 1057
1057 
Содержание
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana.
Предыстория: зачем MLOps в Glassdoor
Glassdoor с 2008 года помогает соискателям по всему миру найти работу мечты, а работодателям – встретить надежных и талантливых сотрудников. Сегодня для этого компания использует машинное обучение, чтобы быстрее предлагать соискателям и работодателям релевантные предложения. При том, что машинное обучение (Machine Learning, ML) открывает новые возможности для бизнеса, качество результатов сильно зависит от данных, а также навыков команды инженеров и разработчиков.
По сравнению с традиционным процессом разработки ПО, вместо простой компиляции измененного исходного кода, ML-модели необходимо переобучить на большом количестве данных, прежде чем использовать в production. Поэтому версионирование ML-моделей должно учитывать изменения как кода, так и данных. Данные могут меняться по разным причинам, от инженерных способов сбора и обработки, до изменения поведения клиентов, что также может быть вызвано применением ML. Этот фактор создает скрытую петлю обратной связи в контуре управления ML-системой, которую также следует учитывать.
Что касается навыков команды реализации, сложность состоит в том, что помимо аналитиков и ученым по данным (Data Scientist) для интеграции ML-решения в производство и его непрерывного использования также нужны разработчики, дата-инженеры и специалисты по сопровождению операций развертывания. Эту идею продвигает концепция MLOps – инженерная культура, практика и методология применения принципов DevOps к системам машинного обучения. MLOps ориентируется на комплексные решения для автоматизации и мониторинга для повышения производительности и надежности масштабируемых ML-систем. Решения MLOps включают множество компонентов, таких как оркестровка экспериментов, отслеживание показателей, реестр моделей, автоматизация развертывания и мониторинг производительности моделей.
MLOps в Glassdoor реализован с помощью нескольких инструментов, чтобы обеспечить следующие потребности компании:
- обслуживание ML-моделей в реальном времени;
- отслеживание экспериментов;
- хранилище фич
- пакетное обслуживание и обучение ML-моделей;
- автоматизация развертывания.
Далее рассмотрим, с помощью каких инструментальных средств это реализовано.
Обслуживание ML-модели в реальном времени
В Glassdoor большинство серверных систем написаны на Java, поэтому конвейеры развертывания ориентированы именно на эту технологию. Но чаще всего ML-программы разрабатываются на Python, а их разработчикам не хватает опыта работы с Java. Это создает разрыв интеграции ML-решений с существующими системами. В частности, приходится переписывать алгоритмы машинного обучения с Python на Java для бесшовной интеграции, что занимает временные и трудовые ресурсы, а также может стать потенциальным источником ошибок.
Чтобы преодолеть это узкое место, был разработан конвейер автоматизации развертывания ML-моделей в виде сервисов REST в Kubernetes, который обеспечивают независимый от языка доступ на основе MLFlow, Jenkins и Spinnaker. Этот MLOps-фреймворк выступает в качестве CI/CD-средства управления жизненным циклом разработки Machine Learning, предоставляя GUI для отслеживания нескольких экспериментальных запусков. Также MLFlow упаковывает модели машинного обучения, управляет зависимостями пакетов и создает обслуживающие сервисы в режиме реального времени. Наконец, MLFlow является единым интерфейсом для множества инженерных команд, по-прежнему позволяя им использовать разные инструменты хранения моделей, управления версиями и написания собственных REST-сервисов.
Автоматизация развертывания и мониторинг нагрузки
Glassdoor активно переносит свои пакетные рабочие нагрузки и stateless-сервисы в Kubernetes, что дает большую гибкость и масштабируемость управления инфраструктурными средами. Чтобы соответствовать корпоративным методам обеспечения безопасности, компания не использует утилиты командной строки MLFlow. Вместо этого написан собственный Docker-файл, который упаковывает библиотеки MLFlow и зарегистрированные артефакты модели для создания образа. Конструктор Docker-образов, работающий на Jenkins, извлекает последнюю зарегистрированную версию модели для создания нового образа контейнера и отправляет его в частный реестр контейнеров на AWS. Для развертывания приложений машинного обучения в кластере используется Spinnaker с его диаграммами управления контейнеризованными приложениями, которые создают hpa, вход, развертывание, sa и службу для развертываемого приложения.
Каждый из корпоративных сервисов обычно отвечает в течение нескольких миллисекунд при нагрузке 20–60 000 запросов в секунду. Все логи Kubernetes Pod из кластера пересылаются и собираются в едином решении для централизованного логирования. Также туда экспортируются все метрики пода и приложений с помощью экспортера Prometheus. Grafana выступает средством визуализации и оповещений.
Для реализации идей DevOps, в частности, CI/CD и управления инфраструктуры как кодом применяется GitLab. Туда переносятся конвейеры сборки и развертывания с Jenkins и Spinnaker, где далее будет развернута полная модель GitOps, чтобы инженеры смогли выполнять все операции за одну остановку.
Пакетное обслуживание и обучение моделей
Прогнозирование в пакетном режиме строится на обработки огромного количества данных. В этом случае пропускная способность ML-системы важнее времени ответа на отдельные запросы. Для относительно простых и легковесных моделей машинного обучения применяется Jenkins. Он считывает из репозитория Python-код, загружает модель через API MLFlow из реестра моделей, чтобы запустить ее сразу или запланировать запуск по расписанию. Собственное решение Glassdoor типа PaaS (платформа как услуга) может создавать настраиваемые задания Jenkins и загружать их на нужных типах узлов с учетом версии Python и обучающих скриптов, которые проверяются как конфигурации.
Для более сложных ML-моделей используется Airflow как мощный оркестратор и координатор шагов конвейера. В DAG может быть задействовано несколько моделей с указанием зависимостей, условий и параллелизма. DAG Airflow копируются Jenkins на сервер планировщика Airflow после объединения в основную ветку, а задачи Airflow запускаются в подах Kubernetes.
Если нужно увеличить размер данных или производительность обработки, модели запускаются в виде приложений Apache Spark, чтобы использовать возможности распределенных вычислений в кластере. Spark включает библиотеки машинного обучения: MLlib и Spark NLP, что отлично подходит для проектов Machine Learning. При использовании Apache Spark вместо загрузки ML-моделей с помощью API MLFlow, обученные модели отправляются в реестр моделей MLFlow для управления версиями и управления.
Отслеживание экспериментов и хранилище фич
Для отслеживания экспериментов, регистрации показателей и моделей также применяется MLFlow, который поддерживает XGBoost, TensorFlow и другие ML-библиотеки. В пользовательских моделях используется модуль MLFlow.pyfunc для выполнения шагов предварительной обработки в общих алгоритмах MLFlow. Далее эти модели с пользовательским кодом, пакетами и данными упаковываются воедино. Общие модели имеют настраиваемую логику вывода и загружаются как модель python_function, чтобы развернуть их как конечные точки REST. Это упрощает тестирование и обеспечивает более быструю обратную связь, позволяя использовать команды CLI-интерфейса MLFlow для локального тестирования.
Поскольку текущие ML-конвейеры Glassdoor не слишком сложны, функциональных возможностей MLFlow достаточно, но в будущем компания планирует перейти на Kubeflow со встроенной поддержкой Kubernetes и более широкий набор функций, включая настройку гиперпараметров, TensorBoard и пр. Также в перспективе возможно использование SageMaker для разработки модели в удаленной среде.
Для стандартизации способов хранения, обнаружения, доступа и отслеживания логических входов или предикторов ML-моделей машинного обучения, которые также называются фичами (feature), используется хранилище фичей (Feature Store). Оно служит интерфейсом между моделями и данными. В Glassdoor это SageMaker Feature Store, поверх которого создан уровень управления метаданными и доступа к фичам.
Наконец, уникальной проблемой создания ML-систем являются постоянно меняющиеся данные, которые определяют поведение моделей. Необходимо отслеживать и контролировать эти данные и производительность моделей с помощью предопределенных метрик, чтобы вовремя обнаруживать дрейф данных и принимать меры для поддержки системы. Для этого в Glassdoor применяется решение Whylogs от WhyLabs, которое просто использовать и легко интегрировать с внешними системами. В частности, компания планирует связать его с OpsGenie для оповещения и автоматизировать переобучение модели при достижении определенных пороговых значений.
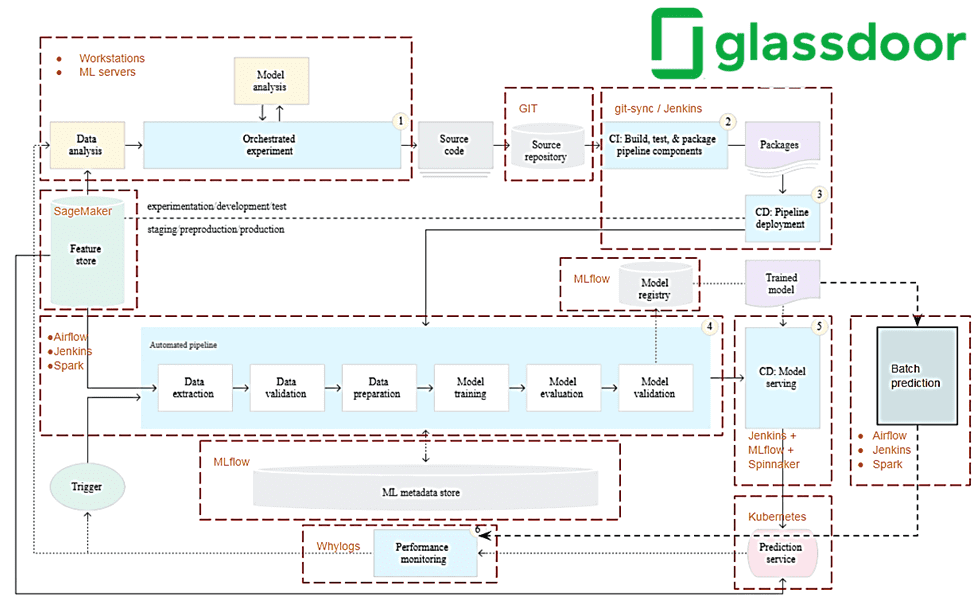
Таким образом, благодаря комплексному применению множества инструментов, компания Glassdoor смогла реализовать концепцию MLOps, чтобы специалисты Data Science могли сосредоточиться на анализе данных и разработке ML-моделей, а инженеры данных и DevOps могли создавать поддерживающие их платформы и инструменты. MLOps служит интерфейсом между разными командами, повышая их производительность и упрощая масштабирование. Как реализовать эту концепцию на сервисах AWS, читайте в нашей новой статье.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
15 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Все подробности практического использования этих и других инструментов MLOps для организации самоуправляемых конвейеров разработки и сопровождения ML-моделей в аналитике больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

