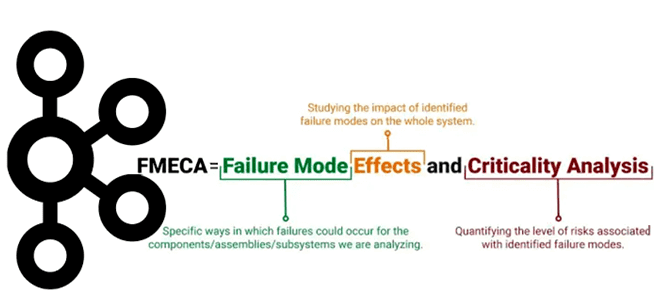
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...
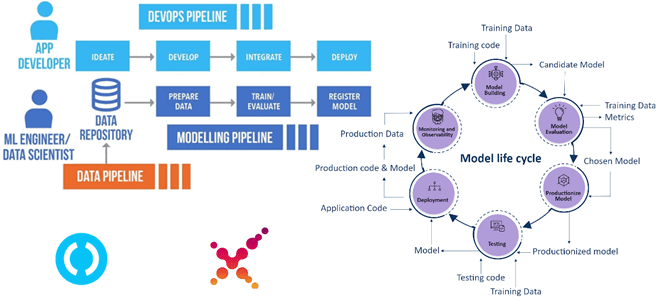
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим проблемы неконстистентности чтения из графовой СУБД Neo4j и способы их решения. Что такое bookmarks-механизм, как работает объект сеанса в Neo4j в кластерном режиме и при чем здесь драйверы. Зачем нужны закладки в Neo4j Драйверы графовой...
Мы уже писали про главные недостатки Apache NiFi как инструмента потоковой маршрутизации данных и организации ETL-процессов. Одним из них считается высокое потребление дискового пространства. Почему это случается и как с этим бороться: тонкости работы с потоковыми файлами на уровне жесткого диска - процессоры, очереди, сохранение и изменения FlowFile в Apache...
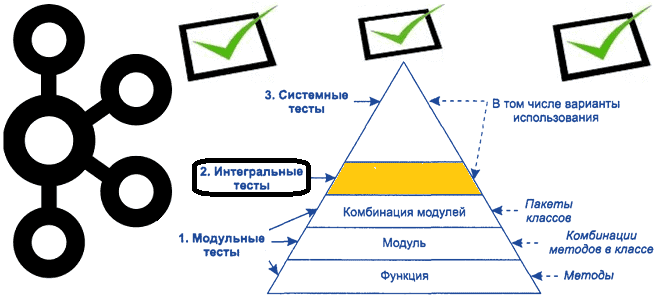
Продолжая важную для обучения разработчиков распределенных приложений и дата-инженеров тему про тестирование Big Data систем на базе Apache Kafka, сегодня рассмотрим некоторые средства для создания интеграционных тестов. Краткий ликбез по интеграционному тестированию приложений Apache Kafka В отличие от модульного тестирования, которое мы разбирали ранее, интеграционное тестирование сосредоточено на интерфейсах и потоке...
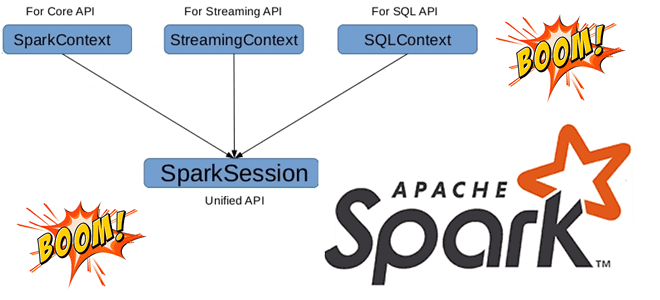
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...

Школа Больших Данных продолжает серию митапов по Apache Spark. Второй митап состоится 11 мая в 17:00 МСК по теме «Установка Apache Spark - это просто». Митап проводит специализированный учебный центр по технологиям Big data — Школа Больших данных. https://bigdataschool.ru За 2 часа митапа будет немного теории и много практики -...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...