 1174
1174 
Содержание
Сегодня я на практическом примере покажу тонкости настройки конфигураций JDBC-коннектора источника, передающий новые записи из таблицы PostgreSQL в топик Apache Kafka.
Настройка JDBC-коннектора и отправка в Kafka Connect
Как я упоминала вчера, помимо CDC-коннектор Debezium, передать данные из реляционной базы данных PostgreSQL в Apache Kafka, также есть JDBC-коннектор от Confluent: Kafka Connect JDBC Source. Он основан на JDBC-драйвере и периодических SQL-запросах к таблицам, указанным в конфигурации коннектора. Этот JDBC-коннектор настраивается намного проще, чем CDC-коннектор Debezium, не требуя изменений в конфигурации базы данных, таких как включение логической репликации и создания слота репликации, что я показывала здесь.
Сперва создадим конфигурацию коннектора. В качестве примера я, как обычно, возьму интернет-магазин. Предположим, необходимо передавать изменения данных из таблицы с продуктами (product) PostgreSQL в Kafka.
В отличие от CDC-коннектора, режим обновлений в JDBC-коннекторе гораздо менее гибок: параметр mode конфигурации коннектора может принимать только одно из следующих значений:
- bulk –массовая загрузка данных всей таблицы каждый раз при ее опросе;
- incrementing — инкрементный столбец, который поможет обнаружить только новые строки. Этот режим не обнаружит изменения или удаления существующих строк.
- timestamp – столбец с отметкой времени для обнаружения новых и измененных строк. Предполагается, что этот столбец в базе данных обновляется при каждой записи, его значения монотонно увеличиваются, но не обязательно уникальны.
- timestamp+incrementing – комбинациях двух столбцов, отметки времени, который обнаруживает новые и измененные строки, и инкремента, который предоставляет глобальный уникальный идентификатор для обновлений, чтобы каждой строке можно было назначить уникальное смещение потока.
В моей таблице product отсутствует столбец отметки времени, поэтому параметр mode конфигурации коннектора установлю в значение incrementing. Полная конфигурация коннектора выглядит так:
{
"name": "pg-jdbc-source-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": "1",
"connection.url": "jdbc:postgresql://my-db-host:port/database",
"connection.user": "my-user",
"connection.password": "my-pass",
"table.whitelist": "ishop.product",
"mode": "incrementing",
"incrementing.column.name": "id",
"topic.prefix": "ishop-product-",
"poll.interval.ms": "10000",
"numeric.mapping": "best_fit",
"dialect.name": "PostgreSqlDatabaseDialect"
}
}
В этой конфигурации заданы следующие параметры:
- name — имя коннектора pg-jdbc-source-connector;
- class —класс коннектора io.confluent.connect.jdbc.JdbcSourceConnector, который будет использоваться для подключения к источнику данных через JDBC;
- max – максимальное количество задач, которые могут выполняться параллельно. В данном случае это одно подключение.
- url — URL для подключения к базе данных PostgreSQL;
- user – имя пользователя для подключения к базе данных;
- password — пароль пользователя для подключения к базе данных;
- whitelist — таблицы, которые будут использоваться коннектором, т.е. таблица product в схеме ishop.
- mode — режим извлечения данных (incrementing), инкрементальное извлечение данных на основе указанного столбца;
- column.name – название столбца (id), который будет использоваться для инкрементального извлечения данных. Обычно это первичный ключ или автоинкрементное поле. В моем случае это первичный ключ, который автоматически инкрементируется при вставке новой записи в таблицу.
- prefix – префикс (ishop-product-), который будет добавлен к имени Kafka-топика, куда будут отправляться данные из таблицы;
- interval.ms — интервал в миллисекундах между опросами базы данных на наличие новых данных (в данном случае 10000 равно 10 секунд);
- mapping — параметр преобразования числовых типов данных. Значение best_fit означает, что коннектор будет пытаться подобрать наиболее подходящий тип данных. Вообще параметр numeric.mapping может принимать значения none, precision_only, best_fit или best_fit_eager_double. Значение none устанавливается, если все столбцы NUMERIC должны быть представлены логическим типом DECIMAL Connect. Значение best_fit указывает, что столбцы NUMERIC должны быть преобразованы в INT8, INT16, INT32, INT64 или FLOAT64 на основе точности и масштаба столбца. Этот параметр может по-прежнему представлять значение NUMERIC как Connect DECIMAL, если его нельзя преобразовать в собственный тип без потери точности. Например, тип NUMERIC(20) с точностью 20 не сможет поместиться в собственный INT64 без переполнения и, таким образом, будет сохранен как DECIMAL. Значение best_fit_eager_double используется, когда надо всегда приводить числовые столбцы к типу данных Connect FLOAT64, несмотря на возможную потерю точности. Наконец, precision_only используется для сопоставления числовых столбцов только на основе точности столбца, когда масштаб столбца равен 0. По умолчанию используется none, что может привести к проблемам сериализации в AVRO, поскольку тип DECIMAL Connect сопоставляется с его двоичным представлением. Рекомендуется использовать best_fit, который сопоставляет данные с наиболее подходящим примитивным типом.
- name — диалекта базы данных (для PostgreSQL это PostgreSqlDatabaseDialect).
Чтобы зарегистрировать коннектор в Kafka Connect, надо оправить его HTTP-запросом POST в веб-сервер Kafka Connect. Поскольку платформа потоковой передачи у меня развернута в Docker на локальном хосте, в моем случае этот запрос будет выглядеть так:
curl -X POST -H "Content-Type: application/json" --data @pg-jdbc-source-connector.json http://localhost:8083/connectors

Это команда выполняется в командной строке, запуская утилиту curl с параметрами:
- -H «Content-Type: application/json», который добавляет HTTP-заголовок к запросу, указывая, JSON-формат передаваемых данных, чтобы сервер верно мог интерпретировать тело запроса;
- —data @pg-jdbc-source-connector.json — файл, который содержит данные JSON, отправляемые в теле POST-запроса. Символ @ перед именем файла указывает curl на то, что данные нужно прочитать из файла pg-jdbc-source-connector.json.
Если ошибок нет, коннектор после отправки сразу запустится, что сразу видно в GUI.
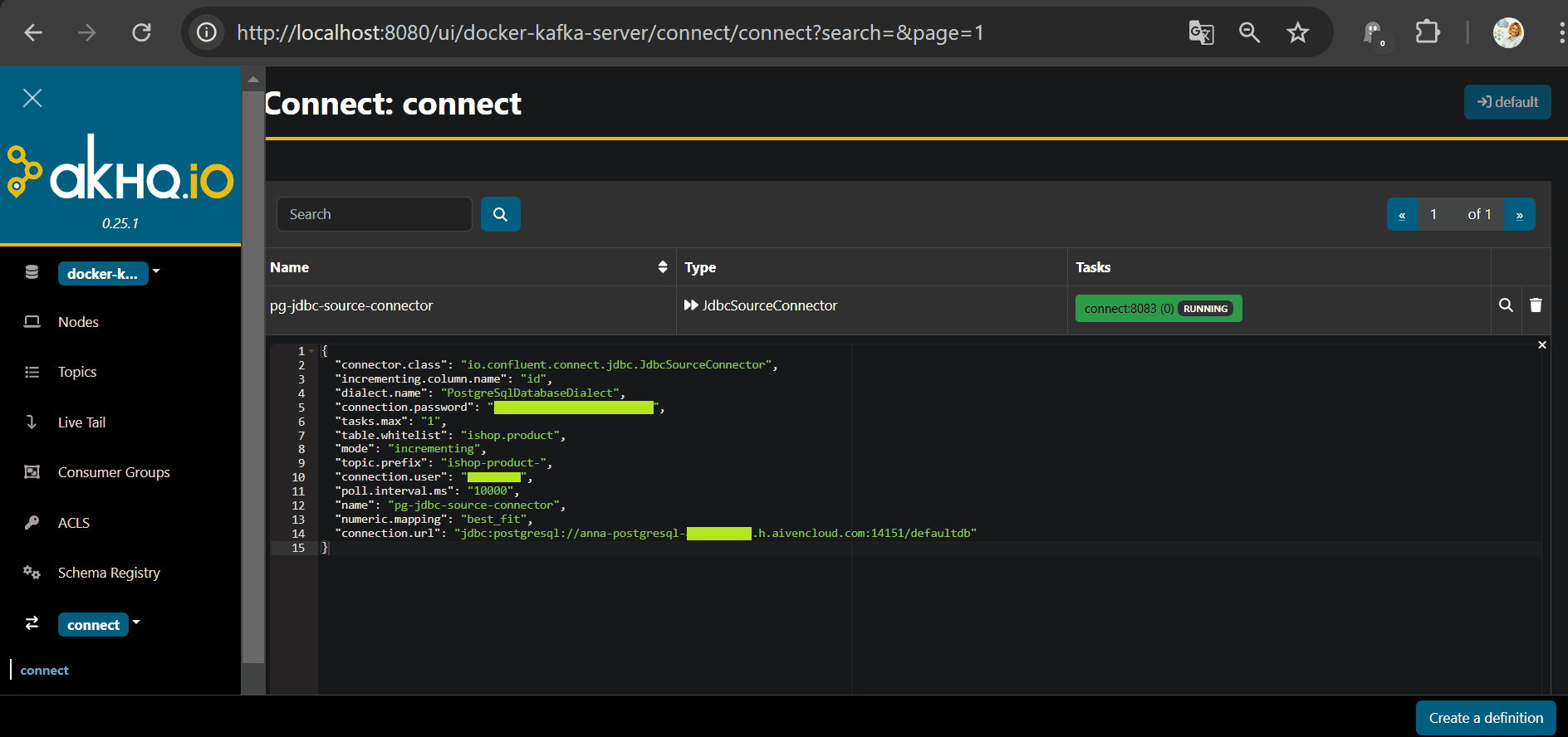
Передача новых данных из PostgreSQL с помощью коннектора
Как я уже отметила, JDBC-коннектор не требует никаких настроек на стороне источника данных, т.е. базы. После запуска коннектора автоматически создается топик Kafka, куда будут отправляться события вставки новых данных. Однако, из-за того, что поле цена (price) у меня типа numeric, изначально было некорректное сопоставление, когда параметр коннектора numeric.mapping был установлен в значение none.
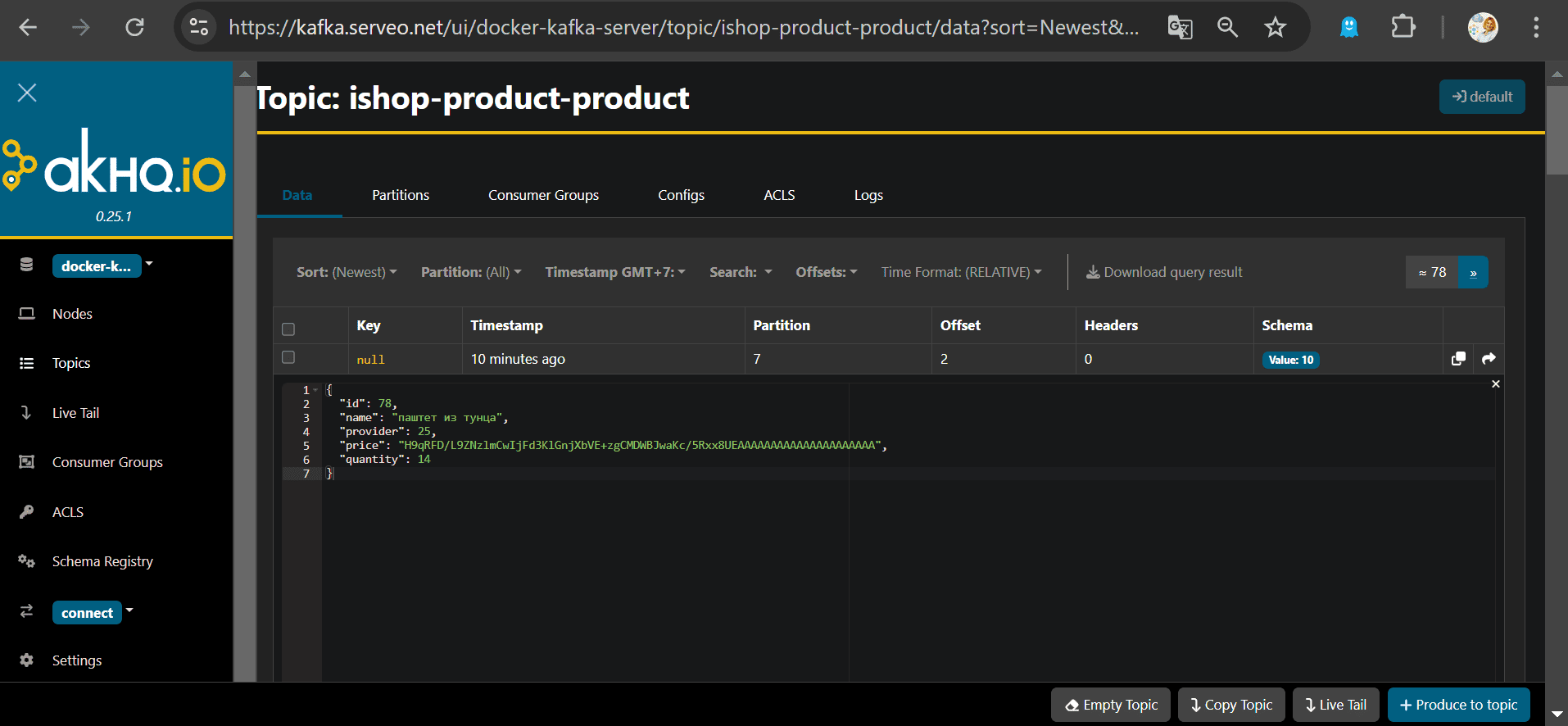
Исправить это оказалось не так просто. Оказалось, что помимо автоматического создания топика, Kafka Connect также создает в реестре схем схему данных, которая описывает поля публикуемого в топике сообщения и их типы.
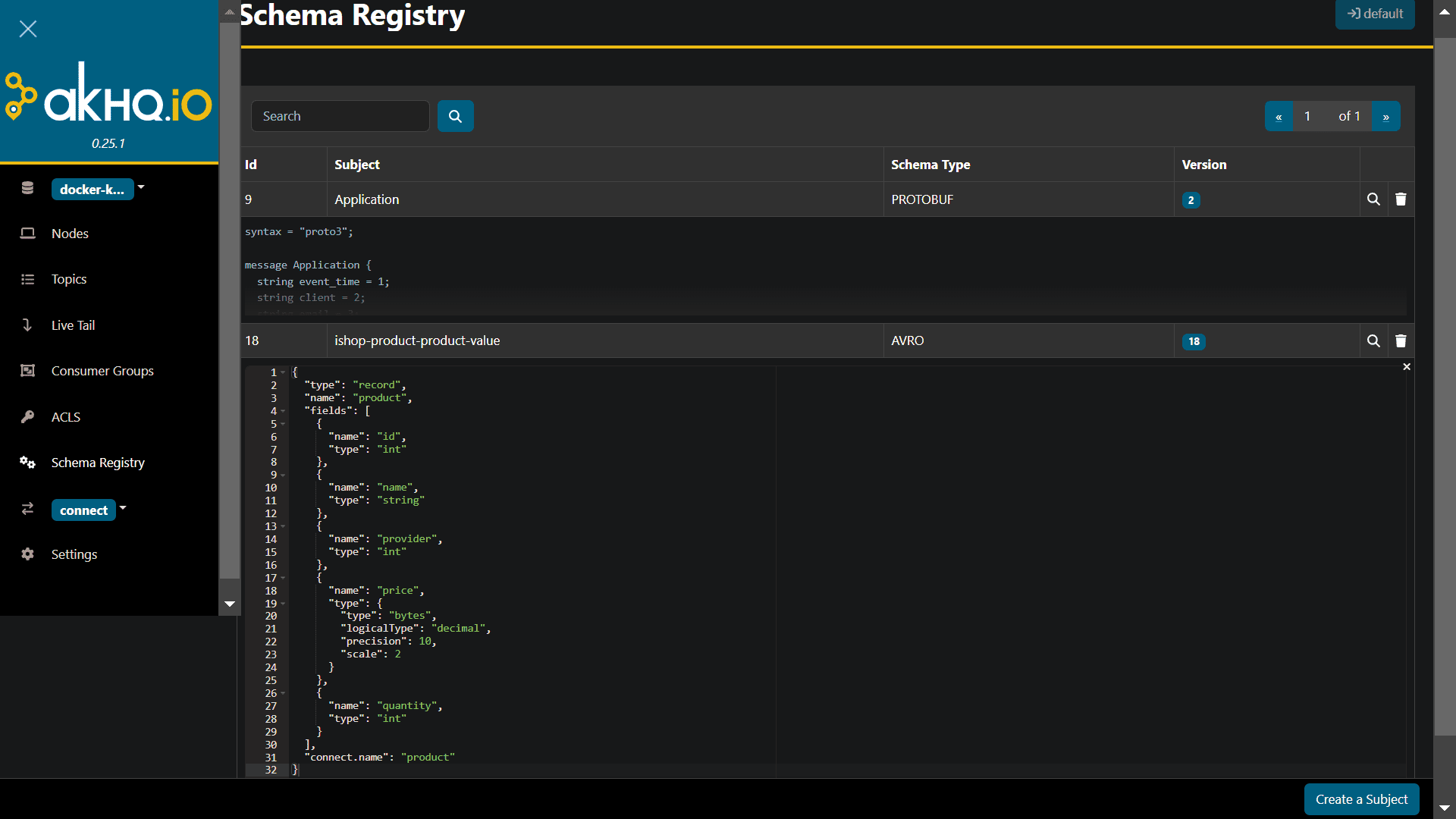
Эту схему данных в формате AVRO я отредактировала вручную, указав следующие параметры:
{
"type": "record",
"name": "product",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "provider",
"type": "int"
},
{
"name": "price",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 10,
"scale": 2
}
},
{
"name": "quantity",
"type": "int"
}
],
"connect.name": "product"
}
Изменения заняли несколько итераций, поскольку при первых запусках коннектора тип поля price был строковым, что не конвертировалось в вещественный. При этом пришлось изменить совместимость схемы в Schema Registry, временно установив ее на NONE, чтобы зарегистрировать новую версию. Это позволило сохранить старые данные, записывая новые данные с использованием новой схемы.
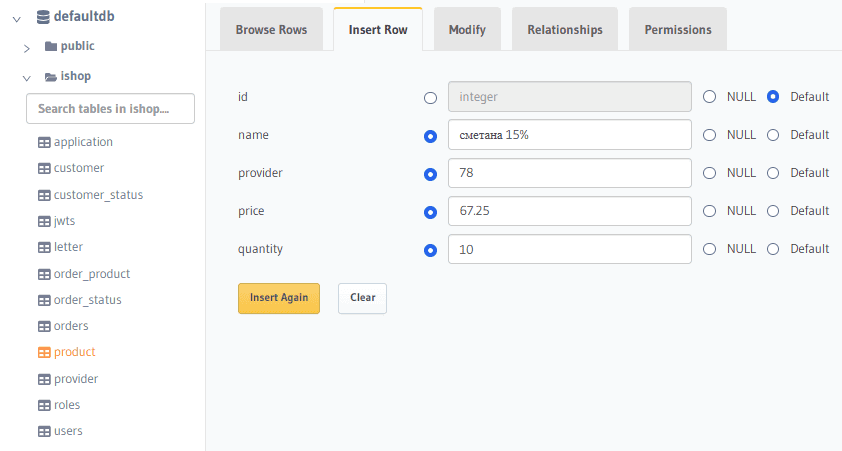
После добавления новой записи в таблицу PostgreSQL, она попадает в топик Kafka.
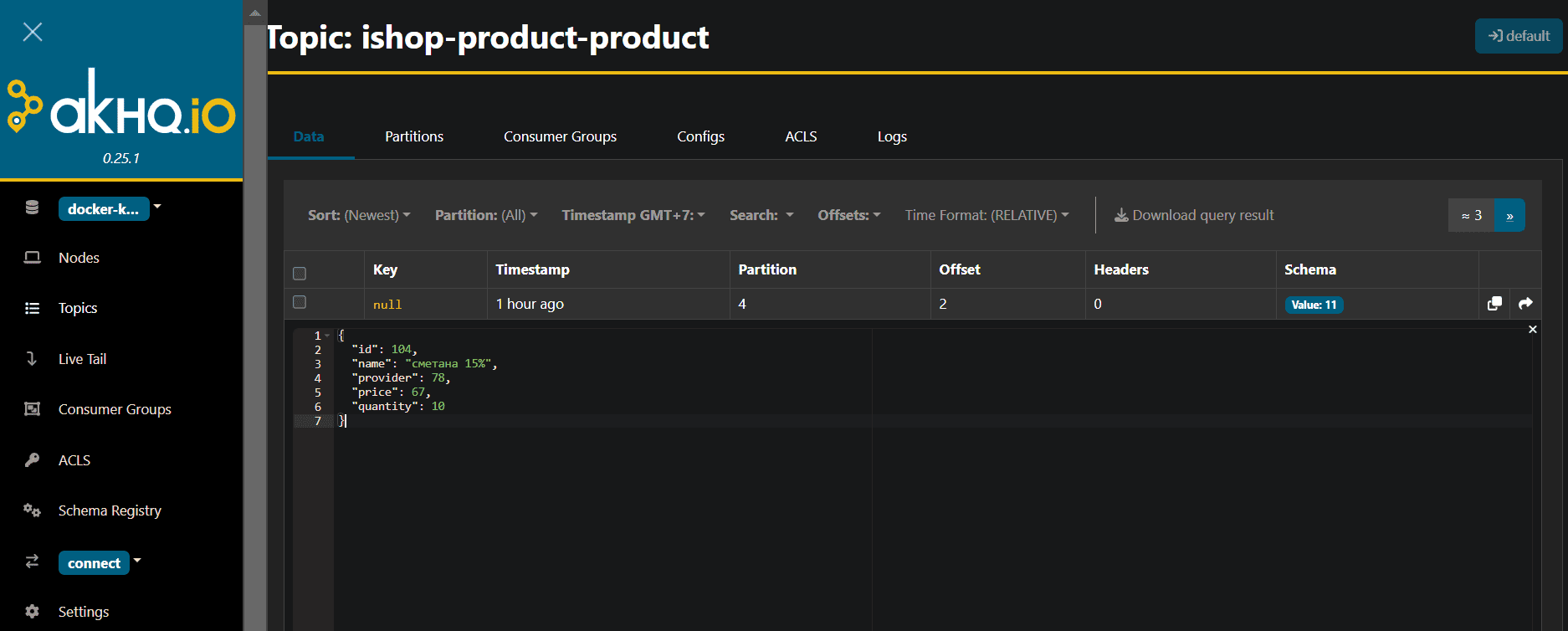
Однако, несмотря на верно указанное преобразование типов данных, вещественное значение преобразуется в целочисленное. Исправить это мне пока не удалось.
Подводя итоги работы с JDBC-коннектором, отмечу, что он понравился мне меньше, чем CDC-коннектор Debezium, поскольку имеет больше ограничений и меньше возможностей.
Освойте администрирование и эксплуатацию Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Apache Kafka в Kubernetes
Источники

