1372
1372 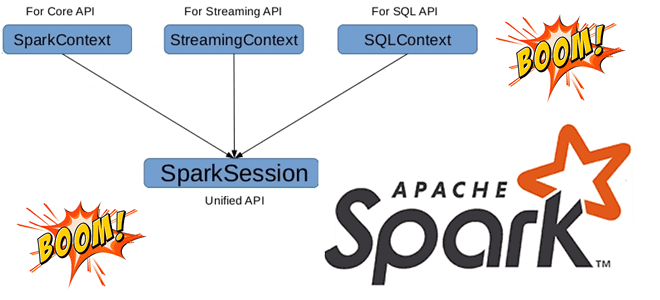
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого популярного фреймворка аналитики больших данных.
Как войти в Spark-приложение: SparkContext и SparkSession
До 2-ой версии Apache Spark точкой входа в распределенное приложение был объект SparkContext, который представлял собой соединение с кластером и мог использоваться для создания RDD и широковещательных переменных в этом кластере. В выпуске 2.0 была введена новая точка входа под названием SparkSession. Сеанс Spark является предпочтительным способом доступа к большинству функций фреймворка, поскольку основное внимание уделяется API высокого уровня, таким как SQL и DataFrame, и меньше — низкоуровневым RDD.
Несмотря на высокую популярность этого вычислительного движка для обработки и аналитики больших данных, при его использовании разработчику распределенного приложения и дата-инженеру стоит помнить о некоторых особенностях SparkContext и SparkSession. В частности, на первый взгляд кажется, что сеанс для всего приложения существует в количестве только одного экземпляра и нет никакой разницы, как получить указатель на этот объект. Например, можно использовать переменную spark или получить его из переменной DataFrame.
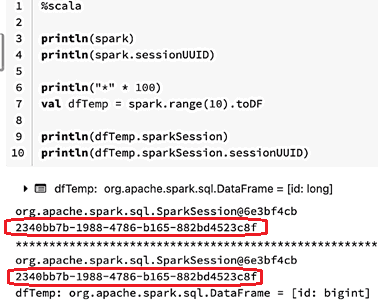
Эти несколько строк кода показали, что адрес переменной и свойство sessionUUID идентичны независимо от способа обращения к ним. Однако, на самом деле это не совсем идентичные вещи и столкнуться с этим можно в структурированной потоковой передаче Spark (Structured Streaming).
Чтобы продемонстрировать это, рассмотрим фрагмент Python-кода, который использует метод foreachBatch() для запуска пакетных операций с потоковым микропакетом. Напомним, метод foreachBatch() позволяет указать функцию, которая выполняется для выходных данных каждого микропакета потокового запроса. Начиная со релиза 2.4, он поддерживается в Scala, Java и Python. Метод принимает два параметра: DataFrame или Dataset, содержащий выходные данные микропакета, и уникальный идентификатор микропакета. Метод foreachBatch() пригодится для следующих сценариев:
- повторное использование существующих источников пакетных данных. Полезно, когда для систем хранения еще нет потокового приемника, но уже есть модуль записи данных для пакетных запросов. С foreachBatch() можно использовать средства записи пакетных данных на выходе каждого микропакета.
- запись результатов потокового запроса в несколько приемников за один раз, чтобы избежать ситуации, когда отдельная попытка записи может привести к пересчету выходных данных, включая повторное чтение входа. Чтобы избежать повторных вычислений, следует кэшировать выходной DataFrame или Dataset, записывать его в несколько мест, а затем распаковывать. Или же просто воспользоваться foreachBatch().
- Применение дополнительных операций DataFrame, которые изначально не поддерживаются потоковой передачей, поскольку фреймворк не поддерживает создание добавочных планов оптимизации запросов. С методом foreachBatch можно применить некоторые из этих операций к каждому выходному микропакету, самостоятельно позаботившись о сквозной семантике их выполнения.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
21 сентября, 2026
Продолжительность
20 ак.часов
Стоимость обучения
64 000
По умолчанию метод foreachBatch предоставляет только однократную гарантию записи. Но можно использовать пакетный идентификатор, предоставленный функции, для дедупликации вывода и получения гарантии ровно один раз. Наконец, foreachBatch не работает с режимом непрерывной обработки, т.к. основан на микропакетном выполнении потокового запроса. Для записи данных в непрерывном режиме подойдет метод foreach().
Возвращаясь к рассматриваемой проблеме, разберем фрагмент Python-кода, который использует метод foreachBatch() для запуска пакетных операций с потоковым микропакетом:
import org.apache.spark.sql.DataFrame
println(spark)
println(f"Spark session ID : ${spark.sessionUUID}")
println("*" * 100)
spark
.readStream
.format("rate")
.option("rowsPerSecond", 10)
.load()
.writeStream
.foreachBatch((df: DataFrame, batchId: Long) => {
println(df.sparkSession)
println(f"Session ID from streaming micro-batch DataFrame : ${df.sparkSession.sessionUUID}")
})
.start()
.awaitTermination()
Результат выполнения этого кода:
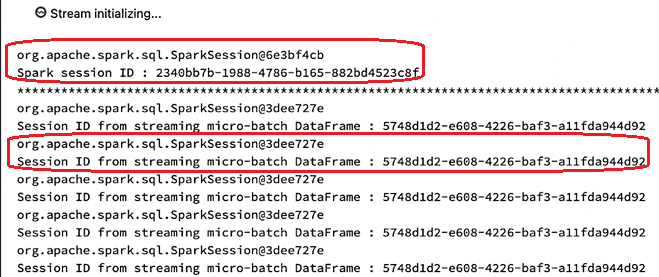
Адрес памяти сеанса и свойство UUID различаются между глобальной переменной spark и сеансом, подключенным к датафрейму микропакета. Это происходит из-за изоляции сеанса Spark для запуска пакетов в исходном коде фреймворка (версия 3.2.1) в файле StreamExecution.scala:
/** Isolated spark session to run the batches with. */
private val sparkSessionForStream = sparkSession.cloneSession()
В классе SparkSession есть метод cloneSession, который вызывается из одного места и представляет собой потоковый исполняемый файл. Клонирование здесь означает, что будет изолированный сеанс для кода SQL API, выполняющего код потоковой передачи. Этот сеанс унаследует состояние от корневого сеанса, но будет работать изолированно, чтобы обеспечить поведение, которое может отличаться от конфигурации корневого сеанса. В частности, благодаря этому адаптивное выполнение запросов может быть отключено для потоковой передачи:
// Adaptive execution can change num shuffle partitions, disallow sparkSessionForStream.conf.set(SQLConf.ADAPTIVE_EXECUTION_ENABLED.key, "false") // Disable cost-based join optimization as we do not want stateful operations // to be rearranged sparkSessionForStream.conf.set(SQLConf.CBO_ENABLED.key, "false")
Таким образом, для одного Spark-приложения может быть несколько сеансов, и каждый из них со своей конфигурацией. Это используется для API Spark Structured Streaming и возможно к применению в коде пользовательского приложения. Также есть два общедоступных API (newSession и cloneSession), которые позволяют создавать новый сеанс. Таким образом, несколько сеансов могут одновременно существовать в одном Spark-приложении, которое сопоставляется с одним SparkContext.
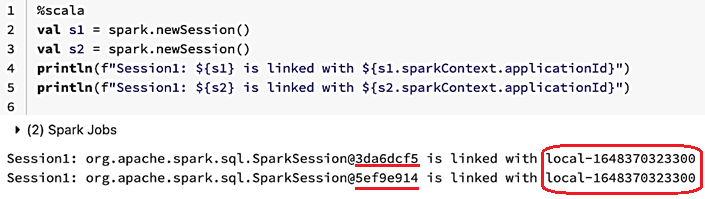
Два созданных сеанса имеют разные адреса памяти, но привязаны к одному и тому же SparkContext. Их по-прежнему можно использовать для создания фреймов данных, и в целом они будут вести себя аналогично корневому сеансу Spark, хотя при необходимости могут иметь другие параметры конфигурации.
Возвращаясь к обработке микропакетов в Structured Streaming, рассмотрим пример кода на PySpark:
def process_batch(df, batchId):
df.createOrReplaceTempView("microBatch")
count = df.sql_ctx.sparkSession.sql("select * from microBatch").count()
print(f"Count= {count} for batch: {batchId}")
(
spark
.readStream
.format("rate")
.option("rowsPerSecond", 100)
.load()
.writeStream
.foreachBatch(process_batch)
.trigger(processingTime='1 seconds')
.start()
.awaitTermination()
)
Запустив этот код на исполнение, можно столкнуться с ошибкой Table or view not found: microBatch. Это случается из-за отсутствия в PySpark атрибута sparkSession в экземпляре DataFrame до версии 3.2.1. Хотя в Spark Scala этот атрибут имеется. На первый взгляд, обойти это ограничение поможет свойство df.sql_ctx, но оно указывает на корневой сеанс. А поскольку временное представление microBatch зарегистрировано в сеансе потокового микропакета, оно не видно в корневом сеансе, где выполняется оператор SQL-запроса.
Самым простым решением для запуска операторов SQL в нужном сеансе Spark в рамках одного приложения — использовать глобальные временные представления. К представлению можно получить доступ из любого сеанса Spark, если его имя имеет префикс global_temp. в операторе SQL. Например, код может выглядеть так:
def process_batch(df, batchId):
df.createOrReplaceGlobalTempView("microBatch")
count = df.sql_ctx.sparkSession.sql("select * from global_temp.microBatch").count()
print(f"Count= {count} for batch: {batchId}")
(
spark
.readStream
.format("rate")
.option("rowsPerSecond", 100)
.load()
.writeStream
.foreachBatch(process_batch)
.trigger(processingTime='1 seconds')
.start()
.awaitTermination()
)
В этом варианте временное представление создается как глобальное: доступ к нему осуществляется с помощью корневого сеанса Spark с префиксом global_temp. На это направлено изменение в исходном коде фреймворка, опубликованное в феврале 2022 года. Оно содержит соответствующий рефакторинг исходного кода, чтобы реализовать DataFrame.sparkSession, как это делает Scala API, не полагаясь на внутренний устаревший SQLContext, который не учитывает правильно конфигурации времени выполнения сеанса. После установки этого изменения исходного кода следует обновить фреймворк и удалить зависимость от sql_ctx, чтобы не нужно использовать глобальные временные представления. Читайте в нашей новой статье, как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0. О том, как создавать объект сеанса Spark при запуске PySpark в интерактивной среде анализа и визуализации данных в Google Colab, смотрите здесь.
Узнайте больше про практическое использование Apache Spark и Hive для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
[elementor-template id=»13619″]
Источники