 963
963 
Содержание
Как связать ClickHouse с Apache Kafka: примеры проектирования и реализации онлайн-аналитики с использованием облачного сервиса колоночной СУБД, брокера сообщений и BI-системы Яндекса.
Постановка задачи и проектирование потокового конвейера
Для взаимодействия с внешними хранилищами ClickHouse использует специальные механизмы – интеграционные движки таблиц. Вчера я показывала пример интеграции ClickHouse со встроенной key-value БД RocksDB. Сегодня рассмотрим такой конвейер:
- Python-продюсер отправляет данные в Kafka;
- данные из Kafka попадают в ClickHouse благодаря использованию интеграционного движка;
- сводная аналитическая информация отображается на дэшборде BI-сервиса Yandex.Datalens.
В общем случае для взаимодействия ClickHouse с Apache Kafka используется одноименный интеграционный движок. Он позволяет публиковать на потоки данных в топики и подписываться на них, а также обрабатывать их по мере появления. Чтобы прочитать данные из таблицы, созданной с движком Kafka, их надо сперва опубликовать, а затем ClickHouse будет их потреблять. Сама по себе таблица ClickHouse с движком Kafka является только интерфейсом для чтения данных из топика, она не хранит данные внутри ClickHouse. Движок Kafka ожидает, что данные будут приходить из самой Kafka, а не из запроса INSERT в ClickHouse.
Для примера потоковой публикации данных я написала следующий небольшой Python-скрипт генерации клиентских заявок на покупку товаров в интернет-магазине или пользовательских вопросов и запустила его в Google Colab:
#установка библиотек
!pip install kafka-python
!pip install faker
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
# Импорт модуля faker
from faker import Faker
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
#batch_size=300
)
topic='test'
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker()
#списки полей в заявке
products = ['яблоки желтые', 'малина', 'вода', 'хлеб белый','хлеб серый', 'креветки', 'форель', 'апельсины', 'кета','курица','яйцо перепелиное','яйцо куриное','лаваш',
'булка сдобная','булка сахарная','помидоры бакинские','помидоры чери','огурцы','перец сладкий','перец острый','перец болгарский','мандарины','укроп свежий',
'укроп сушеный','клубника свежая','клубника мороженная','мороженое','картошка','морковь', 'свекла','пангасиус','семга','кальмар замороженный','горошек зеленый',
'смородина черная','смородина красная','соль поваренная пищевая йодированная','чай черный байховый','чай зеленый','чай красный','кофе','кофе с молоком','какао',
'молоко','кефир','сыр с плесенью','сыр плавленый','сыр твердый','сыр мягкий','яблоки красные','яблоки зеленые','яблоки сушеные','икра красная',
'икра черная','икра заморская баклажанная','масло сливочное','масло оливковое','масло подсолнечное','масло кокосовое','орех грецкий','орех бразильский',
'лист лавровый','куркума','кукуруза','печенье сладкое','пряники сдобные','тесто слоеное','варенц','ряженка','снежок','шоколад молочный']
questions = ['payment', 'delivery', 'discount', 'vip', 'staff']
#бесконечный цикл публикации данных
while True:
#подготовка данных для публикации в JSON-формате
now=datetime.now()
id=now.strftime("%Y-%m-%d %H:%M:%S")
content = ''
theme = ''
corp = 0
#подготовка списка возможных ключей маршрутизации (routing keys)
corp = random.choice([1,0])
if corp==1 :
name=fake.company()
else:
name=fake.name()
#случайный выбор одного из ключей маршрутизации (из routing keys)
subject=random.choice(['app', 'question'])
# Добавление дополнительных данных для заголовка и тела сообщения в зависимости от темы заявки
if subject == 'question':
theme = random.choice(questions)
content = 'Hello, I have a question about ' + theme
else:
theme = 'app'
kol = random.randint(1, 10) # Число позиций в заказе
items = [] # Инициализация списка для элементов заказа
for i in range(kol):
items.append({'name': random.choice(products), 'quantity': str(random.randint(1, 100))})
content = items
# Создаем полезную нагрузку в JSON
data = {"id": id, "name": name, "subject": subject, "content": content}
#публикуем данные в Kafka
future = producer.send(topic, value=data)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
print(f' [x] Payload {data}')
#повтор через 3 секунды
time.sleep(3)
Далее посмотрим, как анализировать данные, сгенерированные этим продюсером.
Настройка интеграции ClickHouse с Kafka
Свой экземпляр ClickHouse я развернула в облачной платформе, которая изначально поддерживает ряд коннекторов для интеграции с внешними источниками данных. Одним из них является Kafka.
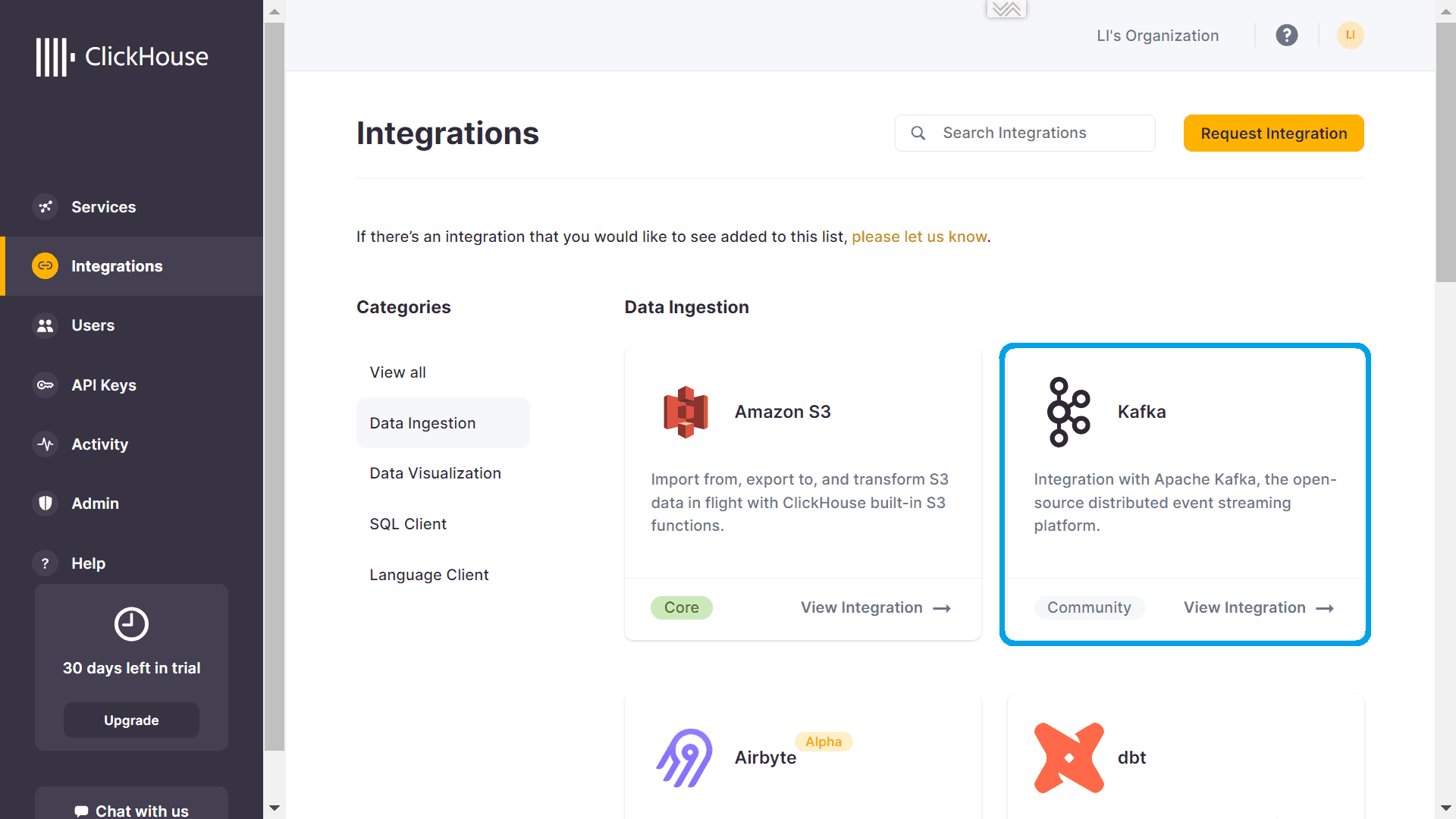
Чтобы загрузить сообщения из Kafka, необходимо вызвать команду добавления данных.
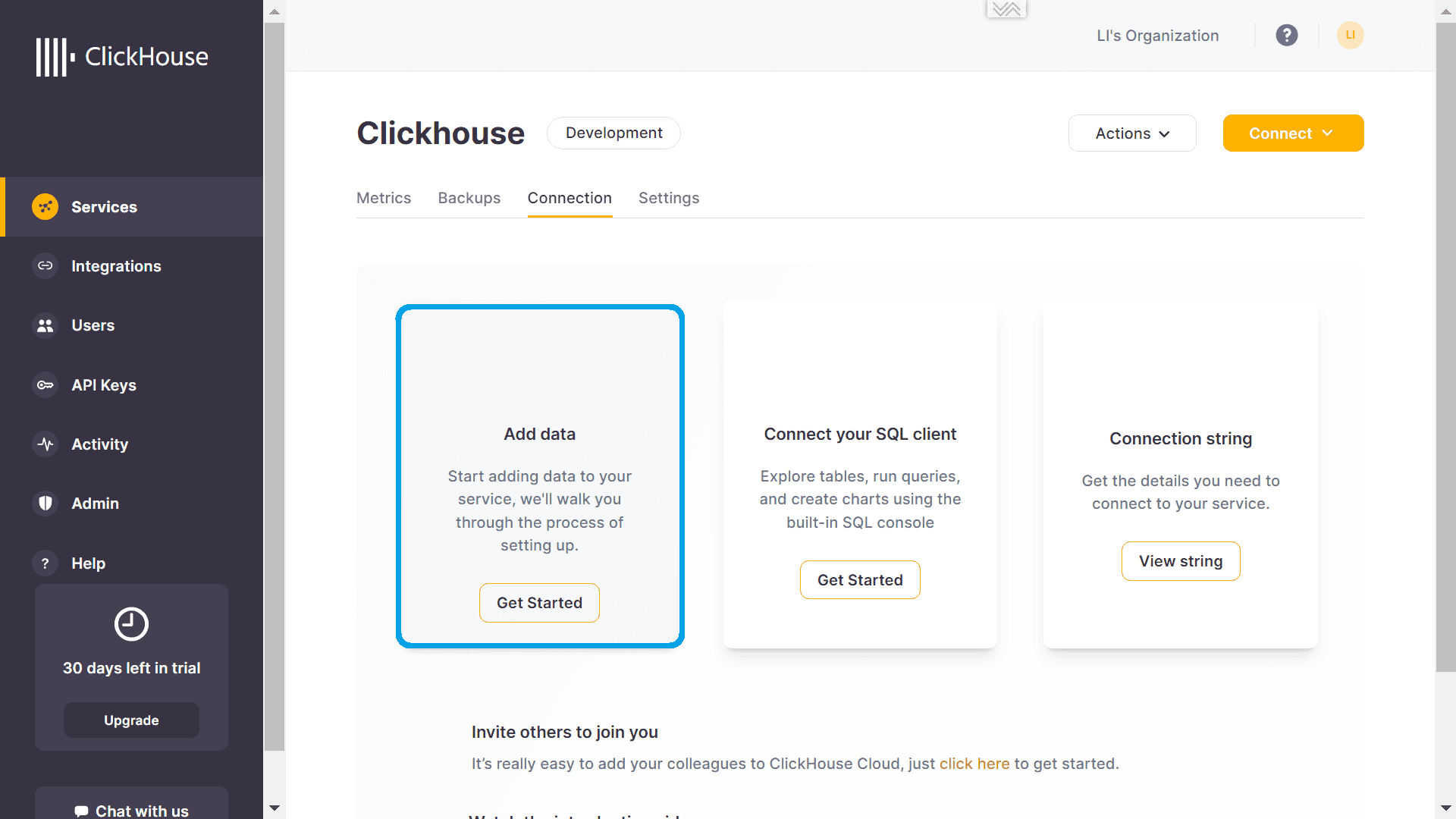
При этом в качестве источника данных будет использоваться движок коннекторов ClickPipe.
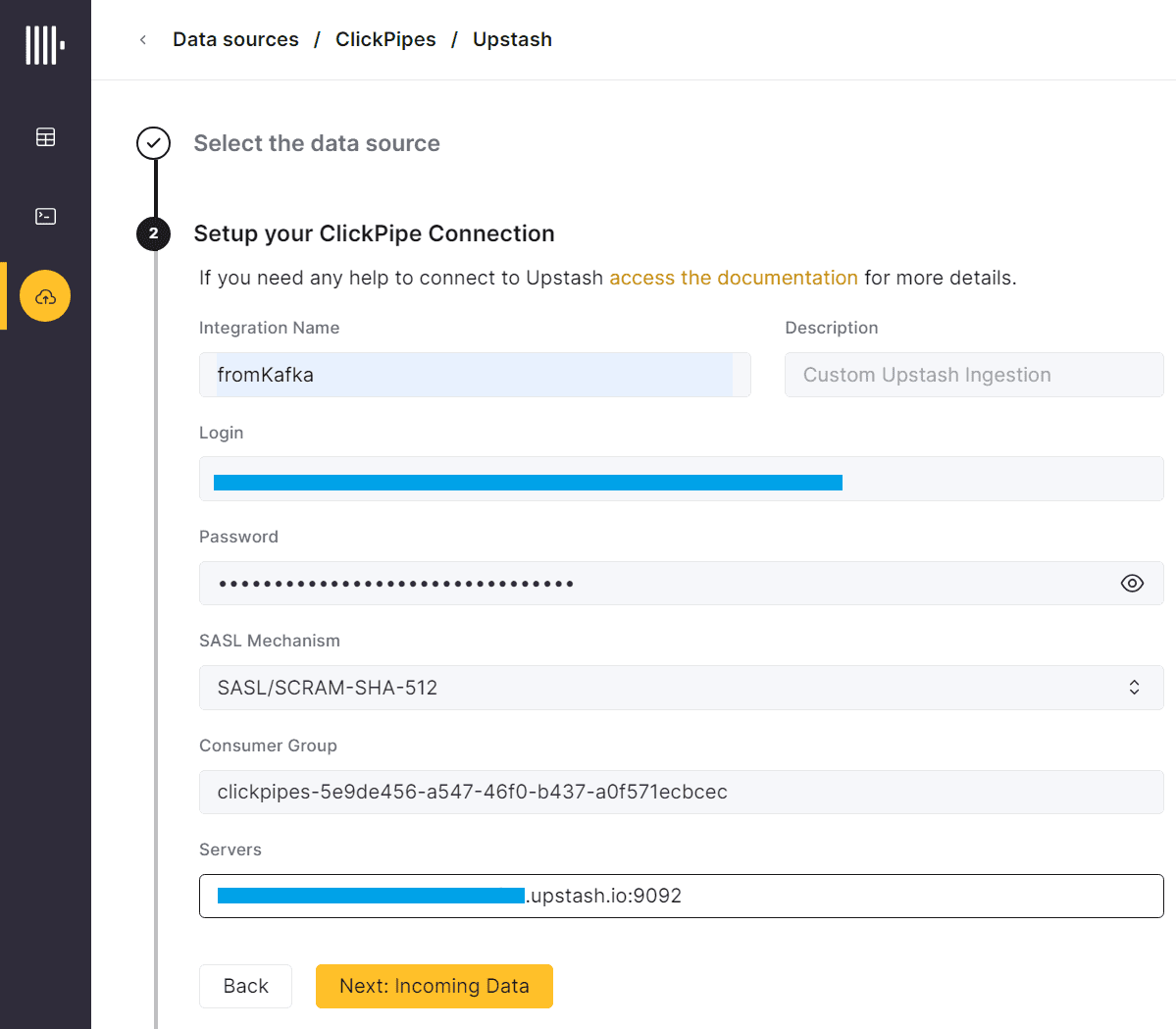
Поскольку мой экземпляр Kafka развернут в облачном сервисе Upstash, выбираю именно этот источник данных.

Затем нужно настроить учетные данные для подключения к Kafka из Clickhouse.
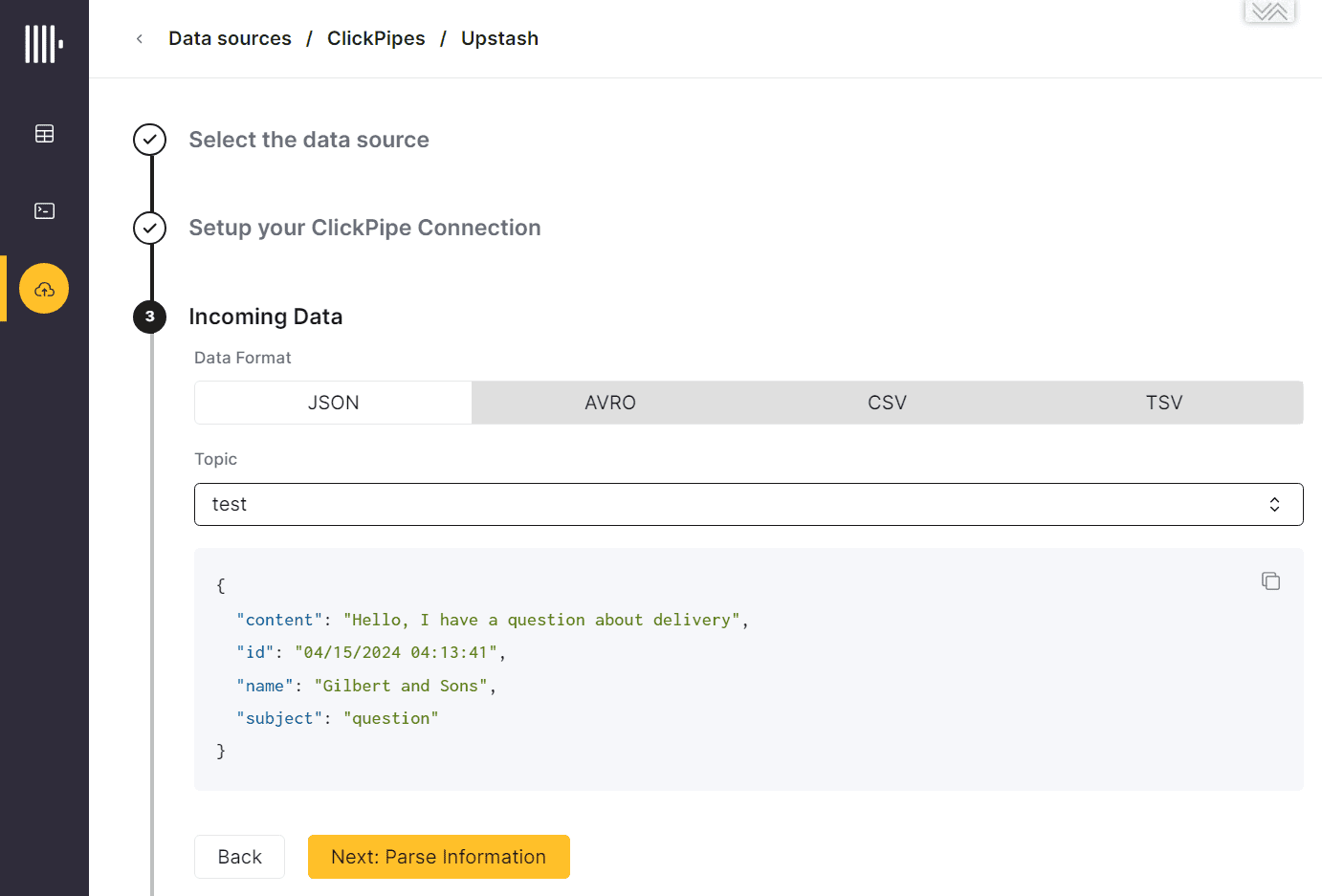
После успешной попытки подключения интеграционный движок Clickhouse выполняет синтаксический разбор (парсинг) полученной структуры данных полезной нагрузки сообщения.
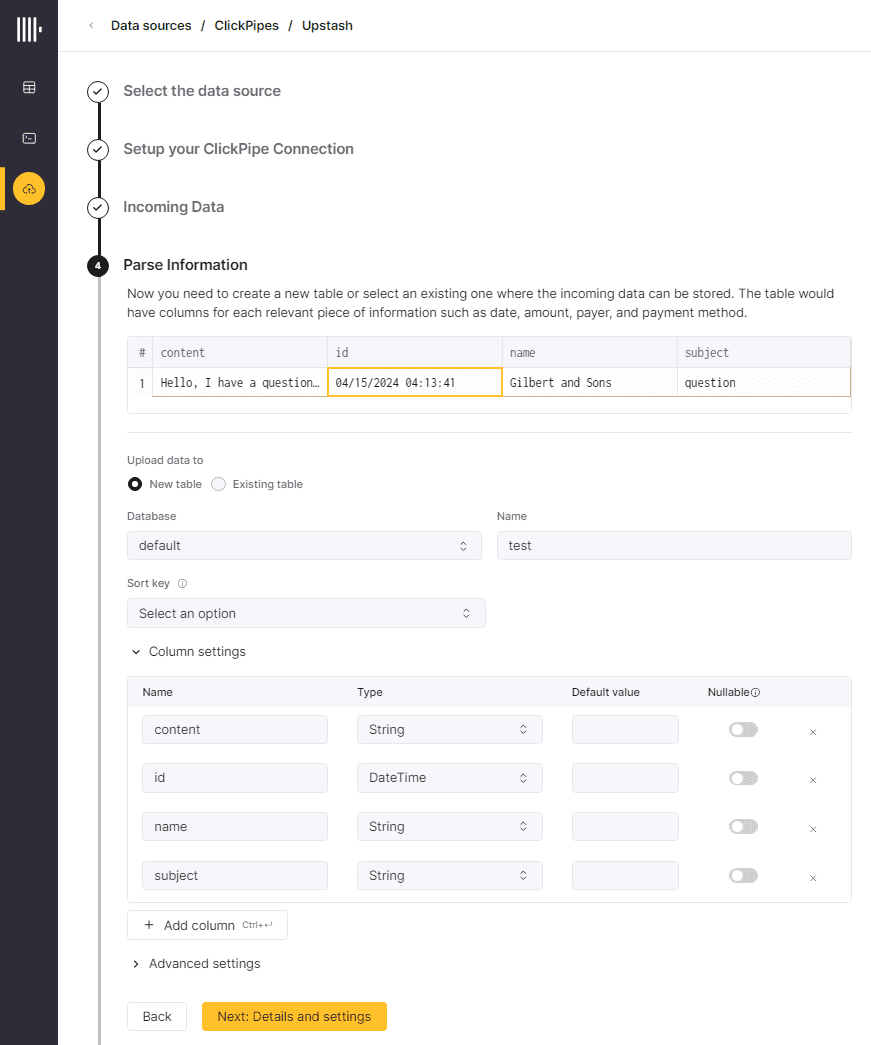
Можно согласиться с предложенными вариантами типов данных в полях JSON-сообщений или исправить их. В моем случае я лишь исправила тип данных DateTime64 на просто DateTime, поскольку в исходном коде продюсера не передаются миллисекунды и таймзона для поля id.
Наконец, нужно выбрать уровень доступа для настроенного коннектора.
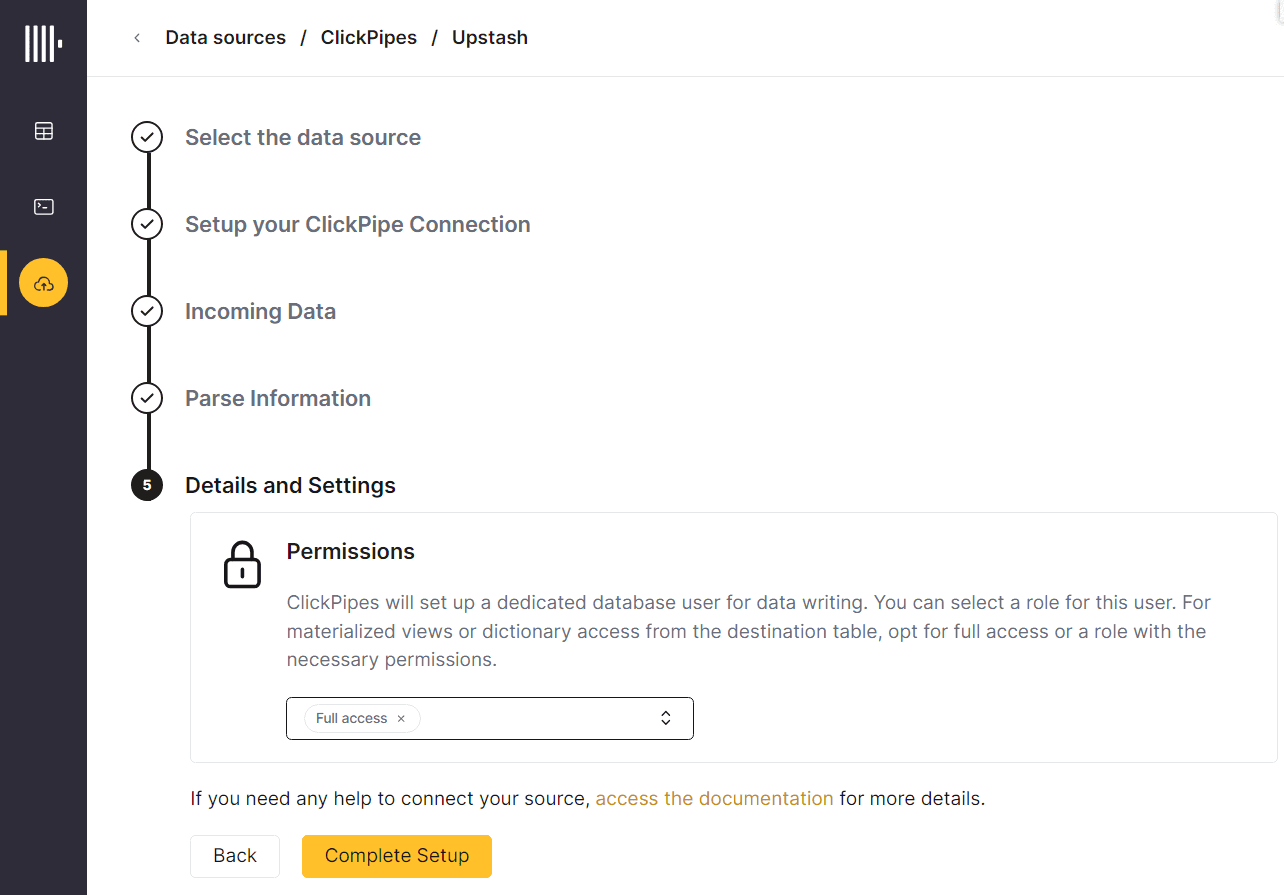
Созданный коннектор появится в списке настроенных интеграций Clickhouse с внешними системами.
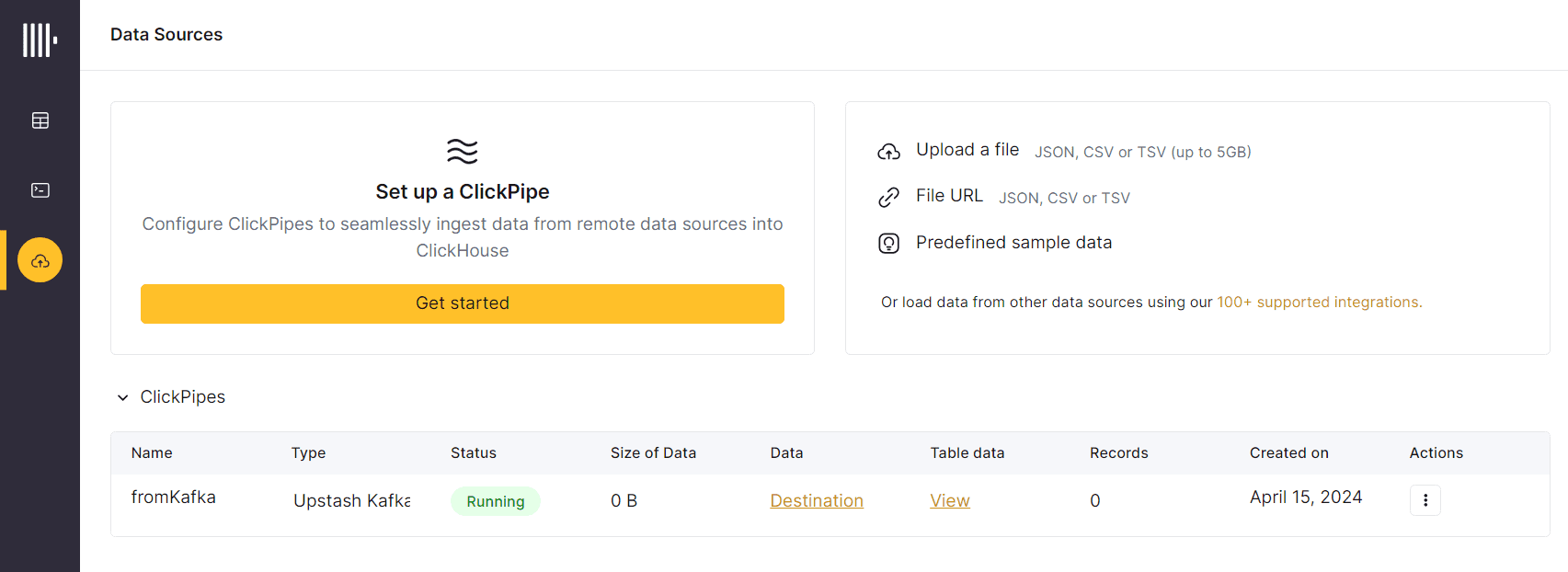
Сообщения из Kafka отобразятся в таблице Clickhouse, которая называется аналогично названию топика, откуда потребляются данные.
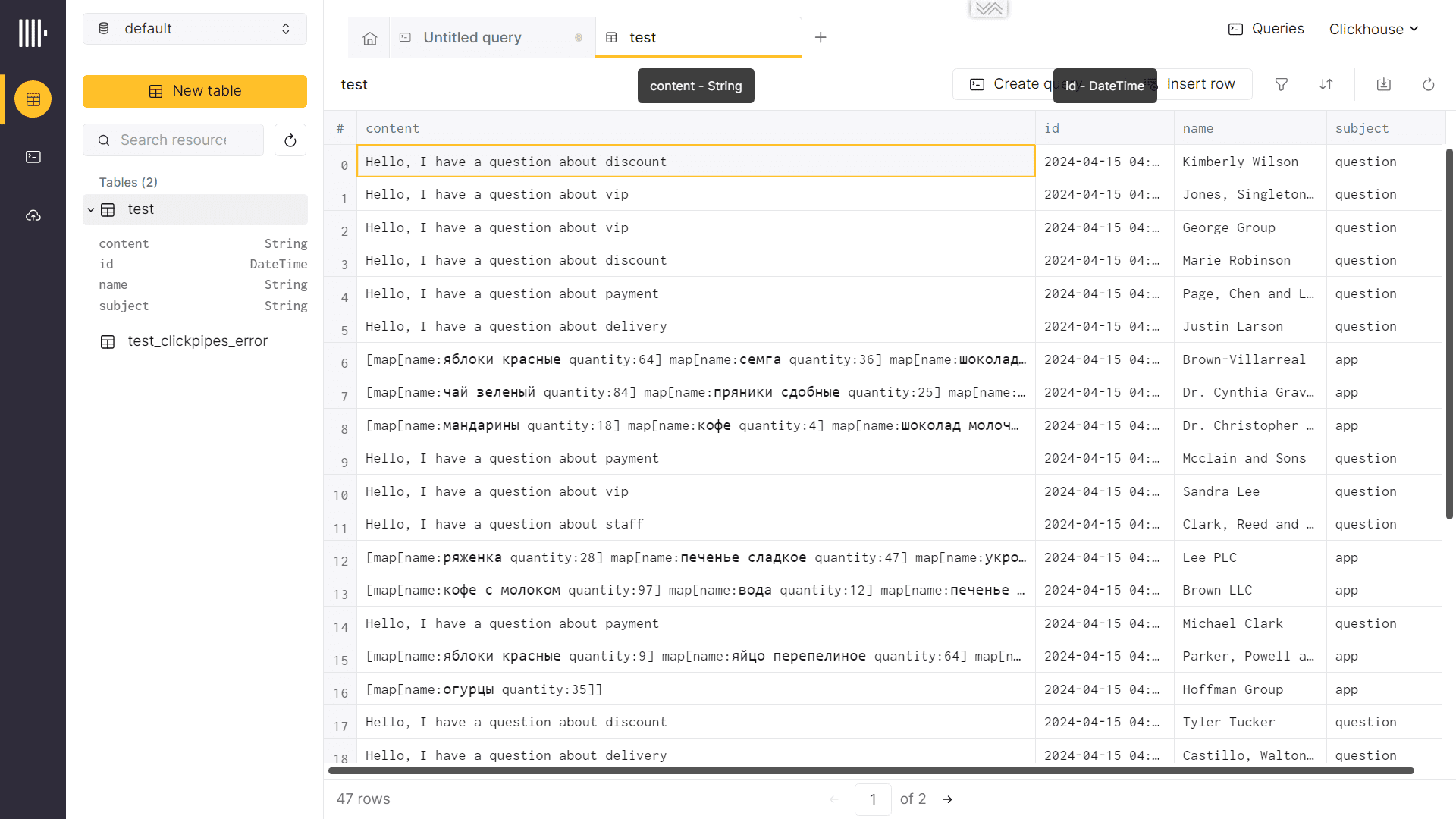
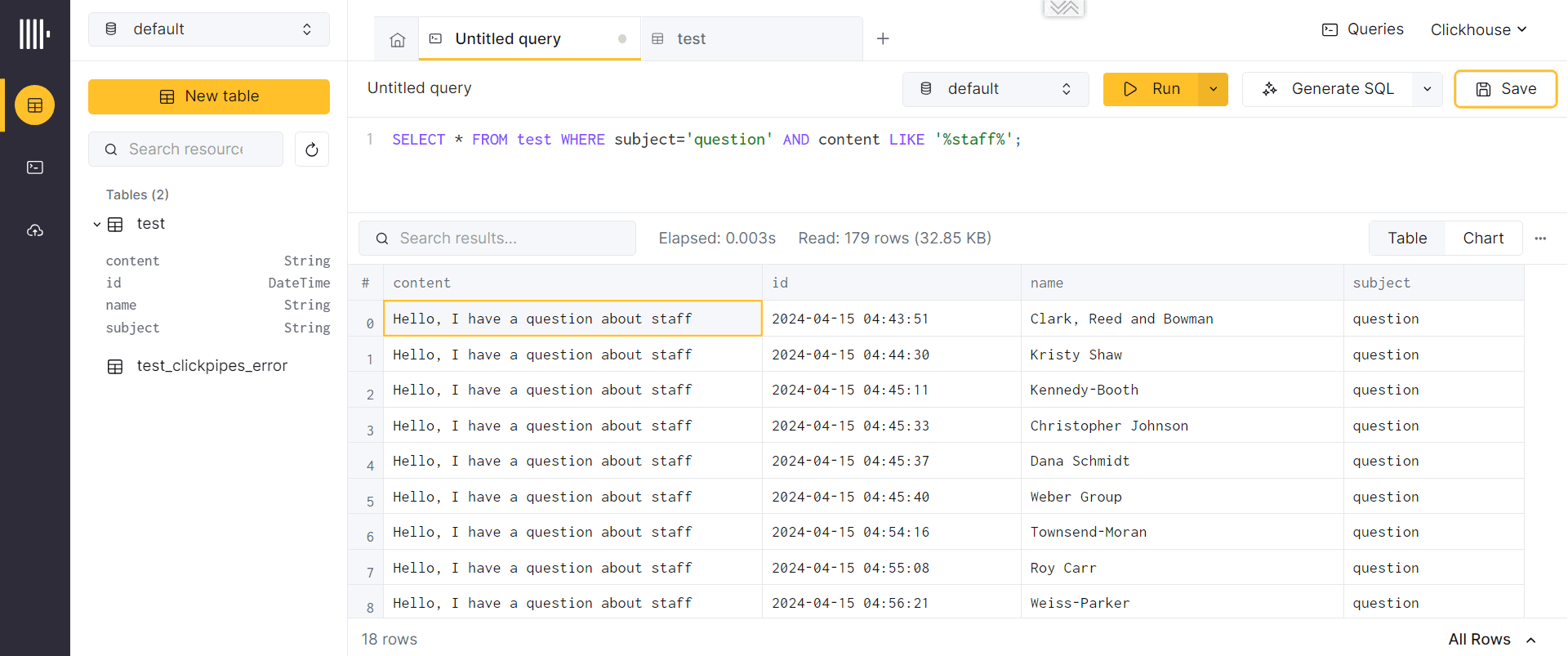
К этим данным можно на лету выполнять SQL-запросы, в т.ч. агрегатные, чтобы получить аналитику по опубликованным данным. Например, я решила посмотреть список всех заявок с вопросами по работе персонала, составив SQL-запрос
SELECT * FROM test WHERE subject='question' AND content LIKE '%staff%';
В GUI-платформы с Kafka публикация и потребление данных тоже отображаются.
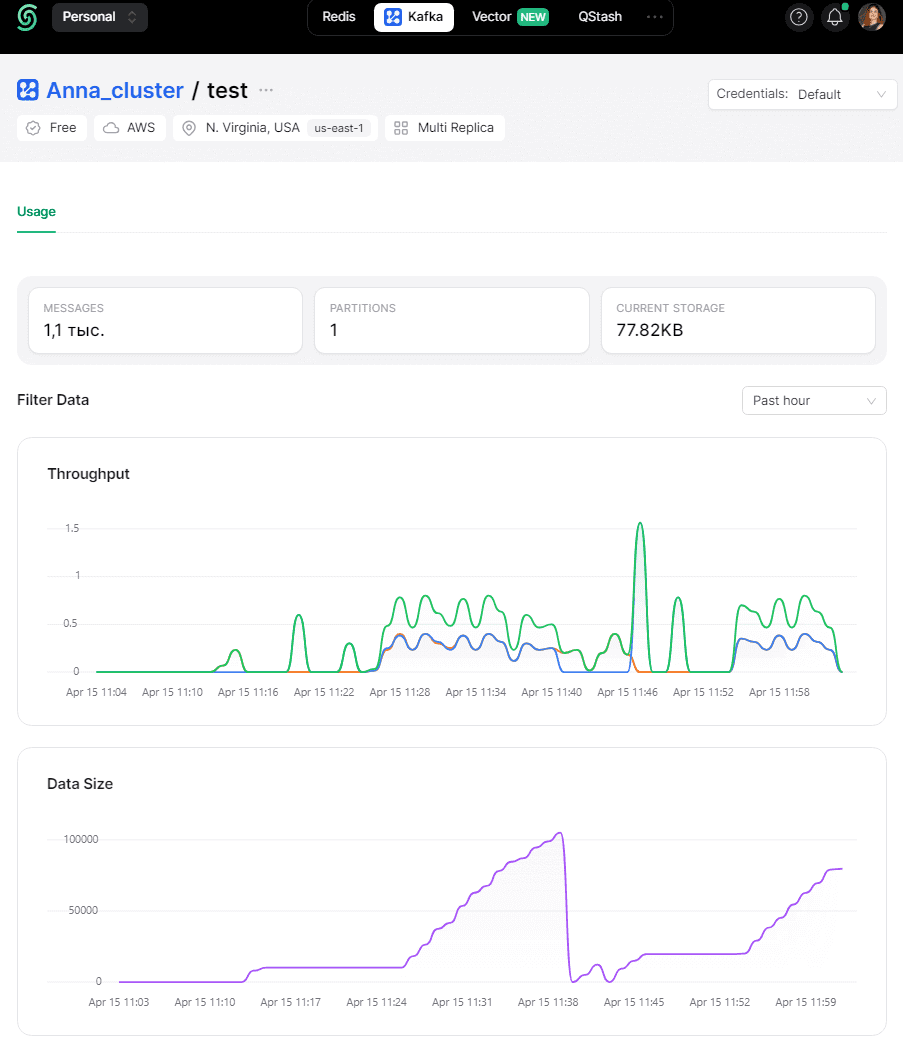
Далее перейдем к последней части спроектированного конвейера, реализовав дэшборд в сервисе BI-аналитики Даталенс.
Потоковая аналитика больших данных с Yandex.DataLens
Даталенс изначально поддерживает интеграцию с Clickhouse, позволяя выбрать эту базу данных в списке подключений.

Выбрав источник данных, надо задать параметры подключения к нему.
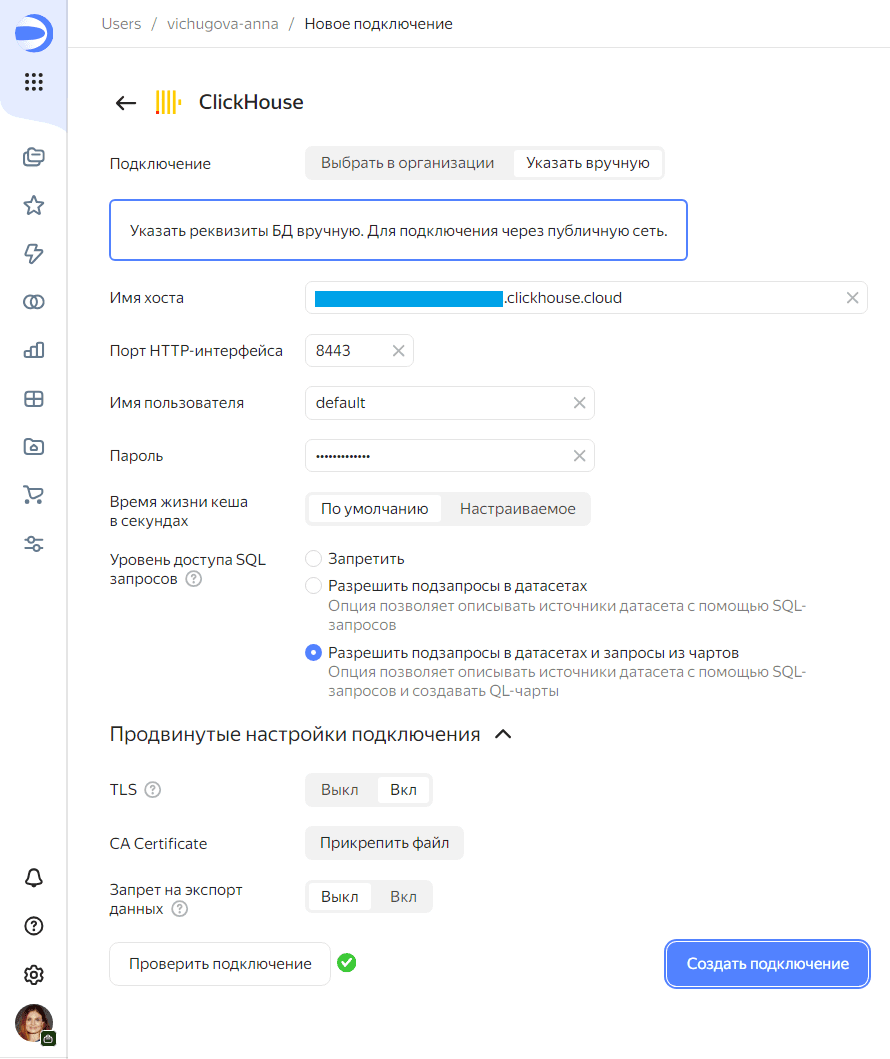
После успешного подключения следует отметить ту таблицу, которая нужна для аналитики в Даталенс. В моем случае это будет таблица с данными полезной нагрузки, а не сведения об ошибках интеграции ClickHouse с Kafka.
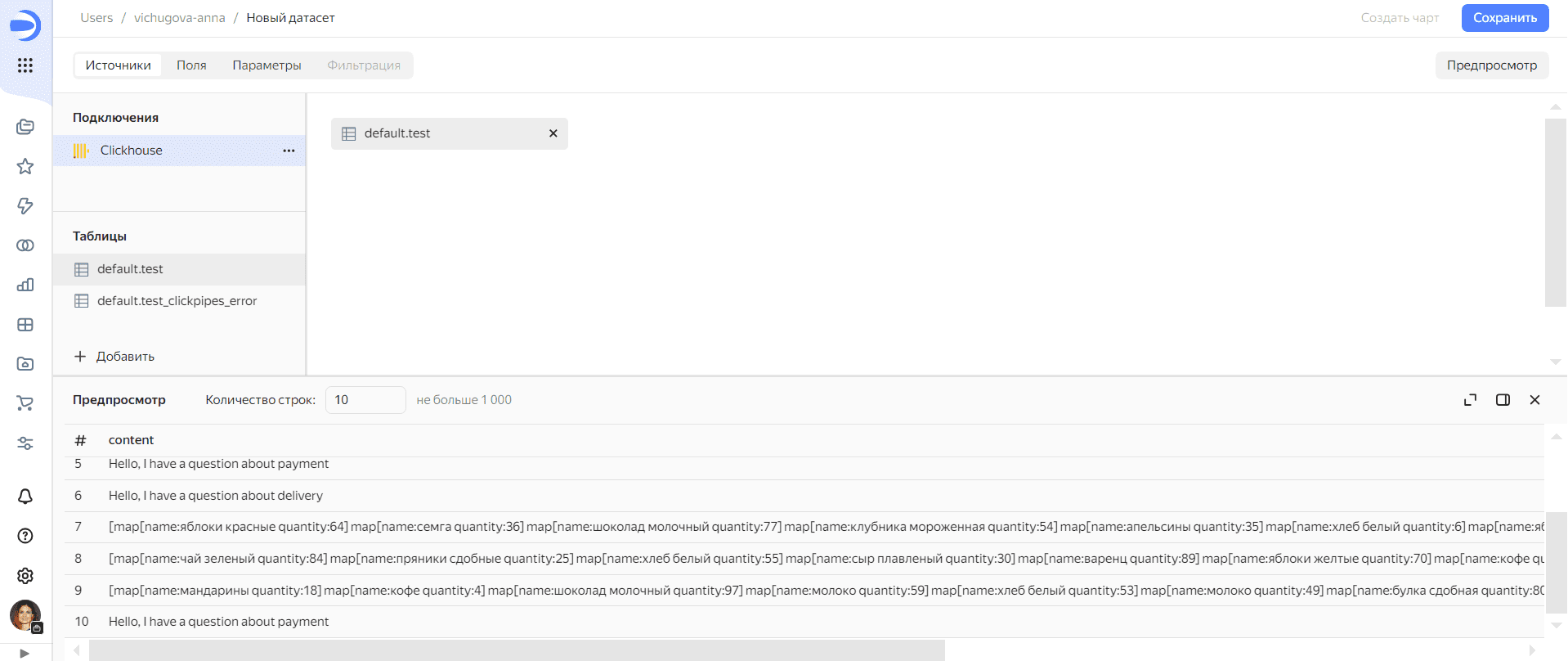
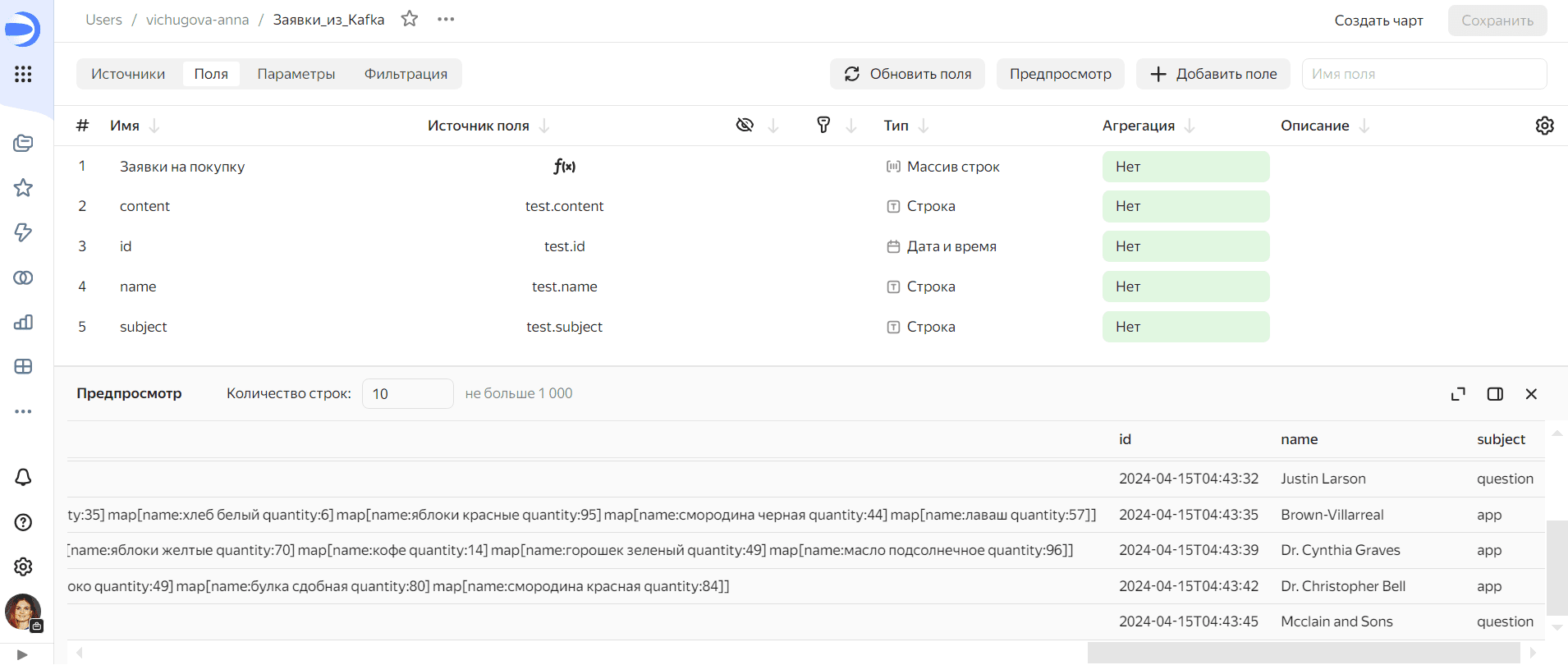
Загрузив исходный датасет, его можно модифицировать, добавив новые столбцы или изменив существующие. В частности, я добавила поле с заявками на покупку товаров, которое вычисляется в Datalens по следующей формуле:
ARRAY(IF [subject]='app' THEN REPLACE([content], 'map', '') ELSE NULL END)
После создания визуализаций (чартов в терминологии Даталенс) я сделала интерактивный дэшборд по количеству заявок, поступающих каждую минуту. Он доступен по адресу https://datalens.yandex/v6rdfqtq9wpyj
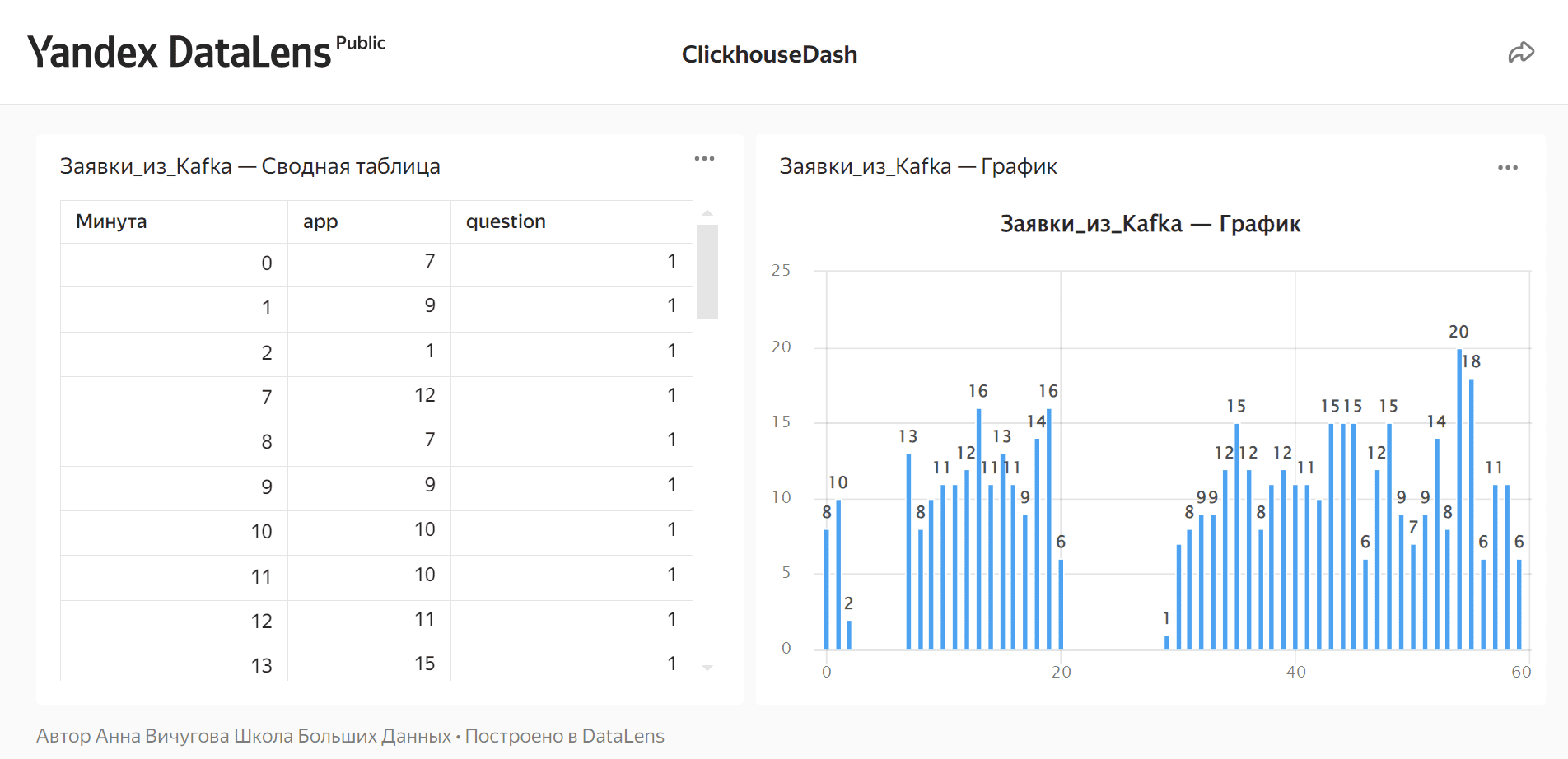
При публикации новых данных они будут автоматически добавляться в ClickHouse и отображаться на дэшборде с обновлением раз в 30 секунд.
Освойте администрирование и эксплуатацию ClickHouse для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Построение хранилища данных на базе Clickhouse
- Apache Kafka для инженеров данных
- Практическое применение Big Data аналитики для решения бизнес-задач
Источники

