
Сан-Франциско, 29 июля 2025 г. — Технологический мир замер в ожидании самого масштабного обновления в области искусственного интеллекта за последние годы. По данным авторитетных изданий, включая The Verge и Reuters, компания OpenAI готовится выпустить свою следующую флагманскую модель, GPT-5, уже в первой половине августа этого года. Инсайдерская информация и...

Поздравляем! Если вы читаете эти строки, значит, вы прошли полный путь от первого изучения ClickHouse до понимания его самых глубоких механизмов. За эти десять статей мы превратились из новичков, задающихся вопросом "Что такое колоночная СУБД?", в уверенных пользователей, способных не только писать сложные аналитические запросы, но и проектировать, оптимизировать и...
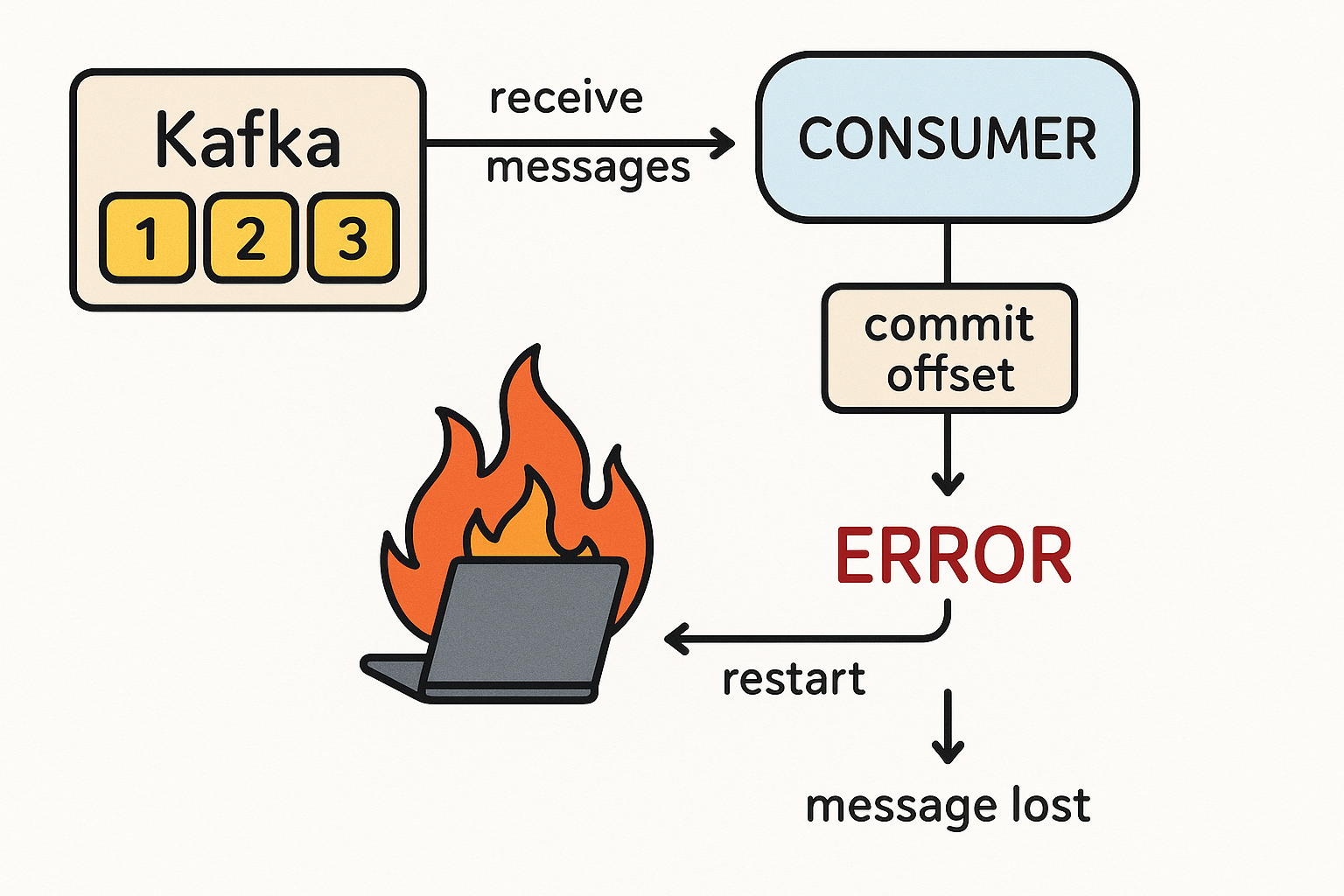
В мире распределенных систем, гарантии доставки сообщений, при передаче данных между сервисами — это фундаментальная задача. Но что происходит, когда мы отправляем сообщение из точки А в точку Б через сеть, которая по своей природе ненадежна? Сетевые задержки, сбои серверов, перезапуски приложений — все это может привести к потере или...

Мы с вами научились виртуозно писать запросы, строить сложные аналитические отчеты и интегрировать ClickHouse с другими системами. Но чтобы вся эта мощь работала стабильно и предсказуемо в production, кластер требует внимания и ухода. Написание запросов — это работа аналитика или разработчика, а поддержание здоровья системы — это задача администратора баз...
Оконные функции ClickHouse и работа с массивами данных. Мы с вами уже прошли большой путь: научились эффективно хранить данные, оптимизировать таблицы, выполнять базовые и сложные запросы и даже интегрироваться с внешними системами. Казалось бы, мы можем практически всё. Но как ответить на такие вопросы: "Каково время между последовательными действиями каждого...
До сих пор мы рассматривали ClickHouse как самостоятельную систему: создавали в нем таблицы и загружали данные. Однако в реальном мире данные редко живут в одном месте. Транзакционная информация находится в реляционных базах вроде MySQL или PostgreSQL, архивы логов — в объектных хранилищах типа Amazon S3, а потоки событий в реальном...
Итак, вы освоили типы данных, создали таблицы на правильных движках MergeTreeи даже научились писать сложные запросы. Кажется, что вы готовы к работе с реальными данными. Однако на больших объемах вы можете столкнуться с ситуацией, когда даже на мощном "железе" запрос выполняется не так быстро, как хотелось бы. В чем же...
В предыдущих статьях мы узнали, что семейство движков MergeTree — это основа для хранения аналитических данных в ClickHouse. Мы создавали таблицы с помощью базового MergeTree и даже упоминали о его специализированных версиях. Теперь пришло время для глубокого погружения. Эти движки — не просто вариации, а мощные инструменты, которые выполняют часть...
Добро пожаловать в четвертую статью нашего курса по ClickHouse! В прошлый раз мы научились основам: вставлять, выбирать и агрегировать данные. Теперь, когда вы можете получать базовую статистику, пришло время углубить свои навыки и научиться "разговаривать" с данными на более сложном языке. Сегодня мы изучим мощные инструменты, которые позволят вам преобразовывать,...
Приветствуем вас в третьей части нашего гида по ClickHouse! В предыдущих статьях мы заложили прочный фундамент: разобрались, что такое ClickHouse (далее CH), почему он так хорош для аналитики, а также глубоко погрузились в типы данных и движки таблиц, научившись создавать оптимизированные таблицы. Теперь пришло время перейти от теории к самой...

В начале своего пути Apache Hadoop был настоящей революцией. Он предложил решение для обработки данных таких объемов, которые ранее считались невозможными, используя кластеры из обычного оборудования. Философия "перемещай вычисления к данным, а не данные к вычислениям" легла в основу мира Big Data. Но технологии не стоят на месте. Облачные платформы,...
Приветствуем вас во второй части нашего курса по основам ClickHouse (далее CH)! В первой статье мы разобрались, что такое ClickHouse, почему он так хорош для аналитики и как запустить его локально или в облаке. Теперь пришло время углубиться в две ключевые концепции, которые определяют, как CH хранит и обрабатывает ваши...
Данной статьей мы начинаем Бесплатный курс по "Основам ClickHouse для аналитиков и дата инженеров", который будет состоять из 10 уроков с практическими занятиями код которых будет доступен для скачивания на нашем GitHub аккаунте. Если ваша работа связана с данными, вы наверняка слышали название ClickHouse. Это не просто очередная база данных,...

Как Flink SQL позволяет обогащать потоковые данные информацией из внешних систем и статических таблиц, зачем в релизе 2.0 улучшили Lookup Join и каким образом работает эта оптимизация. Как работает потоковое обогащение в Apache Flink Для взаимодействия с внешними системами (источниками и приемниками данных) Apache Flink использует коннекторы. Source-коннекторы обеспечивают чтение...

Зачем в Apache AirFlow 3.0 добавлена поддержка Go и как работает этот экспериментальный SDK: возможности и ограничения разработки и запуска задач на компилируемом языке программирования. Мультиязычность в Apache AirFlow 3.0 Одной из ключевых новинок недавно выпущенного Apache AirFlow 3.0, о котором мы писали здесь, стала его мультиязычность. Теперь фреймворк поддерживает...

Как оптимизировать многопоточную обработку в ClickHouse и эффективно распределить ресурсы ЦП между разными пользователями и запросами, спланировав рабочую нагрузку. Настройка многопоточной обработки в Clickhouse Чтобы эффективно утилизировать ресурсы для аналитической обработки огромных объемов данных, в ClickHouse можно спланировать рабочую нагрузку, определив приоритеты использования памяти, диска и ЦП для разных видов...
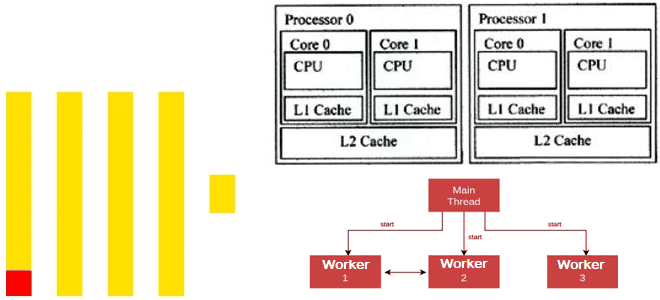
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....

Чем похожи Apache Beam и Apache Wayang, чем они отличаются, что и когда выбирать для практического использования в аналитике и обработке больших данных: сравнительная таблица по 10 критериям. Сходства и отличия Apache Wayang и Apache Beam Недавно я писала про сходство и различие Apache Wayang и Trino, где упоминала, что...
Как эффективно распределять ресурсы ClickHouse между разными пользователями и запросами, настроив политику планирования рабочих нагрузок: примеры и рекомендации. Иерархия планирования рабочей нагрузки в Clickhouse Когда ClickHouse выполняет несколько запросов одновременно, они могут использовать общие ресурсы, например, диски, ЦП и память. Чтобы эффективно распределять ресурсы ClickHouse между разными пользователями и нагрузками,...

Почему провайдерам Kafka как сервиса недостаточно многоуровневого хранилища (KIP-405) и зачем они предложили новое улучшение KIP-1150, меняющее архитектуру хранения и репликации данных напрямую в объектные системы. Кому и зачем понадобилась бездисковая Kafka: что не так с KIP-405 Одной из наиболее интересных тем вокруг Apache Kafka в апреле 2025 года стало...