 1240
1240 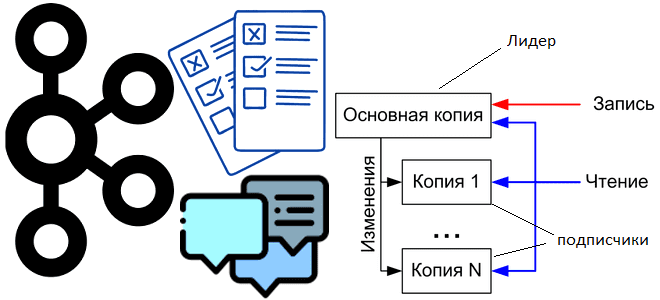
Сегодня рассмотрим, как внутренние механизмы Apache Kafka обеспечивают отказоустойчивость это потоковой платформы передачи событий, а также разберем, почему до сих пор приходится выбирать между доступностью и надежностью. Выборы нового лидера при сбое прежнего и ожидание подтверждений об успешной репликации.
Поиск компромисса между надежностью и доступностью в Apache Kafka
Для обеспечения отказоустойчивости Apache Kafka использует механизм репликации, копируя сообщения, отправляемые приложением-продюсером в раздел топика, который располагается на лидере, по другим узлам кластера (последователями). За количество копий отвечает параметр конфигурации топика под названием фактор репликации. Можно настроить определенное количество реплик для распределения между брокерами Kafka, а затем установить одну из них в качестве избранного лидера, а остальные узлы станут последователями. Клиент, т.е. приложение-продюсер, взаимодействует только с лидером, который самостоятельно реплицирует сообщения. Если брокер-лидер внезапно отключается, что может произойти при программном или аппаратном сбое, происходят перевыборы лидера: один из последователей становится лидером, а все остальные реплики подписываются на него. Это переназначение обеспечивает эффективную и действенную репликацию сообщений с несколькими копиями между разными брокерами.
В конфигурации приложения-продюсера можно настроить параметр acks, отвечающий за надежность, т.е. подтверждение распространения реплик по всем брокерам-подписчикам. По умолчанию, когда acks=all, подтверждение происходит, как только все текущие синхронизированные реплики получают сообщение. Но ожидание подтверждения снижает пропускную способность системы, сокращая скорость и количество отправляемых в Kafka сообщений. Впрочем, это вопрос баланса доступности и надежности. Например, если топик имеет две реплики и одна из них потерпела сбой, сообщения могут быть потеряны, когда оставшаяся реплика также выйдет из строя. Подробнее об этом мы писали здесь. Такое поведение может быть нежелательным для пользователей, предпочитающих надежность доступности. Поэтому в Kafka есть 2 конфигурации топика, которые можно настроить для предпочтения надежности сохранения сообщений вместо высокой доступности системы:
- отключение непрозрачных выборов лидера (leader.election), когда все реплики станут недоступными, то раздел останется недоступным до тех пор, пока самый последний лидер снова не станет доступным;
- определение минимального размера синхронизированных реплик (ISR, in sync replicas), когда раздел топика будет принимать новые записи только в том случае, если заданный размер ISR выше определенного минимума. Это предотвращает потерю сообщений, которые были записаны только в одну реплику, если она стала недоступной. Этот параметр работает, только если продюсер ожидает подтверждения распространения реплик (acks=all) и гарантирует, что сообщение будет подтверждено как минимум этим количеством синхронизированных реплик.
Определение ISR предлагает компромисс между согласованностью и доступностью: более высокое значение гарантирует лучшую согласованность, поскольку сообщение гарантированно будет записано в большее количество реплик, что снижает вероятность его потери. Но это снижает доступность, поскольку раздел топика становится недоступным для записи, если количество синхронизированных реплик упадет ниже минимального порога. Подробнее о дилемме CAP-теоремы в Apache Kafka читайте в новой статье.
Чтобы понять описанные механизмы Apache Kafka, следует вспомнить принципы распределения реплик по узлам брокера и выбора лидера реплицируемого раздела. Именно это мы и рассмотрим далее.
Выборы лидера
Итак, гарантия надежности Kafka в отношении потери данных основана на том, что по крайней мере одна реплика остается синхронизированной. Но при сбое всех узлов, реплицирующих раздел топика, этот механизм перестает работать. Чтобы решить эту проблему, можно подождать восстановления реплика из ISR-набора, и вручную выбрать ее в качестве лидера. Альтернативой является простой выбор любой реплики, не обязательно входящей в ISR, которая назначится на роль лидера самой Kafka. По умолчанию, начиная с версии 0.11.0.0, Kafka выбирает первую стратегию и предпочитает ожидание согласованной реплики. Это поведение можно изменить с помощью свойства конфигурации unclean.leader.election.enable для сценариев, когда время безотказной работы предпочтительнее согласованности.
Поэтому систем, где потерю сообщений неприемлема, важно убедиться, что конфигурация unclean.leader.election отключена. Но, если потеря сообщений приемлема и важна высокая доступность кластера, можно включить эту конфигурацию. На практике имеет смысл рассматривать этот вопрос отдельно для каждого топика.
Впрочем, подобная дилемма характерна не только для Kafka: она существует в любой схеме на основе кворума. Например, в схеме мажоритарного голосования, если большинство серверов терпят постоянный сбой, приходится терять 100% данных или нарушить согласованность, приняв то, что осталось на существующем сервере, в качестве нового источника истины. Вообще в распределенных системах для достижения согласованности данных между репликами очень распространен подход мажоритарного голосования, когда лидер выбирается по максимальному значению какой-то из важных метрик. Например, количество зафиксированных сообщений. Однако, Kafka использует другой подход к выбору своего кворума, динамически поддерживая ISR-набор, которые догоняют лидера, вместо подсчета большинства. Только члены этого ISR-набора имеют право быть избранными в качестве лидера. Запись в раздел Kafka не считается зафиксированной, пока ее не получат все синхронизированные реплики. Этот набор ISR сохраняется в метаданных кластера при каждом изменении. Поэтому любая реплика в ISR-наборе может быть избрана лидером. Такой подход отлично подходит для Kafka, где много разделов и важно обеспечить баланс лидерства, позволяя выдерживать сбои брокеров без потери зафиксированных сообщений.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
При этом Kafka не требует, чтобы поврежденные узлы восстанавливались со всеми неповрежденными данными. Алгоритмы репликации в этом пространстве нередко зависят от наличия стабильного хранилища, которое не может быть потеряно в любом сценарии восстановления после сбоя без потенциальных нарушений согласованности. Но есть две основные проблемы с этим предположением:
- дисковые ошибки, которые затрагивают данные;
- использование системного вызова fsync(), который синхронизирует файл с хранилище, копируя на диск все части файла, находящиеся в памяти. Этот системный вызов ожидает пока устройство ответит, что все части сохранены при каждой записи для гарантий согласованности, что на порядок снижает производительность всей системы.
В Kafka используется протокол, разрешающий повторное присоединение реплики к ISR, чтобы перед повторным присоединением она снова полностью повторно синхронизировалась на случай восстановления несохраненных данных в результате сбоя.
При выборе нового лидера необходим баланс, чтобы каждый узел был лидером для пропорциональной доли своих разделов. Также важно оптимизировать процесс выборов, поскольку это критическое окно недоступности. За управление регистрацией брокеров в кластере Kafka отвечает контроллер, реализуя выбор одного из ISR-узлов в качестве нового лидера при отказе прежнего. Такая централизация позволяет объединять множество необходимых уведомлений о смене лидера, что делает процесс выборов быстрее для большого количества разделов. Если сам контроллер выйдет из строя, будет выбран другой. За период (в миллисекундах), в течение которого должны начаться выборы нового лидера, отвечает конфигурация контроллера controller.quorum.election.backoff.max.ms. Это значение используется в механизме бинарной экспоненциальной отсрочки для выбора лидера, чтобы предотвратить ее зацикливание. А максимальное время без получения выборки от большинства последователей перед запуском процедуры определения лидера задает конфигурация controller.quorum.fetch.timeout.ms.
Однако, аварийное переключение лидера не может покрыть все возможные сбои. Если брокер недоступен извне, но может общаться с другими узлами кластера, отработка отказа лидера не запускается. Аналогичная ситуация будет, если у брокера возникли временные проблемы с диском или сетью, то процесс выбора нового лидера завершится неудачно. В таких случаях требуется ручное вмешательство администратора кластера Apache Kafka.
Для этого разработчики коммерциализированной версии Apache Kafka в облачной платформе Confluent Cloud реализовали функцию приоритета лидерства, которая позволяет расставлять приоритеты у одних брокеров над другими и указывать, какой брокер с наибольшей вероятностью станет лидером в случае отказа. Это дает возможность гарантировать, что самый надежный брокер будет выполнять более важные и конфиденциальные задачи репликации, обеспечивая согласованность и доступность данных даже в случае непредвиденного сбоя. Усовершенствования этого компонента Kafka позволят применять его в самых разных сценариях. Например, администратору кластера это пригодится при устранении проблем с производительностью одного брокера во время отладки. Также здесь будет полезен механизм плавного завершения работы отдельного узла в кластере, что мы разбираем в новой статье.
В заключение отметим, что инструмент командной строки kafka-preferred-replica-election был заменен в Apache Kafka на kafka-leader-election – shell-скрипт, который находится в каталоге /bin.
Освойте администрирование и эксплуатацию Apache Kafka и Flink для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

