 1160
1160 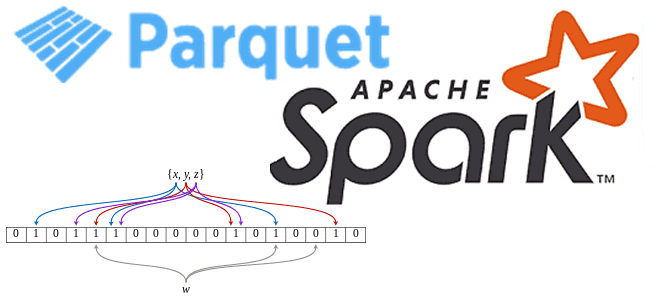
Сегодня рассмотрим, что такое фильтр Блума и как эта структура данных используется в Apache Spark для чтения Parquet-файлов. Про хеширование, UUID, достоинства и недостатки Bloom-фильтра для бинарного колоночного формата хранения больших данных в распределенных системах.
Что такое фильтр Блума
Фильтр Блума активно используется во многих информационных системах для быстрого поиска данных. В частности, Google BigTable применяет фильтры Блума, чтобы снизить количество обращений к жесткому диску при проверке на существование заданной строки или столбца в таблице базы данных. Чаще всего Bloom-фильтр используется для уменьшения числа запросов к несуществующим элементам в структуре данных с дорогими read-операциями, например, доступ к данным на жестком диске или к сетевому хранилищу.
Эта компактная вероятностная структура, придуманная Бёртоном Блумом в 1970 году, позволяет проверять принадлежность элемента к множеству. Вероятностный характер фильтра проявляется в возможности получить ложноположительный результат, когда в реальности искомого элемента в исходном множестве нет, но структура данных сообщает о его наличии. Однако, ложноотрицательных результатов фильтр не выдает.
К примеру, при регистрации в веб-сервисе необходимо задать имя пользователя (логин), который должен быть уникальным. Список всех зарегистрированных имен пользователей составляет собой множество, среди которого необходимо обнаружить введенные новым пользователем данные. Ложноположительный результат означает, что введенное пользователя имя уже существует, хотя на самом деле это не так.
Эта структура данных может использовать любой заранее заданный объём памяти. Вероятность получить ложноположительный результат обратно пропорциональна объему памяти. По умолчанию фильтр Блума позволяет добавлять новые элементы в множество, но не удалять существующие.
Фильтр Блума тесно связан с хеш-функцией, которая преобразует входные данные в выходную битовую строку согласно используемому алгоритму. К примеру, пароли не сохраняются в чистом виде, а записываются в виде хеш-кода. Хеш-функция принимает входные данные и выводит уникальные выходные данные фиксированной длины для идентификации ввода. Чаще всего между хеш-кодом и исходными данными нет однозначного соответствия: результаты хеширования менее разнообразны, чем исходный массив.
В отличие от стандартной хеш-таблицы, фильтр Блума фиксированного размера может представлять набор с произвольно большим количеством элементов и требует меньшего объема памяти. Обратной стороной этого достоинства является вероятностный характер, т.е. возможность ложноположительных срабатываний. Пустой фильтр Блума — это битовый массив из m битов, все установлены в ноль. Частота ложных срабатываний увеличивается по мере добавления элементов до тех пор, пока все биты в фильтре не будут установлены в 1, после чего все запросы будут давать истинно положительный результат. Удаление элементов из фильтра Блума невозможно, т.к. очистка битов в индексах, сгенерированных отдельными хеш-функциями может вызвать удаление других элементов. Операцию удаления поддерживает модификация Bloom-фильтра со счётчиками.
Как фильтр Блума применяется в Parquet-файлах и каким образом работать с ним в Apache Spark, мы рассмотрим далее. А пока отметим, что эта вероятностная структура данных применяется для индексации во многих форматах, помимо Parquet, например, CarbonData тоже ее использует. Подробнее об этом читайте здесь.
Зачем использовать Bloom-фильтр в Parquet-файлах с Apache Spark
Напомним, бинарный колоночный формат Apache Parquet широко используется в области Big Data благодаря хранению данных по столбцам и эффективному сжатию. Он позволяет быстро считать нужные данные из конкретного столбца вместо чтения полной строки, что экономит время. API Apache Spark включает методы работы с Parquet-файлами, позволяя читать данные из них в датафрейм и наоборот, записывать датафрейм в файл формата Parquet.
Поскольку фильтр Блума позволяет быстро определить принадлежность элемента множеству, то в колоночных Parquet-файлах он пригодится, чтобы Spark-приложение загружало определенные группы строк в память или нет. Это особенно полезно при фильтрации по столбцу, который имеет много неупорядоченных уникальных значений, таких как UUID, поскольку здесь нельзя использовать статистику с минимальным и максимальным значениями для фильтрации данных, не входящих в диапазон. Напомним, универсальный уникальный идентификатор позволяет распределённым системам уникально идентифицировать информацию без центра координации. Можно создать UUID (universally unique identifier) и использовать его для идентификации объекта, будучи уверенным, что этот UUID больше нигде не повторится. Объекты с UUID, могут быть помещены в общую базу данных без конфликта имен.
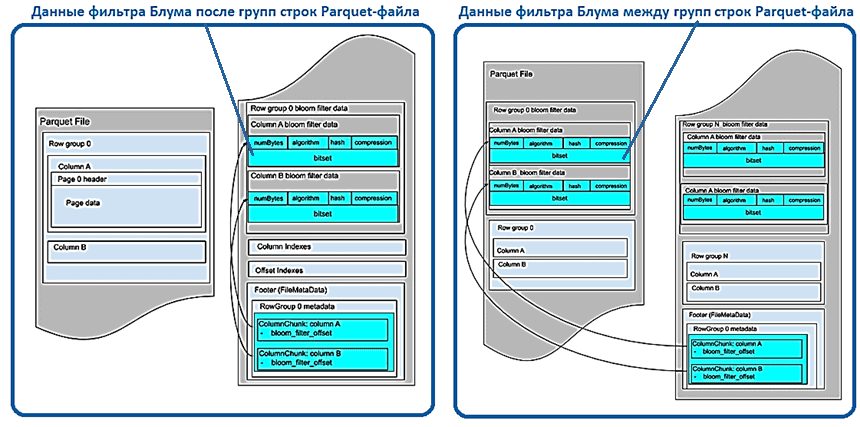
Для столбцов с конфиденциальными данными фильтр Блума должен быть зашифрован ключом столбца. В Parquet-файле фильтры Блума имеют два сериализуемых модуля:
- экономичную структуру PageHeader с ее внутренними полями, включая заголовок страницы Блум-фильтра (bloom_filter_page_header);
- набор битов Bitset.
Структура заголовка сериализуется Thrift и записывается в выходной поток файла, а далее следует сериализованный битовый набор. Для фильтров Блума в столбцах с конфиденциальными данными каждый из двух модулей будет зашифрован после сериализации, а затем записан в файл. Шифрование будет выполняться с использованием шифра AES GCM с тем же ключом столбца, но с разными типами модулей AAD: заголовок Bloom-фильтра и набор битов Bloom-фильтра. Длина зашифрованного буфера записывается перед буфером, как описано в спецификации шифрования Parquet.
Фильтры Блума сгруппированы по группам строк и содержат данные для каждого столбца в том же порядке, что и схема файла. Данные фильтра Блума могут храниться до индексации страниц после всех групп строк или между ними.
Возвращаясь к использованию фильтров Блума в Spark-приложениях, отметим, что он позволяет загружать в память меньший набор данных, например, 1 МБ – максимальное количество байтов по умолчанию для битового набора Bloom-фильтра. Это полезно, когда нужно проверить, принадлежит ли отфильтрованный UUID набору данных или нет, прежде чем он загружать весь датасет. Если отфильтрованный UUID не принадлежит набору данных, Spark не загрузит остальную часть набора данных. Таким образом, фильтр Блума может ускорить поиск данных в столбцах, который содержит несортированные уникальные значения. Однако добавление этой структуры данных будет занимать дополнительное место в Parquet-файле. Как фильтр Блума используется в LSM-деревьях, активно применяемых в механизмах записи и чтения данных в NoSQL-базах, читайте в нашей новой статье. А о том, как большой объем фильтра Блума стал причиной изменения версии Hfile, используемого в Apache HBase, вы узнаете здесь.
Больше подробностей эксплуатации Apache Spark для разработки распределенных приложений и аналитики больших данных вам помогут узнать специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

