 1008
1008 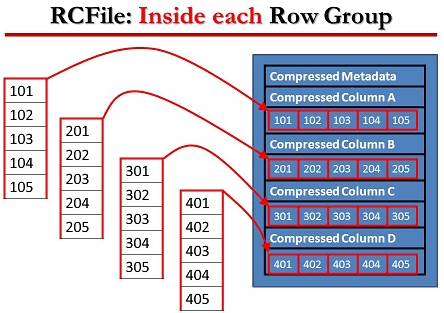
Содержание
RCFile (Record Columnar File) – гибридный многоколонный формат записей, адаптированный для хранения реляционных таблиц на кластерах и предназначенный для систем Big Data, использующих MapReduce. Этот формат для записи больших данных появился в 2011 году на основании исследований и совместных усилий Facebook, Государственного университета Огайо и Института вычислительной техники Китайской академии наук [1].
Как устроен RCFile: структура, достоинства и недостатки
Структура RCFile включает в себя формат хранения данных, методы сжатия и оптимизации чтения информации. Он способен удовлетворить все четыре требования к размещению данных [1]:
- быстрая загрузка данных;
- оперативная обработка запросов;
- эффективное использование дискового пространства хранения;
- высокая адаптивность к динамическим шаблонам доступа к данным.
В формате RCFile данные сперва разделены на группы строк, внутри которых информация хранится в колоночном виде. Благодаря горизонтально-вертикальному разделению RCFile сочетает в себе преимущества хранения строк и хранения столбцов. При горизонтальном разбиении RCFile размещает все столбцы строки на одном компьютере, исключая дополнительные сетевые нагрузки при построении строки. При вертикальном разбиении для запроса RCFile считывает только необходимые столбцы с дисков, устраняя ненужные затраты на локальный ввод-вывод. Также в каждой группе строк сжатие данных может выполняться с использованием алгоритмов, используемых в хранилище столбцов [1].
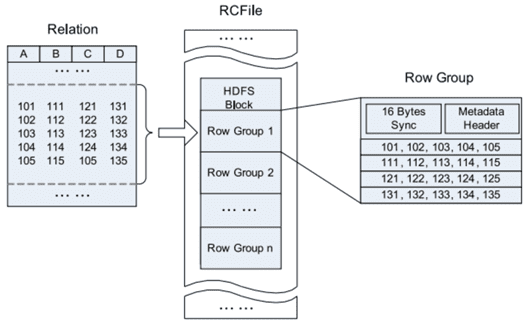
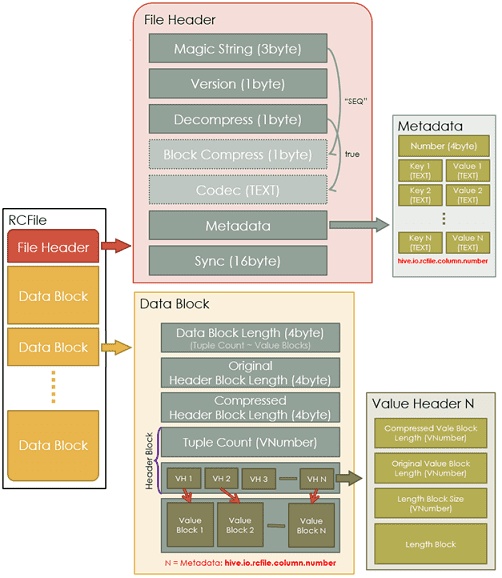
В RCFile столбцы таблиц записываются друг за другом смежными блоками и сжимаются индивидуально с помощью кодека Zlib / LZO, снабжаясь описанием в виде метаданных. Это позволяет выборочно распаковывать данные в случае чтения. В итоге при выполнении запроса пропускаются долгие этапы декомпрессии и десериализации ненужных столбцов [2].
Таким образом, как и в других колоночно-ориентированных форматах Big Data, Parquet и ORC, колоночный вид представления и хранения данных дает следующие преимущества [3]:
- эффективное сжатие данных;
- высокая скорость чтения за счет пропусков ненужных столбцов.
Аналогично Parquet и ORC, колоночно-ориентированная архитектура формата Record Columnar File обусловливает недостатки этого формата файлов Big Data [3]:
- повышенное потребление памяти, т.к. чтобы получить столбец из нескольких строк, кэшируется вся строка;
- не очень подходит для потоковой записи, т.к. в случае сбоя текущий файл не сможет быть восстановлен, в отличие, например, от линейно-ориентированных форматов (SequenceFile, MapFile, Avro), где данные могут быть повторно синхронизированы с последней точки синхронизации.
Где и зачем используется формат Record Columnar File для Big Data файлов
Формат Record Columnar File принят в СУБД Apache Hive (начиная с версии 0.4), Apache Pig (начиная с версии 0.7) и стал стандартом де-факто для хранения данных в Apache HCatalog – службе управления таблицами и хранилищами Hadoop. Благодаря своим достоинствам формат RCFile широко применяется в реальных системах анализа больших данных. В частности, в производственном кластере Hadoop соцсети Facebook и в Twitter для ежедневной аналитики данных в рамках библиотеки Elephant Bird с открытым исходным кодом, поддерживающей RCFile. Также формат Record Columnar File используется в Taobao, Netflix, Yahoo, Linkedin, AOL, Salesforce.com и других крупных компаниях и ИТ-стартапах для хранения больших данных и аналитики Big Data [1].
Популярность колоночной структуры Record Columnar File послужила причиной появления других, более эффективных столбцовых форматов Big Data файлов: Apache ORC и Parquet, которые возникли в 2013 году и очень распространились среди реальных систем [2].
Источники
- https://en.wikipedia.org/wiki/RCFile
- https://www.computerra.ru/182389/petabytes-of-data-for-facebook/
- https://habr.com/ru/company/otus/blog/465069/