Как Apache Kafka реализует компромиссы CAP-теоремы и при чем здесь чистые выборы лидера: проблемы целостности, доступности и устойчивости в распределенной системе с репликацией данных.
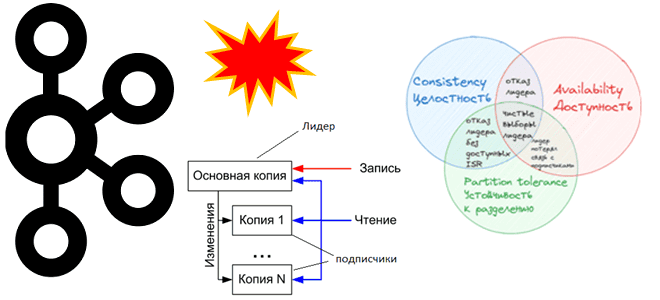
CAP-теорема в кластере Apache Kafka
При публикации сообщений в Apache Kafka, развернутой в кластере из нескольких узлов, данные сохраняются в брокере-лидере раздела, а затем реплицируются по брокерам-подписчикам согласно заданному значению фактора репликации. В большинстве случаев публикация выполняется успешно, но иногда может возникнуть ошибка, что лидер раздела недоступен. Это означает, что брокер-лидер вышел из строя, а новый еще не переназначен. Обычно Kafka автоматически переназначает лидера раздела, выполняя процедуру leader election на основе набора синхронизированных реплик (ISR, In-Sync Replicas). Можно также назначить лидера вручную, используя команду kafka-topics.sh с параметрами –alter –partitions для ручного переназначения разделов. Однако, подобными ручными вмешательствами лучше не увлекаться, а полагаться на типовые решения. Для этого администратор кластера Kafka и дата-инженер должны понимать особенности их реализации.
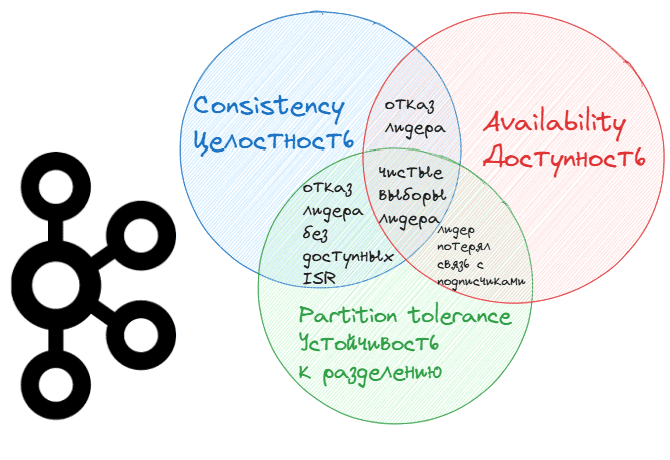
Когда лидер раздела топика Kafka больше не доступен, одна из синхронизированных реплик выбирается в качестве нового лидера. Такой выбор считается «чистым» (clean), поскольку он гарантирует отсутствие потери зафиксированных данных, т.к. они по определению существуют во всех ISR. Если же ISR не существует, т.е. только что опубликованных данных нет нигде кроме лидера, который стал недоступен, по умолчанию Kafka ожидает появления ISR. В этом случае есть риск недоступности топика. Таким образом, дилемма CAP-теоремы, которая говорит, что для распределенных систем можно обеспечить лишь 2 свойства из 3-х (Consistency, Availability, Partition tolerance).
Рассмотрим несколько примеров отказа лидера в Kafka, иллюстрирующих дилемму CAP-теоремы:
- высокая согласованность и доступность (Consistency-Availability), когда брокер-лидер вышел из строя из-за сбоя оборудования, а реплики на 2-х брокерах-подписчиках находятся в списке ISR, то есть полностью синхронизированы с лидером. Поскольку в списке ISR присутствуют обе реплики, Kafka быстро выберет из них нового лидера. Таким образом, все зафиксированные данные будут доступны на новом лидере без потери и простоев доступности, а вся система продолжит работать несмотря на отказ брокера. В случае чистых выборов нового лидера Kafka сохраняет согласованность и доступность, обеспечивая устойчивость к разделениям сети.
- отказ лидера без доступных ISR (Consistency-Partition tolerance), когда из-за высокой нагрузки или сетевых проблем реплики не успевают синхронизироваться и покидают список ISR, а брокер-лидер выходит из строя. Поскольку в списке ISR больше нет реплик, способных стать новым лидером без риска потери данных, Kafka ждет появления хотя бы одной ISR-реплики. В этом случае гарантируется отсутствие потери данных, так как выбор нового лидера возможен только при наличии синхронизированных реплик. До восстановления ISR-реплик или приведения их в синхронное состояние возможна временная потеря доступности топика. Вся система сохраняет устойчивость к разделению, но снижается ее доступность до восстановления ISR-реплик.
- Потеря связи лидера с подписчиками, когда подписчики потеряли связь с брокером-лидером из-за сетевого разделения, хотя он сам по себе доступен и продолжает. Если в ISR-наборе содержатся брокеры-подписчики, среди них может произойти выбор нового лидера. Но если сетевое разделение мешает признать брокеры-подписчики как ISR-набор, выбор лидера откладывается, чтобы избежать конфликтов. В итоге данные не могут быть реплицированы с брокера-лидера. Однако, такая рассинхронизация прекращается почти сразу, т.к. в Kafka новые лидеры выбираются только из синхронизированных реплик. В итоге согласованность будет сохранена, а доступность ограничена, если выбор нового лидера задерживается из-за разделения сети.
Повлиять на особенности реализации CAP-теоремы в Apache Kafka можно с помощью следующих конфигураций:
- leader.rebalance.enable — автоматическая балансировка лидеров, по умолчанию включено (true). Фоновый поток проверяет распределение лидеров разделов через регулярные интервалы, настраиваемые с помощью leader.imbalance.check.interval.seconds. Если дисбаланс лидеров превышает leader.imbalance.per.broker.percentage, запускается перебалансировка лидеров на предпочтительного лидера для разделов.
- leader.imbalance.check.interval.seconds — частота, с которой контроллер запускает проверку балансировки раздела, по умолчанию каждые 5 минут;
- imbalance.per.broker.percentage – коэффициент дисбаланса лидера, разрешенный для каждого брокера. Контроллер активирует баланс лидера, если он превышает это значение для каждого брокера. Значение указывается в процентах, по умолчанию равно 10. Это означает, что каждый брокер может иметь до 10% отклонения от идеального равномерного распределения лидеров. Контроллер кластера Kafka постоянно отслеживает распределение лидирующих партиций среди всех брокеров. Если количество лидирующих разделов на каком-либо брокере превышает установленный порог дисбаланса, например, на 10% больше, чем должно быть при равномерном распределении, контроллер инициирует процесс балансировки.
- unclean.leader.election.enable – включение «нечистых» лидеров, когда реплики, не входящие в набор ISR, могут быть избранными в качестве лидера. Это чревато потерями данных, что мы рассмотрим далее.
Чем опасны нечистые выборы лидера
В версиях Kafka до 0.11.0 настройка unclean.leader.election.enable была включена по умолчанию. При включении этой настройки в значение true можно потерять все сообщения, опубликованные на «старом» лидере, но не реплицированные на брокеров-подписчиков. Это может вызвать рассогласование данных в потребителях. Нечистые выборы лидера происходят, когда «нечистый» брокер, не входящий в набор ISR и закончивший репликацию последних данных от предыдущего лидера, становится новым лидером. Хотя это повышает доступность данных, над долговечностью, она может привести к потере данных, т.к. Kafka хранит данные по разделам топика, и каждый раздел имеет лидера и ноль или более подписчиков.
Каждый брокер служит лидером для определенных разделов и подписчиком для других, снижая вероятность отказа. Для любых разделов, где брокер был назначен лидером, он обрабатывает входящие пакеты сообщений и назначает каждому сообщению смещение – целое число, идентифицирующее его позицию для потребления данных из лога. Пока подписчики на связи с лидером и остаются доступными, регулярно опрашивая его на предмет новых данных, они считаются частью набора синхронизированных реплик (ISR). Если какие-то подписчики отстают от лидера раздела, они удаляются из ISR, пока не догонят его.
При отключении unclean.leader.election.enable по умолчанию с версии 0.11.0.0, Kafka не может выбрать нового лидера в определенные моменты времени, которые были рассмотрены ранее в дилемме CAP-теоремы. Например, когда лидер стал недоступным и ни одна из реплик не догнала прежнего лидера. При этом Kafka остановит все чтения и записи в этот раздел, поскольку подписчики только реплицируют новые данные от лидера, но не доступны для фактической публикации сообщений от продюсера.
Если включить unclean.leader.election.enable в значение true, Kafka равно сможет поддерживать доступность раздела, выбрав нового лидера, даже при отсутствии синхронизированных реплик, когда ISR=0. Такие «нечистые» выборы лидера повышают доступность кластера, но могут привести к потере данных, если они не дублируются в другой кластер или другое место хранения. При сборе брокера-лидера один из брокеров-последователей выбирается новым лидером, даже если он не входит в ISR-набор. Благодаря этому продюсеры и потребители продолжают отправлять запросы в этот раздел топика.
Однако, когда предыдущий лидер вернется в строй, он сбросит свое смещение, чтобы оно соответствовало смещению нового лидера. Это приведет к потере данных. Избежать такой неконсистентности поможет репликация данных в другой кластер Kafka, например, с помощью MirrorMaker или других инструментов геораспределенной репликации. Также можно сохранять события в персистентном хранилище, например, базе данных в соответствии с архитектурным паттерном Transaction Outbox.
Если кластер Kafka работает в режиме KRaft вместо использования Zookeeper для синхронизации метаданных, при динамическом включении конфигурации unclean.leader.election.enable необходимо периодически ожидать около 5 минут, пока запустится поток выборов. Если нужнео запустить выборы нового лидера немедленно, это можно сделать с помощью утилиты kafka-leader-election.sh с опцией unclean. Однако, как уже было отмечено ранее, это не рекомендуется.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

