
В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза.
MLOps с AirFlow и MLFlow в облаке AWS
Ранее мы рассказывали, как международная рекрутинговая компания Glassdoor реализовала концепцию MLOps для автоматизации и мониторинга масштабируемых систем машинного обучения. Применяя принципы DevOps к разработке и развертыванию ML-решений, MLOps включает оркестровку экспериментов, отслеживание показателей, реестр моделей, инструменты автоматизации рутинных операций и мониторинг производительности моделей. С учетом роста объема данных и средств их обработки, это стало актуально для любой бизнес-области. Например,
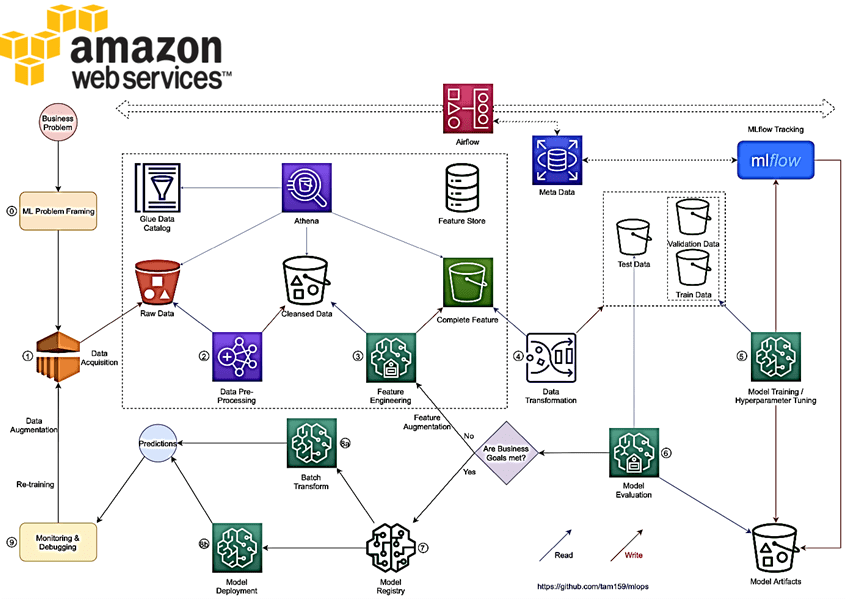
С использованием Apache AirFlow для оркестрации пакетных заданий, MlFlow для трекинга и организации экспериментов, а Amazon SageMaker для обучения, настройки гиперпараметров, обслуживания моделей и мониторинга, внедрение систем Machine Learning сводится к следующим шагам:
- сбор данных из разных источников, их интеграция и проверка качества;
- предварительная обработка данных, включая обнаружение выбросов, пропусков и пр.;
- feature engineering – выявление предикторов, которые важны для конечного результата моделирования;
- преобразование данных, включая их нормализацию, стандартизацию и приведение к формату, совместимого с алгоритмами машинного обучения;
- машинное обучение, включая настройку параметров и значимых показателей модели. Это можно сделать с помощью инструментов AutoML, таких как MLF Также можно использовать сервис SageMaker Hyperparameter Optimization, запустив его с обучающими заданиями, а затем выполнить поиск метрик и параметров в MLFlow, чтобы найти лучшую версию модели.
- оценка модели — анализ ее производительности на основе результатов обработки тестовых данных;
- если ожидаемые бизнес-цели достигнуты, модель можно зарегистрировать в MLFlow или в SageMaker Inference Models.
- Получать результаты моделирования на реальных данных можно через SageMaker Batch Transform для пакетных прогнозов или настроить конечную точку с SageMaker Inference Endpoints.
- Наконец, необходимо организовать мониторинг и отладку всего процесса, включая переобучение ML-моделей с обогащением и обновлением данных.
Airflow и MLflow можно развернуть их в любой инфраструктуре: Kubernetes, ECS и пр. с метаданными, хранящимися в RDS. Использование Airflow в качестве планировщика упрощает архитектуру, поскольку все вычислительные задания будут обрабатываться SageMaker и другими сервисами AWS. MLFlow нужен для поддержки основных задач жизненного цикла машинного обучения, обеспечивая центральный реестр моделей их развертывание, управление кодом проекта и отслеживание экспериментов. После определения исходных данных и ожидаемых результатов, необходимо оптимизировать показатели производительности и ошибок.
Для обработки данных, разработки функций и оценки моделей можно использовать несколько сервисов AWS:
- EMR как кластер экосистемы Hadoop с предустановленными фреймворками Spark, Flink и т.д.;
- Glue как безсерверная среда Apache Spark, Python;
- Задания обработки SageMaker, которые выполняются в контейнерах, предоставляют множество готовых образов для задач Data Science и поддерживают Spark 3. AWS SageMaker экономически эффективен при использовании спотовых инстансов EC2.
- объектное хранилище AWS S3 для надежного хранения данных;
- Athena для запроса данных из S3 с метаданными из каталога Glue.
Загружать данные в SageMaker Feature Store можно партиями непосредственно в само автономное хранилище фичей.
Дополнительным плюсом описанного MLOps-решения на сервисах AWS является его переносимость и масштабируемость. Однако, несмотря на отсутствие локальной инфраструктуры, расходы на облачные платформы могут оказаться весьма существенными. Как переход на Spark версии 3 помог компании Insider снизить стоимость EMR-кластера, мы расскажем далее.
Экономия 40% на кластере AWS EMR с Apache Spark 3
В Insider конвейеры данных активно используют Spark для рабочих нагрузок ETL и машинного обучения. Задания Spark обеспечивают фактически полный цикл ML, от обработки необработанных данных, извлечения и отбора признаков, подготовки данных к моделированию, до обучения и настройки моделей. Особенным преимуществом Spark версии 3 для Insider был рост производительности, связанный с новыми коммиттерами S3, которые поддерживали переименование файлов без предварительной их загрузки во временное расположение. Новые коммитеры S3A сократили время записи в S3 с минут до секунд.
Также EMR с Apache Spark 3 позволяет использовать инстансы с процессорами AWS Graviton2 c EMR 6.1 и 5.31 для предыдущей версии фреймворка. Инстансы с этими мощными процессорами, такие как M6g, C6g и R6g, обеспечивают на 30 % более низкую стоимость инстанса по запросу и на 10 % более низкую стоимость спотового инстанса.
Перед обновлением до Spark 3 дата-инженеры Insider провели множество функциональных тестов и тестов производительности. За рост производительности принято общее сокращение времени и нормализованное сокращение времени как разница времени, затраченного на S3, и операций записи в базу данных из общего времени задания.
Задания по агрегации данных чаще всего считывают различные наборы данных из S3, выполняют над ними различные операции объединения и агрегирования и записывают результаты обратно в S3. Поскольку окончательные наборы данных составляют порядка сотен гигабайт, тестирование показало значительное сокращение времени (57%-77%) благодаря коммиттерам S3A и увеличение производительности (нормализованное время) от 12% до 28%.
Задание обучения модели считывает набор данных из S3 и обучает модель машинного обучения с помощью библиотеки Spark MLlib. Здесь Spark 3 помог сократить время обучения модели на 37%.
Задание вывода загружает предварительно обученную модель машинного обучения и считывает набор данных из S3 для выполнения вывода.
В проведенных тестах время пакетного вывода сократилось на 32%. Поскольку результаты вывода записываются обратно в S3, общее сокращение времени составило 63%. Таким образом, фактическое время выполнения заданий снижено от 20% до 80%, что сократило фактические затраты на кластер EMR на 40% после завершения миграции. Как аналогичную задачу решала команда инженеров Doulingo, мы рассказываем здесь. А как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX или контейнер с контекстом Spark, читайте в нашей новой статье.
Как внедрить лучшие практики MLOps с Apache Spark и AirFlow для эффективной аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

