 649
649 
Можно ли при разработке конвейера Apache Beam использовать преобразования из SDK разных языков программирования и как это сделать, избежав типичных ошибок.
Кросс-языковые преобразования и мультиязычные конвейеры Beam
Как и многие популярные фреймворки для создания распределенных приложений обработки данных (Apache Flink, Spark и другие движки), Apache Beam поддерживает несколько языков. В частности, эта собой унифицированная модель определения пакетных и потоковых конвейеров параллельной обработки данных имеет не только Java, Python и Go SDK, а также и декларативный YAML API, пример работы с которым я показывала здесь. При таком многообразии инструментов возникает вопрос: а как движок реализует мультиязычные конвейеры, когда в коде используется SDK нескольких языков? Например, коннектор Apache Kafka и преобразование SQL из Java SDK можно использовать в конвейерах, написанных на Python.
Для таких кросс-языковых преобразований Beam использует службу расширения , которая создает и внедряет в конвейер фрагменты, специфичные для конкретного языка. К примеру, конвейер Beam на Python запускает локальную службу расширения Java для работы с Apache Kafka, чтобы создать и внедрить Java-фрагменты кросс-языкового преобразования. Затем SDK загружает и размещает необходимые зависимости Java для выполнения этих преобразований. Во время выполнения Beam-движок (Runner) будет выполнять преобразования Python и Java для запуска конвейера.
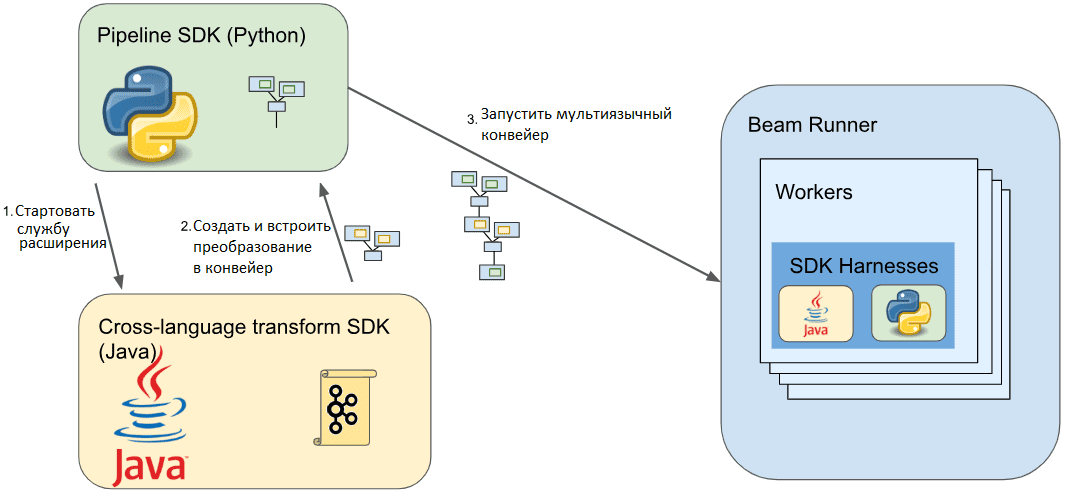
Однако, как уже было отмечено в прошлой статье, подобные кросс-языковые преобразования реализуются не так-то просто. Будучи написанным преимущественно на Java, Apache Beam позволяет использовать нативные преобразования этого языка из других SDK двумя способами:
- без разработки дополнительного кода на Java. Например, с версии Beam 2.34.0 пользователи Python SDK могут использовать некоторые преобразования Java без написания дополнительного кода Java. Пока эта функция доступна только при использовании преобразований Java из конвейера Python. Для такого непосредственного использования, API преобразования Java должен быть создан с помощью доступного открытого конструктора или открытого статического метода (метода-конструктора) в том же классе Java. Само преобразование Java может быть настроено с помощью одного или нескольких открытых методов-строителей, которые возвращают экземпляр преобразования Java. Чтобы использовать такой класс Java из конвейера Python SDK, надо разрешить к нему доступ, указав в YAML-файлах со списками разрешенных преобразований Java. После создания кросс-языковых преобразований необходимо зарегистрировать их в службе расширения, определив URN, включая идентификатор пространства имен, организацию, функциональность и номер версии преобразования.
- с помощью добавления классов Java. Если существующих Java-преобразований недостаточно, можно создать собственные Java-классы с необходимыми преобразованиями и интегрировать их в пайплайн на другом языке.
Последовательность создания, регистрации и использования пользовательского переносимого преобразования для мультиязычных конвейеров Apache Beam можно представить так.
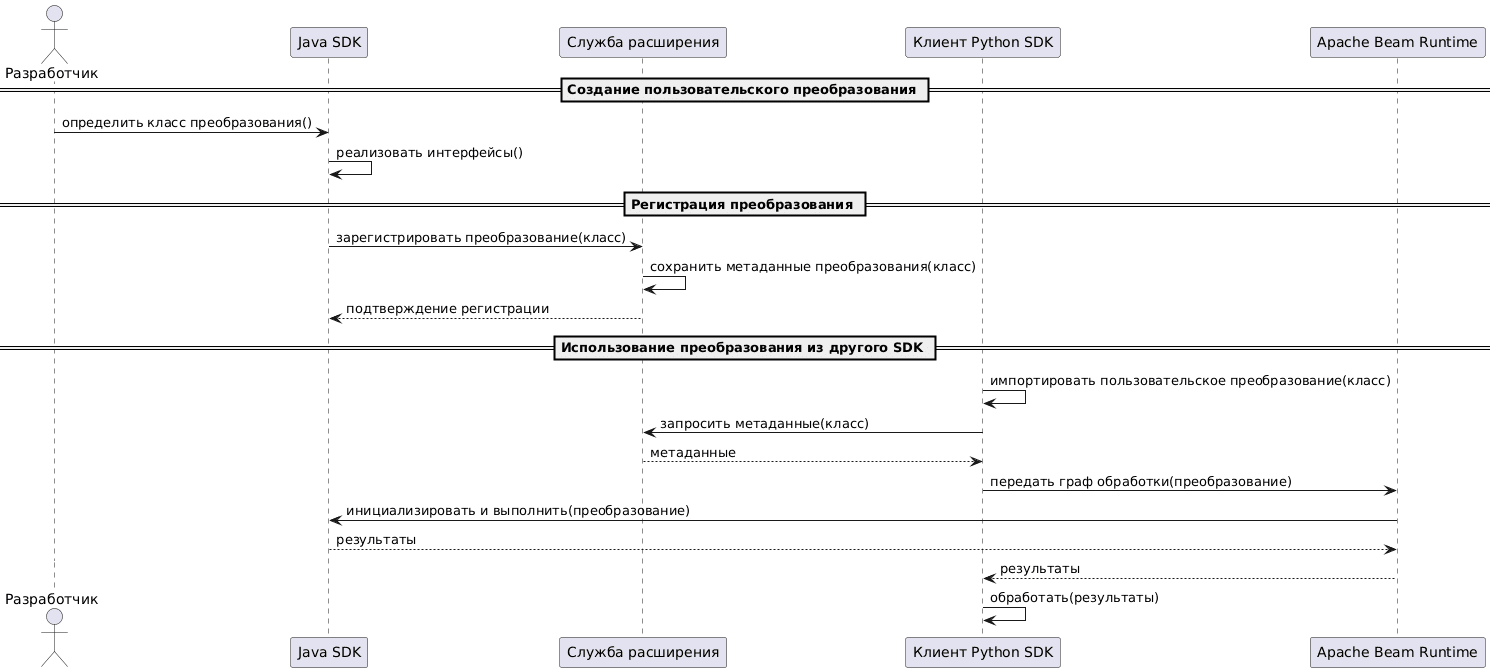
Пользовательское преобразование, т.е. пользовательский класс Java станет переносимым между другими языками, если будет реализовывать два интерфейса:
- ExternalTransformBuilder — создает кросс-языковое преобразование с использованием значений конфигурации, переданных из конвейера;
- ExternalTransformRegistrar – регистрирует кросс-языковое преобразование для использования со службой расширения.
Чтобы избежать ошибки службы расширения, связанной с отсутствием необходимого кодера Java, пользовательские преобразования для создания выходных типов PCollection должны использовать стандартные кодеры на границах SDK. Аналогичные меры надо принять, если запрос на расширение, отправленный из Python SDK в службу расширения Java, содержал Python-специфичный PickleCoder, который Java SDK не может интерпретировать. Избежать этого поможет аннотирование преобразований Python с помощью тега with_output_types и методов API PythonExternalTransform, таких как withOutputCoder() или withOutputCoders().
На самом высоком уровне абстракции некоторые популярные преобразования Python доступны через выделенные преобразования-оболочки Java. Например, в Java SDK есть классы DataframeTransform и RunInference, которые используют Python SDK. Когда преобразование-оболочка, специфичное для SDK, недоступно для целевого преобразования Python, можно использовать класс PythonExternalTransformRunInference более низкого уровня, указав полное имя преобразования Python. Если требуется попробовать внешние преобразования из SDK, отличных от Python, включая сам Java SDK, можно также использовать класс External самого низкого уровня.
Чтобы использовать кросс-языковое преобразование через оболочку SDK, следует импортировать модуль для оболочки SDK и вызвать его из своего конвейера. Движки запуска (Flink, Spark и Direct Runner) поддерживают мультиязыковые конвейеры. Для поддерживаемых движков можно задать уровень журнала преобразований Java таким же образом, как и для настройки переопределений уровня журнала модуля python, в частности, с помощью параметра конвейера —sdk_harness_log_level_overrides. Имена параметров python_underline_style будут автоматически переведены в Java-стиль smallCamel и распознаны Java SDK. Если движок не поддерживает автоматическое сопоставление опций, можно добавить соответствующую опцию конвейера как локальную опцию конвейера явно на стороне Python.
По умолчанию кросс-языковые преобразования Beam автоматически запускают службу расширения, которая включает внешние преобразования, версия которых соответствует версии конвейерного SDK. Если нужно использовать другую внешнюю версию SDK, можно запустить службу расширения, которая включает внешние преобразования из совместимой версии SDK или указать нужную службу расширения при определении кросс-языкового преобразования в конвейере.
Поскольку мультиязычные оболочки, реализованные в SDK конвейера, могут автоматически запустить службу расширения Java, наличие команды java в системе является обязательным предварительным условием. Для этого надо установив JDK на машину, с которой отправляется задание, и добавив каталог JDK с двоичным файлом java в переменную окружения PATH.
Если служба расширения, используемая конвейером, недоступна, при отправке задания возникнет ошибка grpc «failed to connect to all addresses». Чтобы ее устранить, надо запустить службу расширения вручную перед запуском задания.
Узнайте больше про Apache Beam на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

