 985
985 
Содержание
Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker.
Коннекторы Kafka к реляционным БД от Confluent
О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной базой данных PostgreSQL, я уже писала здесь, и разбирала, как это работает, на практическом примере здесь. Коннектор, как постоянно работающий потребитель, в реальном времени отслеживает изменения в одной или нескольких таблицах БД, передавая их в топик Kafka. Так реализуется шаблон захвата измененных данных (CDC, Change Data Capture), позволяя выстраивать потоковые конвейеры синхронизации данных без пакетных обновлений и ресурсоемких полных сканирований.
Впорчем, CDC-коннектор Debezium не является единственным решением, которое позволяет интегрировать Kafka с PostgreSQL. Разработчик коммерческой экосистемы вокруг Kafka, компания Confluent, предлагает целых 2 коннектора, которые позволяют в реальном времени импортировать данные из реляционной БД в топик: Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium). Оба коннектора извлекают данные из реляционной базы и передают их в Kafka в виде событий, интегрированы с Confluent Platform и имеют интерфейс для настройки и управления параметрами подключения и топиками.
Однако, они принципиально отличаются принципами работы:
- метод извлечения данных. JDBC-коннектор использует SQL-запросы для извлечения данных, периодически опрашивая таблицы, чтобы получить изменения. Это может быть менее эффективно для больших объемов данных, т.к. требует выполнения полных запросов. CDC-коннектор Debezium читает WAL-журналы логической репликации для отслеживания изменений в реальном времени. Это более эффективно для обработки больших объемов данных, поскольку изменения обрабатываются в виде транзакций.
- поддержка изменений схемы. Изменения в структуре таблиц могут требовать дополнительных настроек или перезапуска JDBC-коннектора. CDC-коннектор Debezium лучше справляется с изменениями схемы, поскольку Debezium сам отслеживает их в реальном времени и автоматически адаптируется.
- сложность настройки. JDBC-коннектор настраивается намного проще и почти не требует изменений в конфигурации базы данных, что я и покажу в новой статье. CDC-коннектор Debezium требует настройку логической репликации на уровне базы данных и создания слота репликации, что я показывала здесь.
Таким образом, JDBC-коннектор подходит для случаев, когда объемы передаваемых в Kafka данных небольшие, нет жестких требований к обработке изменений в реальном времени, или когда источник, т.е. база данных, не поддерживает CDC. CDC-коннектор Debezium стоит выбирать, если нужно максимально сократить задержку передачи больших объемов данных в Kafka. Это решение подходит для высоконагруженных систем, где необходимо обрабатывать большие объемы данных и улавливать изменения в реальном времени.
Далее рассмотрим пример создания и настройки JDBC-коннектора к Apache Kafka, развернутой в Docker, на основании образа от Confluent. Пример конфигурационного YAML-файла docker-compose для набора сервисов в этом образе я приводила здесь.
Пример добавления JDBC-драйвера для коннектора и настройка YAML-файла docker-compose
Изначально в моем образе Kafka доступны только 3 коннектора, связанные с зеркальной репликацией (MirrorMaker). Это видно в GUI.
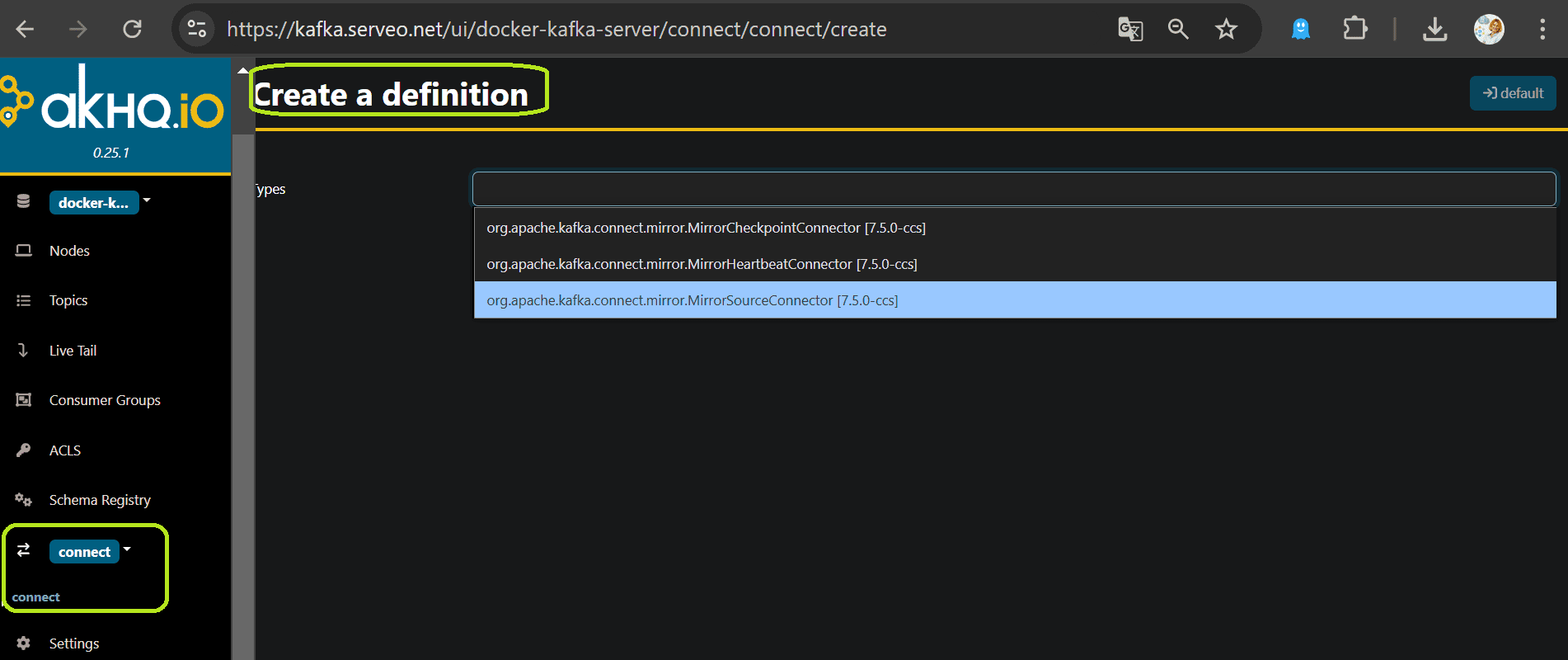
Чтобы добавить JDBC-коннектор, пришлось выполнить целый ряд действий:
- скачать архив с файлами JDBC-коннектора Source and Sink с официального хаба Confluent;
- внести изменения в конфигурационный YAML-файл docker-compose, добавив в раздел описания сервиса connect путь к драйверу в переменную CONNECT_PLUGIN_PATH и путь к папке с JAR-архивами коннектора;
- пересобрать и перезапустить контейнер, чтобы Kafka Connect нашел драйвер и использовал его.
В итоге мой конфигурационный YAML-файл docker-compose стал выглядеть так:
version: '3.6'
volumes:
zookeeper-data:
driver: local
zookeeper-log:
driver: local
kafka-data:
driver: local
services:
akhq:
# build:
# context: .
image: tchiotludo/akhq
restart: unless-stopped
environment:
AKHQ_CONFIGURATION: |
akhq:
connections:
docker-kafka-server:
properties:
bootstrap.servers: "kafka:9092"
schema-registry:
url: "http://schema-registry:8085"
connect:
- name: "connect"
url: "http://connect:8083"
ports:
- 8080:8080
links:
- kafka
- schema-registry
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
restart: unless-stopped
ports:
- 2181:2181
volumes:
- zookeeper-data:/var/lib/zookeeper/data:Z
- zookeeper-log:/var/lib/zookeeper/log:Z
environment:
ZOOKEEPER_CLIENT_PORT: '2181'
ZOOKEEPER_ADMIN_ENABLE_SERVER: 'false'
kafka:
image: confluentinc/cp-kafka:7.5.0
restart: unless-stopped
volumes:
- kafka-data:/var/lib/kafka/data:Z
environment:
KAFKA_BROKER_ID: '0'
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_NUM_PARTITIONS: '12'
KAFKA_COMPRESSION_TYPE: 'gzip'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: '1'
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: '1'
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: '1'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092,PLAINTEXT_EXT://serveo.net:39092'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT,PLAINTEXT_EXT:PLAINTEXT'
KAFKA_CONFLUENT_SUPPORT_METRICS_ENABLE: 'false'
KAFKA_JMX_PORT: '9091'
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
KAFKA_AUTHORIZER_CLASS_NAME: 'kafka.security.authorizer.AclAuthorizer'
KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: 'true'
ports:
- 39092:39092
links:
- zookeeper
schema-registry:
image: confluentinc/cp-schema-registry:7.5.0
restart: unless-stopped
depends_on:
- kafka
ports:
- "8085:8085"
environment:
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'PLAINTEXT://kafka:9092'
SCHEMA_REGISTRY_HOST_NAME: 'schema-registry'
SCHEMA_REGISTRY_LISTENERS: 'http://0.0.0.0:8085'
SCHEMA_REGISTRY_LOG4J_ROOT_LOGLEVEL: 'INFO'
SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_ORIGIN: '*'
SCHEMA_REGISTRY_ACCESS_CONTROL_ALLOW_METHODS: 'GET,POST,PUT,DELETE,OPTIONS'
connect:
image: confluentinc/cp-kafka-connect:7.5.0
restart: unless-stopped
depends_on:
- kafka
- schema-registry
ports:
- 8083:8083
environment:
CONNECT_BOOTSTRAP_SERVERS: 'kafka:9092'
CONNECT_REST_PORT: '8083'
CONNECT_REST_LISTENERS: 'http://0.0.0.0:8083'
CONNECT_REST_ADVERTISED_HOST_NAME: 'connect'
CONNECT_CONFIG_STORAGE_TOPIC: '__connect-config'
CONNECT_OFFSET_STORAGE_TOPIC: '__connect-offsets'
CONNECT_STATUS_STORAGE_TOPIC: '__connect-status'
CONNECT_GROUP_ID: 'kafka-connect'
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: 'true'
CONNECT_KEY_CONVERTER: 'io.confluent.connect.avro.AvroConverter'
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8085'
CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: 'true'
CONNECT_VALUE_CONVERTER: 'io.confluent.connect.avro.AvroConverter'
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8085'
CONNECT_INTERNAL_KEY_CONVERTER: 'org.apache.kafka.connect.json.JsonConverter'
CONNECT_INTERNAL_VALUE_CONVERTER: 'org.apache.kafka.connect.json.JsonConverter'
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: '1'
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: '1'
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: '1'
CONNECT_PLUGIN_PATH: '/usr/share/java,/etc/kafka-connect/jars'
volumes:
- ./jars:/etc/kafka-connect/jars
ksqldb:
image: confluentinc/cp-ksqldb-server:7.5.0
restart: unless-stopped
depends_on:
- kafka
- connect
- schema-registry
ports:
- 8088:8088
environment:
KSQL_BOOTSTRAP_SERVERS: 'kafka:9092'
KSQL_LISTENERS: 'http://0.0.0.0:8088'
KSQL_KSQL_SERVICE_ID: 'ksql'
KSQL_KSQL_SCHEMA_REGISTRY_URL: 'http://schema-registry:8085'
KSQL_KSQL_CONNECT_URL: 'http://connect:8083'
KSQL_KSQL_SINK_PARTITIONS: '1'
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_REPLICATION_FACTOR: '1'
test-data:
image: gradle:8-jdk11
command: "gradle --no-daemon testInjectData -x installFrontend -x assembleFrontend"
restart: unless-stopped
working_dir: /app
volumes:
- ./:/app:z
links:
- kafka
- schema-registry
kafkacat:
image: confluentinc/cp-kafkacat:7.1.14
restart: unless-stopped
depends_on:
- kafka
command:
- bash
- -c
- |
kafkacat -P -b kafka:9092 -t json << EOF
{"_id":"5c4b2b45ab234c86955f0802","index":0,"guid":"d3637b06-9940-4958-9f82-639001c14c34"}
{"_id":"5c4b2b459ffa9bb0c0c249e1","index":1,"guid":"08612fb5-40a7-45e5-9ff2-beb89a1b2835"}
{"_id":"5c4b2b4545d7cbc7bf8b6e3e","index":2,"guid":"4880280a-cf8b-4884-881e-7b64ebf2afd0"}
{"_id":"5c4b2b45dab381e6b3024c6d","index":3,"guid":"36d04c26-0dae-4a8e-a66e-bde9b3b6a745"}
{"_id":"5c4b2b45d1103ce30dfe1947","index":4,"guid":"14d53f2c-def3-406f-9dfb-c29963fdc37e"}
{"_id":"5c4b2b45d6d3b5c51d3dacb7","index":5,"guid":"a20cfc3a-934a-4b93-9a03-008ec651b5a4"}
EOF
kafkacat -P -b kafka:9092 -t csv << EOF
1,Sauncho,Attfield,sattfield0@netlog.com,Male,221.119.13.246
2,Luci,Harp,lharp1@wufoo.com,Female,161.14.184.150
3,Hanna,McQuillan,hmcquillan2@mozilla.com,Female,214.67.74.80
4,Melba,Lecky,mlecky3@uiuc.edu,Female,158.112.18.189
5,Mordecai,Hurdiss,mhurdiss4@rambler.ru,Male,175.123.45.143
EOF
kafkacat -b kafka:9092 -o beginning -G json-consumer json
links:
- kafka
В этом файле в раздел connect добавлена строка
volumes: - ./jars:/etc/kafka-connect/jars
Она нужна, чтобы смонтировать папку jars из текущей директории, где находится docker-compose.yml, внутрь контейнера по пути /etc/kafka-connect/jars. А переменная CONNECT_PLUGIN_PATH теперь также включает этот путь /etc/kafka-connect/jars, где будет находиться JDBC-драйвер.
Пересобрав контейнер с помощью инструкции
docker-compose up -d
можно увидеть успешную регистрацию драйвера в GUI.
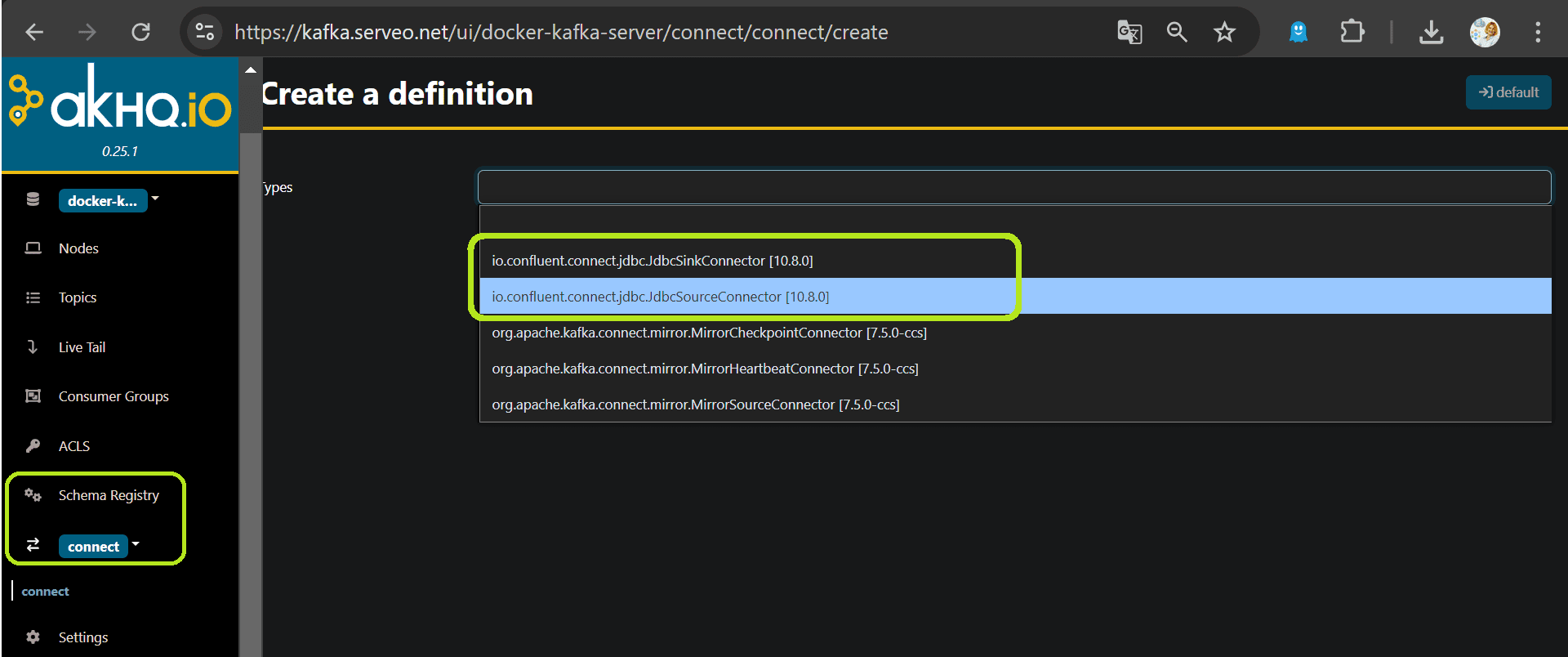
После этого можно создавать и настраивать JDBC-коннектор к PostgreSQL, о чем расскажу завтра.
Узнайте больше про администрирование и эксплуатацию Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Apache Kafka в Kubernetes
Источники
- https://docs.confluent.io/kafka-connectors/jdbc/current/source-connector/overview/
- https://www.confluent.io/blog/cdc-and-data-streaming-capture-database-changes-in-real-time-with-debezium/
- https://docs.confluent.io/cloud/current/connectors/cc-postgresql-cdc-source-v2-debezium/cc-postgresql-cdc-source-v2-debezium/

