Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума.
Роль HFile в Apache HBase
Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок» использует HDFS в качестве базового хранилища данных. При этом HBase отлично решает задачи произвольного доступа к данным для их чтения и записи в реальном времени, тогда как исторически Hadoop является последовательной системой пакетной обработки. Изначально Hadoop использовал строковый формат SequenceFile, который дает возможность добавлять пары ключ/значение, не позволяя HDFS изменять или удалять данные. Единственной разрешенной операцией с данными было их добавление, и для поиска конкретного ключа требовалось прочитать файл.
Чтобы реализовать систему случайного доступа к данным с малой задержкой как HBase, в Hadoop используется другой файловый формат под названием MapFile. А с версии HBase 0.20 это расширение SequenceFile стало известно как HFile. По сути, этот формат представляет собой каталог, содержащий два файла SequenceFile: файл данных «/data» и файл индекса «/index». Это позволяет добавлять отсортированные пары ключ/значение, сохраняя ключ и смещение в индексе через каждые N ключей (где N — настраиваемый интервал). Так реализуется быстрый поиск, поскольку вместо сканирования всех записей достаточно просмотреть индекс, который намного меньшею После того, как блок данных найден, можно перейти к реальному файлу данных.
Ключ HBase состоит из ключа строки, семейства столбцов, квалификатора столбца, метки времени и типа, который позволяет пометить ключ как удаленный (tombstone), чтобы решить проблему удаления пар ключ/значение. Так можно выбрать более позднюю метку времени, поскольку искомое значение находится ближе к концу файла, т.к. добавление данных выполняется по принципу FIFO (First In First Out) и последнее вставленное значение находится ближе к концу.
Чтобы решить проблему неупорядоченных» ключей, последние добавленные ключи-значения сперва хранятся в памяти, а по достижении определенного порога HBase переносит их на диск в виде HFile, добавляя отсортированные ключи/значения.
Эволюция HFile: фильтр Блума и не только
Как уже было отмечено ранее, в версии HBase 0.20 MapFile был заменен на HFile, который поддерживает больше возможностей, чем просто ключи и значения. В частности, метаданные и индексы хранятся в одном файле. И структура HFile выглядит следующим образом:
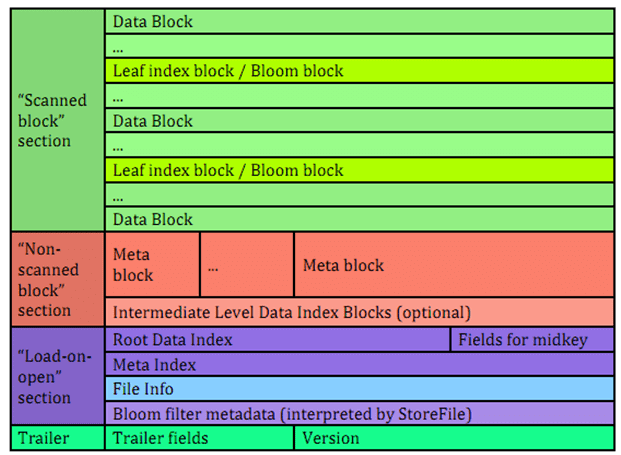
В этой структуре HFile есть следующие блоки:
- DATA – блоки данных;
- LEAF_INDEX – блоки индекса листового уровня в многоуровневом блочном индексе;
- BLOOM_CHUNK – фрагменты фильтра Блума – компактной вероятностной структуры данных, используемой для быстрого поиска и позволяющей снизить количество обращений к жесткому диску при проверке на существование заданной строки или столбца в таблице базы данных. Подробнее про фильтр Блума и его практическое использование мы писали здесь и здесь.
- META – метаблоки, которые не используются для фильтров Блума в HFile версии 2;
- INTERMEDIATE_INDEX – индексные блоки промежуточного уровня в многоуровневом блочном индексе;
- ROOT_INDEX – блоки индекса корневого уровня в многоуровневом блочном индексе;
- FILE_INFO – блок «информация о файле», небольшая key-value карта метаданных;
- BLOOM_META – блок метаданных фильтра Блума в разделе загрузки при открытии (Load-on-open);
- TRAILER – структура данных фиксированного размера, специфичная для каждой версии HFile;
Сжатый размер данных блока, не включая заголовок может использоваться для пропуска текущего блока данных при сканировании данных HFile. А несжатый размер данных блока, не включая заголовок равен сжатому, если алгоритм сжатия не задан, т.е. равен NONE. Смещение файла предыдущего блока того же типа может использоваться для поиска предыдущего блока данных/индекса. Раздел сканирования (Scanned block section) содержит все блоки данных, которые необходимо прочитать при последовательном сканировании HFile, а также индекс блока листа и блок фильтра Блума. Раздел Non-scanned block section не читается при последовательном сканировании.
В HBase 0.92 формат HFile был немного изменен, чтобы повысить производительность при хранении больших объемов данных. Одна из основных проблем с HFile была в необходимости грузить все монолитные индексы и большие фильтры Блума в память. В реальности фильтры Блума в одном HFile могли достигать 100 МБ, что составляет до 2 ГБ при агрегировании более 20 регионов Apache HBase. Совокупный размер блочных индексов мог достигать 6 ГБ в одном и том же наборе регионов. Поскольку в HBase регион не считается открытым, пока не будут загружены все данные его блочного индекса, большие фильтры Блума создавали проблемы с производительностью: первый запрос на получение данных, требующий поиска с фильтром Блума, вызывал задержку загрузки всего его битового массива в память.
Чтобы ускорить запуск регионального сервера, фильтры Блума и блочные индексы разбиты на несколько блоков, которые записываются по мере их заполнения, что также уменьшает объем памяти, занимаемый модулем записи HFile. В случае фильтра Блума заполнение блока означает накопление достаточного количества ключей для эффективного использования битового массива фиксированного размера. А для индекса идет накопление блока желаемого размера. Блоки фильтров Блума и индексные блоки перемежаются с блоками данных, что не позволяет полагаться на разницу между смещениями блоков для определения длины блока данных, как это было в 1-ой версии HFile.
Благодаря тому, что HFile версии 2 имеет многоуровневые индексы и фильтр Блума на уровне блоков, этот низкоуровневый файловый формат отличается улучшенной скоростью, низким потреблением памяти и использованием кэша. Теперь вместо того, чтобы иметь в памяти весь индекс и фильтр Блума всего HFile-файла, достаточно хранить в оперативной памяти только то, что нужно благодаря разделению индекса и фильтра Блума.
В планируемой к реализации 3-ей версии HFile для улучшения сжатия предлагается группировка всех ключи в начале блока и всех значения в конце блока, чтобы использовать для них разные алгоритмы. Также предлагается изменение алгоритма сжатия временных меток и использование идей колоночных форматов и кодирование столбцов.
В заключение отметим, что глубокие знания структуры данных на уровне файловых форматов могут пригодиться для оптимизации хранения информации. Зная, что содержит файл, можно улучшить сжатие данных и/или использовать более подходящие алгоритмы их обработки, чтобы сократить число операций записи и чтения с диска, повышая общую скорость работы Apache HBase.
Узнайте больше подробностей про администрирование и эксплуатацию Apache HBase и других компонентов экосистемы Hadoop для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

