Чем политика сброса смещения earliest отличается от latest в конфигурации auto.offset.reset, зачем устанавливать свойству enable.auto.commit значение false и чем потребитель Java отличается от клиентов на основе librdkafka (C/C++, Python, Go и C#).
Конфигурации Apache Kafka для управления смещением
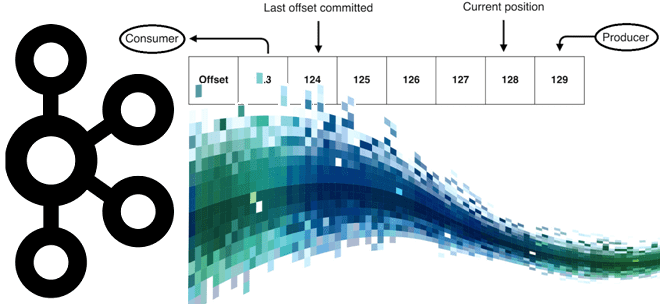
Потребитель Apache Kafka — это клиентское приложение, которое подписывается на весь топик или его отдельный раздел, чтобы считывать события, публикуемые туда приложением-продюсером. Потребление сообщений реализуется в цикле опроса, когда потребитель отправляет брокерам Kafka запросы на выборку к лидерам разделов с данными. Смещение потребителя указывается в логе при каждом запросе и сообщается потребителю, который контролирует эту позицию и может изменить ее для повторного считывания данных.
Стратегия управления смещением в потребителе Kafka определяется двумя конфигурациями:
- auto.commit – автоматическая фиксация, по умолчанию true;
- offset.reset– политика сброса смещения.
По умолчанию, когда потребитель читает сообщения из Kafka, он периодически фиксирует свое текущее смещение для разделов, из которых он читает, обратно в Kafka. Потребитель автоматически фиксирует смещения периодически с интервалом, заданным в конфигурации auto.commit.interval.ms (по умолчанию 5 секунд). Если нужно больше контроля над тем, когда именно будут зафиксированы смещения, можно установить у потребителя значение false для конфигурации enable.auto.commit и вызвать метод commit().
Политика сброса смещения auto.offset.reset определяет поведение потребителя, когда нет зафиксированной позиции, например, при первой инициализации группы потребителей или когда смещение выходит за пределы диапазона. Kafka поддерживает три политики смещения, задаваемые в значении конфигурации потребителя auto.offset.reset :
- самое раннее (earliest), когда приложению-потребителю необходимо получить все имеющиеся в топике сообщения с самого начала;
- последнее (latest), когда приложению-потребителю не нужно получать все сообщения с самого начала, а достаточно считать только данные, поступившие в топик после того момента, как потребитель на него подписался. Или же из последнего зафиксированного смещения, когда потребитель повторно присоединился к кластеру Kafka, например, после восстановления после сбоя.
- не задано (none), когда надо устанавливать начальное смещение самостоятельно и обрабатывать ошибки выхода за пределы диапазона вручную.
Пример настройки Python-потребителя
Например, у меня следующий Python-код устанавливает значение конфигурации auto_offset_reset на latest, т.е. чтение с последнего доступного смещения. А enable_auto_commit, установленное в True означает автоматическую фиксацию смещения.
consumer = KafkaConsumer( bootstrap_servers=[адрес_вашего_сервера:9092'], sasl_mechanism='SCRAM-SHA-256', security_protocol='SASL_SSL', sasl_plain_username='имя_вашего_пользователя', sasl_plain_password='пароль_этого_пользователя', group_id='1', auto_offset_reset='earliest', enable_auto_commit=True )
В этом коде определяется потребитель Kafka как объект класса KafkaConsumer из библиотеки kafka-python, ранее установленной через менеджер пакетов pip:
!pip install kafka-python from kafka import KafkaConsumer
Примечательно, что клиенты на основе librdkafka (C/C++, Python, Go и C#) используют фоновый поток, тогда как потребитель, написанный на языке Java выполняет все операции ввода-вывода и обработку в потоке переднего плана (foreground threads), который предохраняет приложение от завершения. Поэтому в фоновом режиме опрос абсолютно безопасен при использовании нескольких потоков. Можно использовать это для распараллеливания обработки сообщений в нескольких потоках.
Опрос удаляет сообщения из очереди, которая заполняется в фоновом режиме. Аналогично все контрольные сигналы и перебалансировка выполняются в фоновом режиме. Таким образом, разработчику не нужно беспокоиться об обработке сообщений, из-за которой потребитель пропустит перебалансировку, т.е. переназначение разделов в группе потребителей. Подобнее про группы потребителей в Apache Kafka мы писали здесь, а про перебалансировку потребителей в группе — здесь.
Недостатком фонового потока является то, что он продолжает работать, даже если продюсер выйдет из строя. Если это произойдет, то потребитель продолжит удерживать разделы, на которые он назначен, и задержка чтения будет продолжать увеличиваться до тех пор, пока процесс не будет остановлен.
Чтобы обеспечить подобную абстракцию в клиенте Java, можно поместить очередь между циклом опроса и процессорами сообщений. Цикл опроса заполнит очередь, и процессоры будут извлекать из нее сообщения.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

