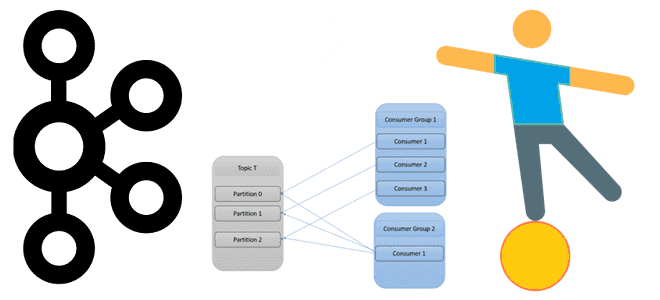
Для параллельной обработки сообщений из своих топиков Kafka использует механизм группы приложений-потребителей, о чем мы писали здесь. Читайте далее, что происходит при изменении состава группы потребителей, чем опасна частая перебалансировка и как ее избежать.
Что такое перебалансировка потребителей и почему она случается?
Выполняя роль интеграционного звена между приложениями-продюсерами и приложениями-потребителями данных в режиме реального времени, Apache Kafka имеет множество внутренних механизмов обеспечения отказоустойчивости. Одним из них является перебалансировка, которая возникает, когда приложение-потребитель теряет связь с брокером и координатором группы потребителей в кластере Kafka. Например, потребитель некорректно отписался от топика или давно не опрашивал его. Также перебалансировку может вызвать сбой на стороне потребителя или проблема с сетью, которая привела к задержке обмена heartbeat-сигналами между потребителем и кластером, превышающая настроенное время ожидания сеанса. Такое часто бывает при перезапуске одного или нескольких экземпляров, масштабировании кластера или программно-аппаратном отказе. Напомним, топик Kafka может иметь несколько разделов, каждый из которых назначается только одному приложению-потребителю из группы. Пример того, как это работает, мы рассматривали здесь. Важно отметить, что перебалансировка происходит не только, когда потребитель покидает группу, но и при добавлении нового потребителя в группу.
В любом случае, когда потребитель не может подключиться к кластеру, координатор группы потребителей удаляет его из группы, запуская перебалансировку. Это означает, что оставшиеся потребители будут освобождены от своих разделов, а координатор группы перераспределит разделы топика среди них заново. Пока перебалансировка не завершится, приложения-потребители не смогут считывать данные из Kafka.
Перебалансировки не влияет на приложения-продюсеры, которые по-прежнему продолжают отправлять сообщения в топик. Как только разделы топика будут перераспределены, приложения-потребители возобновят работу со смещения, с которого они остановились, в каждом из назначенных им разделов. Для вновь назначенного раздела потребитель будет использовать последнее зафиксированное смещение от исключенного потребителя. Подробнее про управление смещениями потребителя читайте в нашей новой статье.
К чему приводит перебалансировка потребителей Apache Kafka и что можно сделать
При перебалансировке Kafka, важно убедиться, что нагрузка на все приложения-потребители распределена одинаково. Хотя процесс перебалансировки занимает немного времени (от нескольких секунд до минуты), все потребители на этот период приостанавливают обработку данных. Это похоже на полную сборку мусора при очистке памяти в JVM с помощью Garbage Collector. При том, что этот механизм нужен для повышения производительности приложения, частый запуск полной сборки мусора замедляет работу JVM. Аналогично и в Kafka: производительность потоковой обработки данных снижается при частой перебалансировке потребителей. А приложения-продюсеры продолжают отправлять данные в топик, что приводит к отставанию фактического времени события, произошедшего в реальном мире, и временем его обработки приложением-потребителем.
Продолжительность процесса перебалансировки зависит от количества разделов. В этот период каждый потребитель, который поддерживает связь с координатором группы, должен отозвать, а затем восстановить свои разделы. Чем их больше, тем больше времени на это понадобится.
Чтобы снизить негативное влияние перебалансировки на производительность системы потоковой передачи событий, можно попытаться сократить количество запусков этого процесса. В частности, если перебалансировка Kafka происходит из-за нестабильной рабочей нагрузки, поможет эластичное масштабирование кластера для поддержания оптимального количества экземпляров. В случаев контейнеризованных приложений можно настроить ограничения памяти, чтобы избежать перезапусков контейнера при ее нехватке. Также можно увеличить память контейнера или перейти к развертыванию на основе виртуальной машины.
Другой мерой является использование членства в статической группе Kafka, доступное с версии 2.3. Это параметр group.instance.id, уникальный для каждого потребителя в группе. Этот идентификатор используется при определении жизнеспособности потребителя, который долго не выходил на связь с координатором группы.
Если недоступность потребителя превысила время ожидания сеанса, которое должно быть большим при использовании статического идентификатора группы, то использование назначенных разделов приостанавливается. Но если потребитель снова подключился до истечения времени ожидания сеанса с тем же статическим идентификатором, потребление просто возобновляется. О разнице статического и динамического членства в группе потребителей читайте в нашей новой статье.
Вместо этого, начиная с версии Apache Kafka 2.4, можно включить протокол постепенной совместной перебалансировки вместо стандартного протокола для постепенного перераспределения разделов между доступными потребителями. При этом по истечении тайм-аута сеанса потребителя, отзываются только его разделы, а не все разделы у всех остальных потребителей этого топика. Затем лидер группы потребителей постепенно назначает отозванные разделы оставшимся приложениям, позволяя им продолжать считывание данных из Kafka. Это очень полезно, если теряется лишь небольшое количество потребителей по отношению к общему размеру группы, поскольку чем больше потерянных потребителей, тем дольше прерывается обслуживание оставшихся приложений.
Наконец, можно настроить параметры тайм-аута Kafka:
- poll.records — размер пакета, количество записей, которое потребитель может считывать за раз, вызывая метод опроса poll(). По умолчанию это значение равно 500. Это значение не влияет на основное поведение выборки: потребитель кэширует записи из каждого запроса на выборку и постепенно возвращает их из каждого опроса.
- poll.interval.ms — период ожидания в миллисекундах, чтобы потребитель завершил обработку полученного пакета сообщений, размер которого задан конфигурацией max.poll.records. По умолчанию значение max.poll.records равно 5 минут (300 секунд). Это максимальная задержка между вызовами poll() при использовании управления группами потребителей. Она устанавливает верхнюю границу количества времени, в течение которого потребитель может бездействовать, прежде чем получить больше записей. Если poll() не вызывается до истечения этого тайм-аута, потребитель считается потеряным, и группа выполняет перебалансировку, чтобы переназначить его разделы другому члену. Как уже было отмечено ранее, для потребителей с ненулевым group.instance.id, которые достигли этого тайм-аута, разделы не будут переназначены немедленно. Вместо этого потребитель перестанет отправлять тактовые импульсы (heartbeat-сигналы), а его разделы будут переназначены по истечении периода, определенного в session.timeout.ms. Это отражает поведение статического потребителя, который отключился.
Если max.poll.records задано 500, а max.poll.interval.ms равно 300 секунд, то обработка каждого сообщения может занимать до 0,6 секунд, когда потребитель получает полную рабочую нагрузку в 500 записей. Эти значения можно настроить статически или менять их динамически, в зависимости от нагрузки. Пример настройки этих и других конфигураций для эффективной перебалансировки мы рассматривали здесь.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники