В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд.
Интеграция Greenplum и Hadoop через PXF-коннекторы
Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который позволяет интегрировать Greenplum с другими системами, обеспечивая параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. PXF включает в себя набор встроенных коннекторов, которые сопоставляют определение внешней таблицы Greenplum с внешним источником данных, позволяя не загружать большие датасеты в MPP-СУБД. Подробно об этом читайте в нашей прошлой статье.
PXF совместим с открытыми и коммерческими дистрибутивами Apache Hadoop: Cloudera, Hortonworks Data Platform, MapR и Arenadata. Фреймворк устанавливается с коннекторами HDFS, Hive и HBase, которые используются для доступа к различным форматам данных из экосистемы Hadoop.
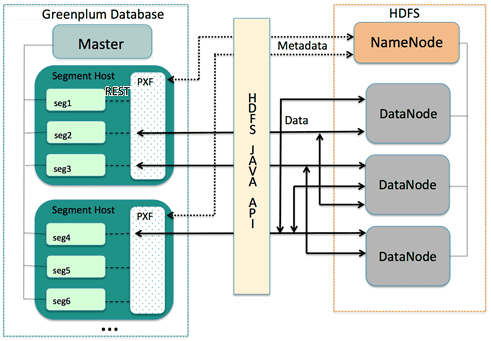
Рассмотрим, как считать данные в Greenplum из распределенной файловой системы HDFS, которая является основным механизмом хранения данных Apache Hadoop. Когда пользователь или приложение выполняет запрос к внешней таблице PXF, которая ссылается на файл HDFS, главный хост базы данных Greenplum отправляет запрос всем экземплярам сегмента. Каждый экземпляр сегмента связывается со службой PXF, работающей на его хосте. При получении запроса от экземпляра сегмента сервис PXF выделяет рабочий поток для обслуживания запроса из экземпляра сегмента и вызывает Java API HDFS для запроса метаданных файла HDFS из распределенной файловой системы главного узла с пространством имен кластера (NameNode).
Рабочий поток PXF работает от имени экземпляра сегмента, используя свой gp_segment_id базы данных Greenplum и информацию о файловом блоке, описанную в метаданных, чтобы назначить себе определенную часть данных запроса. Эти данные могут находиться на одном или нескольких узлах данных HDFS (DataNode).
Рабочий поток PXF вызывает Java API HDFS для чтения данных и доставки их экземпляру сегмента. Экземпляр сегмента доставляет свою часть данных на главный хост базы данных Greenplum. Это взаимодействие происходит между хостами сегмента и его экземплярами параллельно.
Прежде чем работать с данными Hadoop с помощью PXF, следует настроить PXF и запустить его на каждом хосте Greenplum. Также необходимо настроить PXF-коннекторы Hadoop, скопировав файлы конфигурации Hadoop в каталог конфигурации сервера на главном хосте Greenplum и определив параметры безопасного протокола Kerberos и пользователя для доступа к данным. При этом следует убедиться в наличии разрешения на чтение и запись файлов и каталогов HDFS, которые будут доступны как внешние таблицы в базе данных Greenplum для каждого имени пользователя или роли базы данных Greenplum. При передаче данных время синхронизируется между хостами Greenplum и внешними системами Hadoop.
Примеры команд
Рассмотрим, как считать данные в Greenplum из файлов HDFS. По умолчанию установка Hadoop включает инструменты командной строки, которые напрямую взаимодействуют с файловой системой HDFS. Эти инструменты поддерживают типичные операции с файловой системой, включая копирование и просмотр файлов, изменение прав доступа к файлам и пр. Однако, изначально хосты Greenplum не включают установку клиента Hadoop, поэтому об этом следует позаботиться заранее.
Типовой синтаксис команды HDFS выглядит так: hdfs dfs <options> [<file>]. Вызванный без параметров, hdfs dfs перечисляет параметры файловой системы, поддерживаемые инструментом. Пользователь, вызывающий команду hdfs dfs, должен иметь права на чтение хранилища данных HDFS для вывода списка и просмотра содержимого каталогов и файлов, а также права на запись для создания каталогов и файлов. В качестве параметров для команды hdfs dfs, которые пригодятся для PXF-коннекторов Hadoop, используются следующие:
- -cat — показать содержимое файла;
- -mkdir — создать каталог в HDFS;
- -put — скопировать файл из локальной файловой системы в HDFS.
Например, создать каталог в HDFS: $ hdfs dfs —mkdir —p /data/exampledir
Скопировать текстовый файл из локальной файловой системы в HDFS:
$ hdfs dfs -put /tmp/example.txt /data/exampledir/
Отобразить содержимое текстового файла, расположенного в HDFS:
$ hdfs dfs -cat /data/exampledir/example.txt
PXF-коннекторы Hadoop предоставляют встроенные профили для поддержки следующих форматов данных: Text, CSV, AVRO, JSON, ORC, Parquet, RCFile, SequenceFile, AvroSequenceFile. PXF предоставляет более одного профиля для доступа к текстовым данным и данным Parquet в Hadoop. Выбор профиля зависит от типа и расположения исходных данных в Hadoop. При этом желательно учитывать следующие рекомендации:
- Hive-профиль подойдет, когда данные находятся в таблице Hive, а базовый тип файла таблицы заранее неизвестен или эта таблица Hive партиционирована;
- профили hdfs:text и hdfs:csv подойдут для текстовых файлов с известным расположением в HDFS;
- при доступе к данным в формате ORC следует выбрать профиль hdfs:orc, если известно расположение ORC-файла в HDFS и файл не управляется Hive или не требуется использовать хранилище метаданных Hive;
- профиль hive:orc следует выбирать для ORC-таблиц, управляемых Hive с партиционированными или сложными типами данных;
- для Parquet-файлов с известным расположением в HDFS подойдет профиль hdfs:parquet. Дополнительным преимуществом этого профиля является возможность использовать расширенную поддержку фильтра для дополнительных типов данных и операторов.
Необходимо указать имя профиля при указании pxf- протокол в команде CREATE EXTERNAL TABLE для создания внешней таблицы Greenplum, которая ссылается на файл или каталог Hadoop, таблицу HBase или таблицу Hive. Например, следующая команда создает внешнюю таблицу, которая использует сервер по умолчанию и указывает профиль с именем hdfs:text для доступа к файлу HDFS:
/data/pxf_examples/pxf_hdfs_simple.txt:
CREATE EXTERNAL TABLE pxf_hdfs_text(location text, month text, num_orders int, total_sales float8)
LOCATION ('pxf://data/pxf_examples/pxf_hdfs_simple.txt?PROFILE=hdfs:text')
FORMAT 'TEXT' (delimiter=E',');
Освойте администрирование и эксплуатацию Greenplum и Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Greenplum для инженеров данных
- Greenplum для инженеров данных
- Администрирование Greenplum / Arenadata DB
- Интеграция Hadoop и NoSQL
Источники