Что такое табличное хранилище Apache Flink, зачем это нужно и почему оно пока не рекомендуется для применения в реальных проектах. Краткий обзор Apache Flink Table Store 0.1.0 для дата-инженеров и разработчиков распределенных приложений.
Что такое Flink Table Store и зачем это нужно
Уже более полугода, с релиза 1.14, выпущенного в сентябре 2021 года, о котором мы писали здесь, Apache Flink объединяет пакетную обработку данных с потоковой, позволяя смешивать ограниченные и неограниченные потоки в приложении. Для работы этого универсального stateful-механизма используются специальные табличные хранилища (Table Store), которые еще находятся в стадии бета-тестирования и пока не рекомендуются для производственной среды.
Раньше приходилось разворачивать несколько разных систем хранения данных для Flink-приложений, например, очередь сообщений для потоковой обработки и сканируемая файловая система или объектное хранилище для пакетной обработки и специальных запросов, а также хранилище типа ключ/значение для поиска. Такая архитектура данных создает проблемы с их качеством и обслуживанием системы из-за сложности и неоднородности всей платформы. Это нарушает идею интегрированной потоковой передачи и пакетной обработки в Apache Flink.
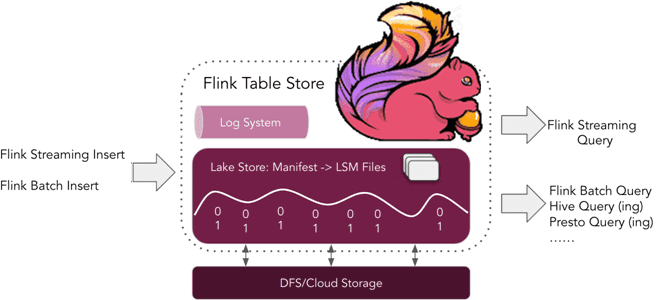
Чтобы решить эти проблемы, в Apache Flink появилось универсальное хранилище таблиц, которое расширяет возможности фреймворка и позволяет обеспечить сквозной опыт для пользователей. Flink Table Store стремится обеспечить унифицированную абстракцию хранилища, поэтому уже не нужно самостоятельно создавать множество различных хранилищ. Table Store — это унифицированное потоковое и пакетное хранилище для создания динамических таблиц Apache Flink. Оно предназначено для лучшего подключения к вычислительному движку Flink в качестве хранилища для потоковой передачи. Table Store использует полную структуру Log-Structured Merge-Tree (LSM) для высокой скорости и возможности обновления, а также запроса большого объема данных. Flink Table Store поддерживает следующие сценарии использования:
- потоковая вставка – запись потоков журнала изменений, включая CDC из базы данных и потоки;
- пакетная вставка – запись пакетных данных в виде автономного хранилища, включая поддержку перезаписи;
- пакетные OLAP-запросы – чтение моментального снимка хранилища, эффективный запрос данных в реальном времени;
- потоковый запрос – чтение изменений хранилища с однократной согласованностью.
Таким образом, Flink Table Store позволяет реализовать следующие потребности:
- использовать Flink для вставки данных в хранилище таблиц путем потоковой передачи журнала изменений, полученного из баз данных, или через пакетную загрузку из других хранилищ данных;
- использовать Flink для запросов к хранилищу таблиц различными способами, включая потоковые запросы и пакетные OLAP-запросы. Впрочем, пользователи могут использовать другие механизмы, например, Apache Hive, для SQL-запросов из хранилища таблиц.
Под капотом Table Store используется гибридная архитектура хранения на основе Lake Store для хранения исторических данных и систему очередей, интегрированную с Apache Kafka для хранения добавочных данных. Для гибридного потокового чтения предоставляются добавочные моментальные снимки. Внутренний Lake Store хранит данные в виде колоночных файлов в файловой системе или объектном хранилище и использует структуру LSM для поддержки большого количества обновлений данных и высокопроизводительных запросов. Некоторые идеи технической реализации этих подходов заимствованы из Apache Iceberg и RocksDB, которое является stateful-бэкендом для Flink по умолчанию, о чем мы писали здесь.
В будущем разработчики планируют добавить к Table Store поддержку движка Apache Hive, Trino, PrestoDB и Spark, а также реализовать сервисы для ускорения обновлений и повышения производительности запросов. О том, как это реализовано в выпуске 0.3, а также внутреннюю структуру файлов и каталогов, мы рассказываем в новой статье.
Как работать с табличным хранилищем: пара примеров
Чтобы понять, как работает табличное хранилище, рассмотрим несколько практических примеров. После обновления фреймворка с поддержкой Table Store можно создать динамическую таблицу, используя следующий DDL-запрос:
-- set root path to session config
SET 'table-store.path' = '/tmp/table_store';
-- create a word count dynamic table without 'connector' option
CREATE TABLE word_count (
word STRING PRIMARY KEY NOT ENFORCED,
cnt BIGINT
);
Запишем в динамическую таблицу данные:
-- create a word data generator table
CREATE TABLE word_table (
word STRING
) WITH (
'connector' = 'datagen',
'fields.word.length' = '1'
);
-- table store requires checkpoint interval in streaming mode
SET 'execution.checkpointing.interval' = '10 s';
-- write streaming data to dynamic table
INSERT INTO word_count SELECT word, COUNT(*) FROM word_table GROUP BY word;
Сделаем OLAP-запрос к этой таблице:
-- use tableau result mode SET 'sql-client.execution.result-mode' = 'tableau'; -- switch to batch mode RESET 'execution.checkpointing.interval'; SET 'execution.runtime-mode' = 'batch'; -- olap query the table SELECT * FROM word_count;
И, наконец, выполним потоковый запрос:
-- switch to streaming mode SET 'execution.runtime-mode' = 'streaming'; -- track the changes of table and calculate the count interval statistics SELECT `interval`, COUNT(*) AS interval_cnt FROM (SELECT cnt / 10000 AS `interval` FROM word_count) GROUP BY `interval`;
В потоковом режиме можно получить лог изменений динамической таблицы и произвести новые потоковые вычисления.
Как это все применять в практических кейсах использования Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Hadoop для инженеров данных
- Потоковая обработка в Apache Spark

