 1005
1005 
Содержание
ksqlDB – это база данных потоковой передачи событий, построенная по архитектуре клиент-сервер, которую можно запустить с одним сервером или сгруппировать несколько серверов вместе, чтобы использовать ее API на основе SQL для запроса и обработки данных, хранящихся в топиках Apache Kafka. KsqlDB позволяет выполнять различные операции потоковой аналитики больших данных: фильтрация, соединения, агрегация, создание материализованных представлений, преобразования и сопоставления потоков событий с помощью типового инструментария SQL-запросов.
Немного истории: что такое ksqlDB и чем это отличается от KSQL
В ноябре 2019 года компания Confluent, которая продвигает коммерческие решения на основе Apache Kafka, выпустила новый релиз KSQL, настолько важный, что назвала его именем ksqlDB. Как и KSQL, он остается в свободном доступе и лицензируется сообществом, скачать его можно абсолютно бесплатно прямо с GitHub. Самими важными обновлениями изменениями KSQL стали две новые функции [1]:
- запросы на вытягивание (Pull queries), которые интегрируют традиционный поиск в базе данных поверх материализованных таблиц с событиями с непрерывного потока данных. Они позволяют извлекать данные в определенный момент времени и/или запрашивать состояние. Например, приложению для совместных поездок необходимо постоянно получать информацию о текущей позиции водителя (push-запрос) и искать текущее значение цены поездки (pull-запрос). ksqlDB позволяет подписываться на местоположение по мере его изменения и постоянно передавать этот поток значений в приложение, объединяя традиционный тип запросов потоковой обработки KSQL с поиском по сохраненным данным, как в традиционной базе данных.
- управление коннекторами (Connector management) в рамках единого интерфейса вместо нескольких разных (Kafka, Connect и KSQL). Это важно, когда данные для аналитической обработки отсутствуют в Kafka, а находятся во внешней системе (одна или несколько традиционных СУБД, API приложений SaaS и пр.). С помощью коннекторов Kafka Connect можно получать нужные потоки данных и отправлять их в топики Kafka. Таким образом, приходилось работать в нескольких системах: Kafka, Connect и KSQL, интерфейсы которых отличаются друг от друга. Так можно напрямую управлять и запускать коннекторы, для работы с Kafka Connect.
Идея ksqlDB состоит в том, чтобы использовать один язык запросов SQL для работы как с потоками событий (асинхронность), так и с состоянием на определенный момент времени (синхронность). Это не требует отдельных кластеров для захвата, обработки или обслуживания запросов, а также объединяет подход к масштабированию, мониторингу и безопасности всей Big Data системы. Таким образом, ksqlDB позволяет создать полное приложение реального времени с помощью небольшого набора SQL-операторов [2].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как устроена ksqlDB: архитектуры и принципы работы
ksqlDB состоит из следующих основных компонентов [3]:
- Механизм или движок (Engine) — обрабатывает SQL-операторы и запросы. Пользователю просто определяет логику своего приложения, записывая SQL-операторы, а движок сам создает и запускает приложение на доступных серверах ksqlDB, работая на каждом экземпляре сервера. Движок, реализованный реализован в классе KsqlEngine.java, сам анализирует пользовательские операторы SQL и строит соответствующие топологии Kafka Streams.
- REST-интерфейс для клиентского доступа к движку позволяет взаимодействовать с механизмом ksqlDB из интерфейса командной строки, Confluent Control Center или любого другого клиента REST. REST-сервер ksqlDB реализован в классе KsqlRestApplication.java.
- интерфейс командной строки (CLI) — консоль для взаимодействия с экземплярами сервера и разработки потоковых приложений. CLI, реализованный в пакете io.confluent.ksql.cli, похож на аналогичные интерфейсы MySQL, Postgres и пр.
- Пользовательский интерфейс ksqlDB позволяет разрабатывать приложения ksqlDB в Confluent Control Center и Confluent Cloud.
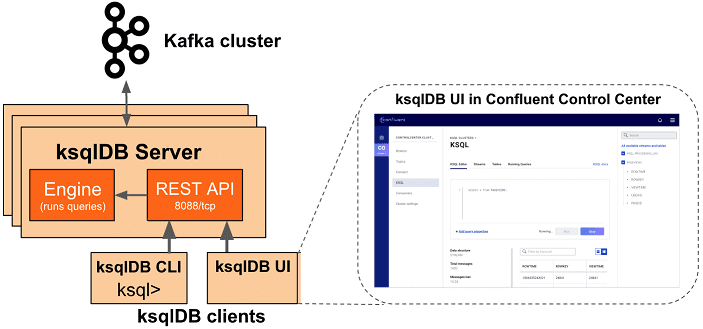
Сервер ksqlDB состоит из механизма ksqlDB и REST API. Экземпляры ksqlDB Server взаимодействуют с кластером Kafka. Увеличивать число экземпляров сервера можно по мере необходимости без перезапуска приложений. При развертывании приложения ksqlDB оно запускается на экземплярах сервера ksqlDB, которые не зависят друг от друга, являются отказоустойчивыми и могут масштабироваться с нагрузкой [3].
Базовые концепции потоковой обработки данных
ksqlDB позволяет создавать приложения потоковой передачи событий, используя понятийный инструментарий реляционных СУБД и следующие основные концепции [4]:
- коллекции (collections), которые делятся на потоки (streams) и таблицы (tables). Потоки — это неизменяемые последовательности событий, доступные только для добавления. Они полезны для представления ряда исторических фактов. Таблицы — это изменяемые коллекции событий. Они позволяют представлять последнюю версию каждого значения для каждого ключа.
- Потоковая обработка (Stream processing) позволяет выполнять непрерывные вычисления над неограниченными потоками событий: преобразование, фильтрация, агрегирование и соединение коллекций для получения новых коллекций или материализованных представлений, которые постепенно обновляются в режиме реального времени по мере поступления новых событий.
- Запросы (queries), которые могут быть 2-х видов – push и pull. Push-запросы позволяют подписаться на результат по мере его изменения в реальном времени. При поступлении новых событий push-запросы производят уточнения, чтобы быстро реагировать на новую информацию. Push-запросы идеально подходят для асинхронных потоков приложений. Pull-запросы позволяют получить текущее состояние материализованного представления, которые постепенно обновляются по мере поступления новых событий. Поэтому pull-запросы выполняются с предсказуемо низкой задержкой и отлично подходят для потоков типа «запрос/ответ» (request/response).
Каждый раз при запуске запроса, сервер ksqlDB компилирует его текстовое представление в физический план выполнения в виде топологии Kafka Streams. Топология постоянно работает как системная служба (демон), реагируя на новые строки, как только они становятся доступными. Вся обработка происходит на сервере ksqlDB, не затрагивая брокеры Apache Kafka. При добавлении серверов в кластер, ksqlDB автоматически распределяет рабочую нагрузку, разделяя работу и назначает ее серверам. Так каждый сервер выполняет только часть общей работы, повышая эффективность вычислений, вместо того, чтобы тратить ресурсы на переключение контекста. Параллелизм обеспечивается за счет разделов: каждый запрос читает строки как минимум из одного входного потока или таблицы. ksqlDB проверяет общее количество разделов этих входных данных, делит его на количество серверов и назначает каждому серверу его долю [4].
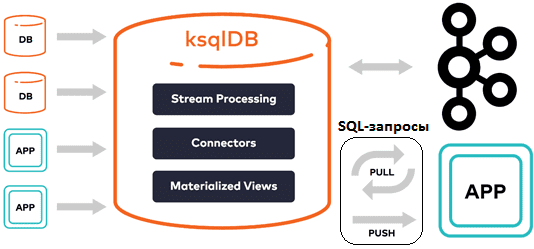
В заключение подчеркнем, что ksqlDB не является альтернативой СУБД и заменяет различные хранилища данных, этот инструмент Kafka-платформы полезен для асинхронной материализации представлений через SQL и интерактивных запросов к ним. Это не заменяет Postgres или MongoDB в качестве основной системы хранения, и не обладает широкими возможностями запросов аналитических хранилищ, таких как Elasticsearch, Druid или Snowflake. Тем не менее, это отличное средство для разработки приложений потоковой передачи событий, которые объединяют несколько систем, чтобы получить базовые возможности работать с аналитикой больших данных через удобные и привычные большинству ИТ-специалистов SQL-запросы.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Об основных достоинствах и недостатках ksqlDB, а также ее отличиях от Kafka Streams и KSQL читайте здесь и здесь. А о новинках релиза 0.22.0, который вышел в ноябре 2021 года, читайте в этой статье.
Источники