Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов.
Масштабирование кластера
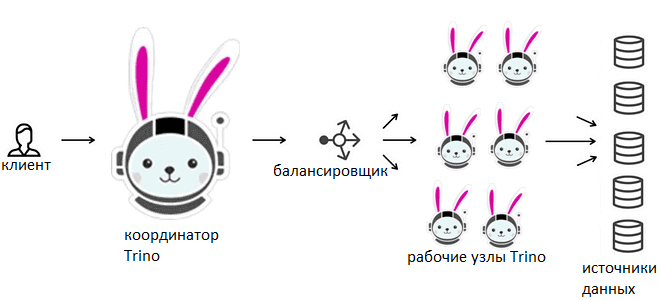
Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают за выполнение операций или хранение данных, а также балансировщиков, равномерно распределяющих нагрузку между узлами. Такой метод подходит и для Trino, где координатор управляет запросами, распределяет задачи между рабочими узлами и отслеживает состояние кластера. Фактические операции обработки данных выполняют рабочие узлы. Увеличив их количество, можно повысить вычислительную мощность кластера Trino и его способность обрабатывать большее количество запросов параллельно.
При динамических нагрузках целесообразно настроить автоматическое масштабирование, когда рабочие узлы добавляются или удаляются в зависимости от количества запросов. Например, в Amazon EMR автомасштабирование Trino зависит от загрузки ЦП рабочих узлов кластера. Алгоритм оценки проверяет часть рабочих узлов кластера на предмет превышения ими порогового значения загрузки ЦП, принимая решение по операциям масштабирования:
- кластер расширяется, если 80% узлов имела среднюю загрузку ЦП более 80% за последнюю минуту;
- кластер сокращается, если 80% узлов имела среднюю загрузку ЦП ниже 40% за последнюю минуту. При этом Amazon EMR ограничивает операции сжатия для недавно добавленных экземпляров. Если экземпляр добавляется в кластер, он не может быть завершен раньше, чем через 10 минут.
- количество рабочих узлов остается прежним, если загрузка их ЦП составляет от 40% до 80%.
Для отслеживания нагрузки выполняется непрерывный мониторинг метрик, предоставляемых каждым узлом в Trino REST API /v1/jmx/mbean. Этот вариант мониторинга предпочтительнее, чем встроенный JMX-коннектор Trino, поскольку длительные запросы или кластеры с большим количеством одновременных запросов могут задержать сбор метрик. Например, в AWS процесс мониторинга извлекает интересующие метрики каждые 15 секунд, чтобы иметь не менее 4 точек данных за одну минуту для оценки загрузки ЦП и принятия решения по масштабированию кластера.
Настройка групп ресурсов в кластере Trino
Чтобы эффективно утилизировать ресурсы кластера при выполнении запросов с учетом масштабирования, можно соответствующим образом настроить группы ресурсов. Группы ресурсов устанавливают ограничения на использование ресурсов и могут применять политики очередей для запросов, которые выполняются в них, или разделять свои ресурсы между подгруппами. Запрос принадлежит к одной группе ресурсов и потребляет ресурсы из этой группы и ее предков, кроме постановки новых запросов в очередь, когда группа ресурсов исчерпала свой ресурс и больше не может выполнять новые запросы. Группа ресурсов может иметь подгруппы или может принимать запросы, но не может делать и то, и другое. Группы ресурсов и связанные с ними правила выбора настраиваются подключаемым менеджером на основе JSON-файлов или баз данных MySQL, PostgreSQL и Oracle.
Правильная конфигурация групп ресурсов помогает избежать ситуаций, когда одни задачи монополизируют ресурсы, оставляя недостаточно для других. Также группы ресурсов позволяют изолировать различные типы задач (аналитические или поисковые запросы), обеспечивая изолированность рабочих нагрузок. Это способствует стабильности и предсказуемости при масштабировании Trino. Также с помощью групп ресурсов можно реализовать иерархическое управление ресурсами, создав подгруппы для разных отделов или проектов. Это тоже улучшает масштабируемость кластера.
Масштабирования операций на запись
Помимо масштабирования кластера на уровне добавления рабочих узлов, настройки и балансировки нагрузки между ними, в Trino есть механизм масштабирования операций записи. Хотя Trino, как распределённый SQL-движок для аналитических запросов, в основном ориентирован на чтение данных, он поддерживает и операции записи через различные коннекторы подключения к внешним источникам.
Масштабирование операций записи позволяет динамически масштабировать число таких задач, добавляя дополнительные, когда средний объем физических данных на запись превышает минимальный порог. Можно сказать, что масштабирование записи в Trino относится к способности системы эффективно управлять количеством параллельных процессов (Writer), которые отвечают за запись данных в хранилище, например, в Hive. Каждый Writer может создавать один или несколько файлов с данными. Уменьшение количества таких процессов, обеспечивающих запись данных в хранилище, приводит к росту размера записываемых файлов. Крупные файлы могут быть более эффективны для последующей обработки и уменьшения накладных расходов на метаданные. Однако, слишком большой размер создает трудности с управлением и доступом.
Увеличение количества записывающих процессов повышает параллелизм — способность системы выполнять несколько задач одновременно. Высокий параллелизм позволяет Trino быстрее обрабатывать и записывать данные, так как множество Writer-процессов работают одновременно над разными частями задачи. Чтобы управлять уровнем параллелизма и размером файлов, записываемых в хранилище, надо настроить следующие конфигурации Trino:
- scale-writers – по умолчанию true, что означает включение масштабирования процессов записи путем динамического увеличения количества задач записи в кластере;
- scale-writers.enabled – по умолчанию true, что означает включает масштабирование количества параллельных Writer-процессов в задаче. Максимальное количество Writer-процессов на задачу для масштабирования равно task.max-writer-count. Дополнительные Writer-процессы добавляются только тогда, когда средний объем несжатых данных, обработанных одним процессом, превышает минимальный порог writer-scaling-min-data-processed, и запрос становится узким местом при записи.
- writer-scaling-min-data-processed – минимальный объем несжатых данных, которые должен обработать Writer-процесс, прежде чем можно будет добавить еще один. По умолчанию этот параметр равен 100 MB.
Таким образом, масштабирование записи в Trino позволяет гибко управлять числом Writer-процессов для достижения оптимального баланса между размером создаваемых файлов и временем обработки запросов. Это особенно полезно при работе с системами хранения данных, такими как Hive, где эффективное управление ресурсами напрямую влияет на производительность и эффективность системы в целом. Помимо внутренней настройки операций записи, масштабирование кластера Trino предполагает определение порогов, при достижении которых следует добавлять или удалять новый рабочий узел в кластер, чтобы справиться с динамическими нагрузками. А если таких кластеров много, маршрутизировать нагрузку по ним поможет Trino Gateway, о котором мы поговорим в следующий раз.
Освоить работу с Trino вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

