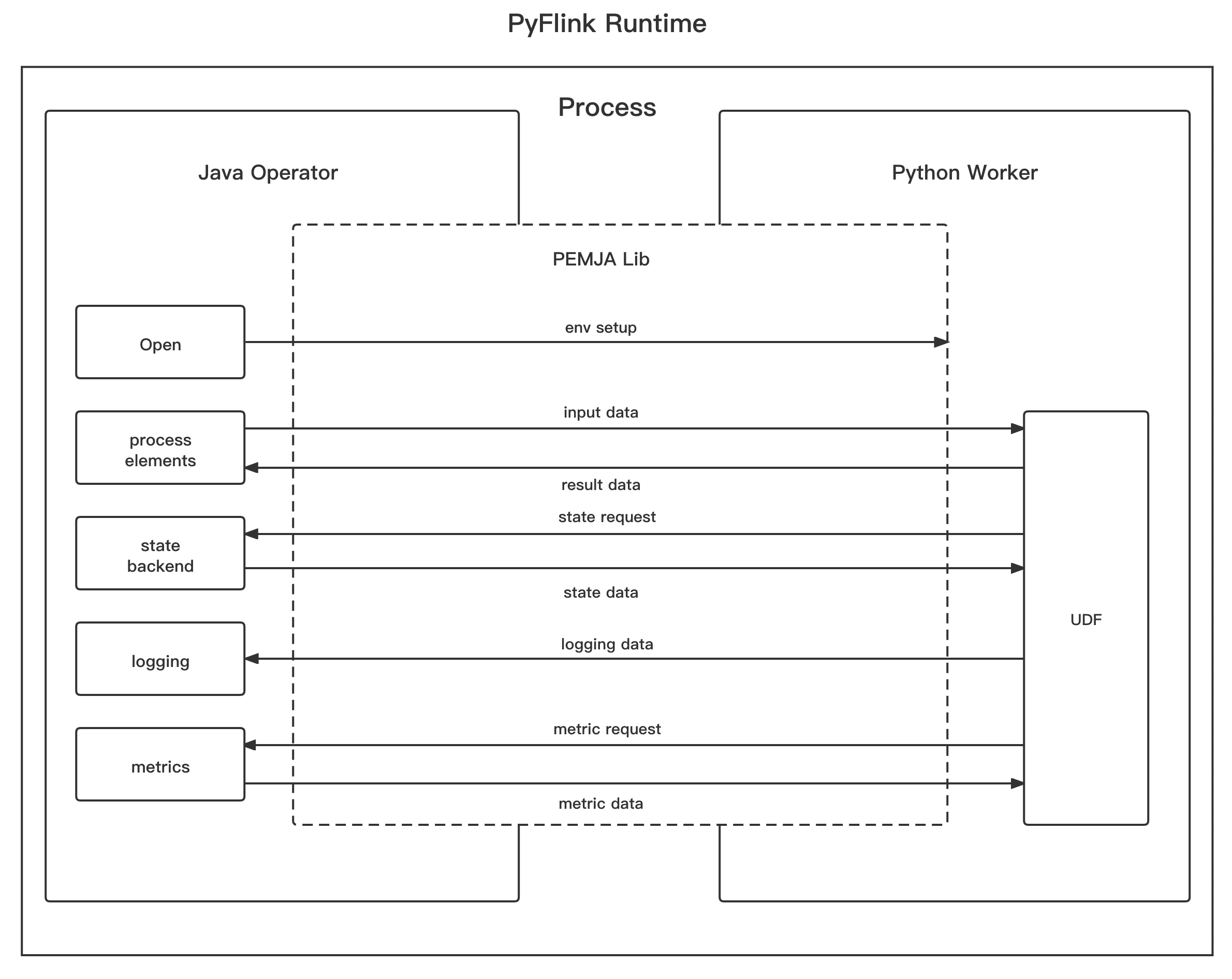
Основой потокового режима является ранее рассмотренная библиотека PEMJA. В потоковом режиме пользовательская функция Python выполняется в том же процессе, что и оператор Python, который выполняется в JVM. PEMJA используется как мост между кодом Java и кодом Python.
Поскольку UDF-функция Python выполняется в JVM, каждый результат от вышестоящих операторов передается UDF-функции Python напрямую, без пакетной буферизации. Таким образом, потоковый режим обеспечивает меньшую задержку по сравнению с процессным режимом, где надо настраивать параметры python.fn-execution.bundle.size или python.fn-execution.bundle.time на меньшее значение. Однако, из-за межпроцессного взаимодействия в режиме PROCESS, задержка все еще высока. В потоковой режиме такой проблемы не возникает.
Поскольку потоковый режим реализуется с помощью библиотеки PEMJA, он поддерживает только интерпретатор CPython. Он не поддерживает сеансовый режим, поэтому рекомендуется использовать потоковый режим только в развертываниях для отдельных заданий или приложений Flink. Это обусловлено тем, что потоковый режим не поддерживает использование разных интерпретаторов Python для заданий, запущенных в одном и том же TaskManager. Ограничение возникает из-за того, что многие библиотеки Python предполагают, что они будут инициализированы только один раз в процессе, поэтому они используют много статических переменных.
Хотя потоковый режим работает быстрее процессного благодаря снижению накладных расходов на сериализацию/десериализацию при межпроцессном взаимодействии Python и Java, PROCESS-режим обеспечивает лучшую изоляцию по сравнению с THREAD. Кроме того, Python DataStream API не полностью поддерживает выполнение пользовательских Python-функций в потоковом режиме. Поэтому режим выполнения PyFlink-задания может переключиться на PROCESS, даже если изначально был настроен на THREAD. Еще одним ограничением потокового режима является его поддержка только в Python 3.8+.
Научиться создавать высокопроизводительные приложения пакетной и потоковой аналитики больших данных и машинного обучения с помощью Apache Flink вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://nightlies.apache.org/flink/flink-docs-release-1.20/docs/dev/python/python_execution_mode/
- https://www.decodable.co/blog/a-hands-on-introduction-to-pyflink#running-your-first-pyflink-job
- https://www.alibabacloud.com/en/developer/a/flink/pyflink-generation-python-introduction?_p_lc=1
- https://flink.apache.org/2022/05/06/exploring-the-thread-mode-in-pyflink/

